Introduction to Deep Learning
-- 170 Video Lectures from Adaptive Linear Neurons to Zero-shot Classification with Transformers
I just sat down this morning and organized all deep learning related videos I recorded in 2021. I am sure this will be a useful reference for my future self, but I am also hoping it might be useful for one or the other person out there.
PS: All code examples are in PyTorch :)
Part 1: Introduction
L01: Introduction to deep learning
L02: The brief history of deep learning
L03: Single-layer neural networks: The perceptron algorithm
Part 2: Mathematical and computational foundations
L04: Linear algebra and calculus for deep learning
L05: Parameter optimization with gradient descent
L06: Automatic differentiation with PyTorch
L07: Cluster and cloud computing resources
| Videos | Material | |
|---|---|---|
| 48 | 🎥 L7.0 GPU resources & Google Colab (19:17) | 📝 L07_cloud-computing_slides.pdf List of cloud resources: https://github.com/zszazi/Deep-learning-in-cloud |
| 49 | 🎥 Deep Learning News #4 (28:09) | 📝 stuff-in-the-news-04.pdf |
Part 3: Introduction to neural networks
L08: Multinomial logistic regression / Softmax regression
L09: Multilayer perceptrons and backpropration
L10: Regularization to avoid overfitting
L11: Input normalization and weight initialization
L12: Learning rates and advanced optimization algorithms
Part 4: Deep learning for computer vision and language modeling
L13: Introduction to convolutional neural networks
L14: Convolutional neural networks architectures
L15: Introduction to recurrent neural networks
Part 5: Deep generative models
L16: Autoencoders
L17: Variational autoencoders
L18: Introduction to generative adversarial networks
L19: Self-attention and transformer networks
Read Next
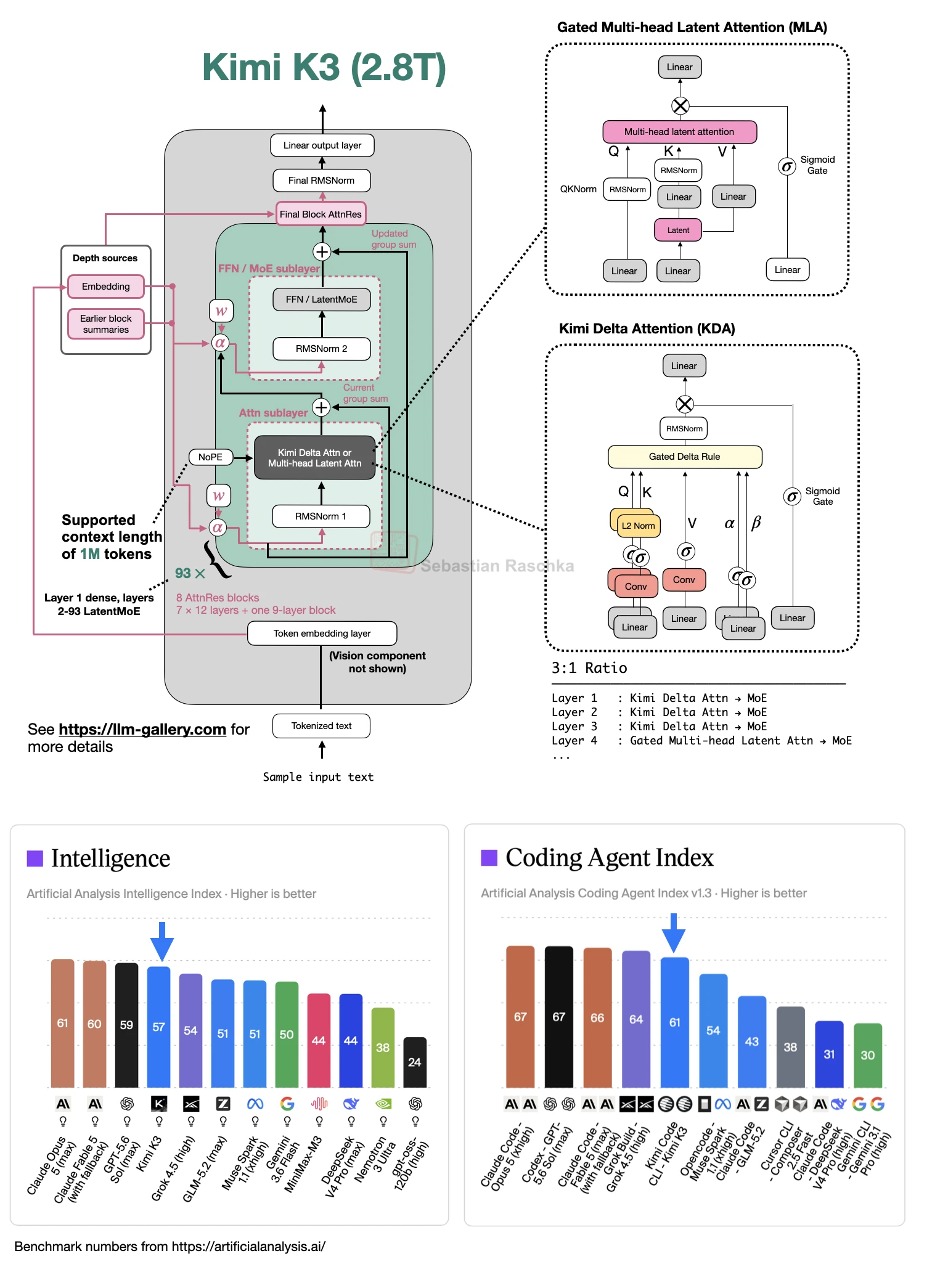 Kimi K3 Architecture Notes
Short architecture note on Kimi K3, including LatentMoE, Kimi Delta Attention, Attention Residuals, NoPE, multimodality, and inference-efficiency choices.
Kimi K3 Architecture Notes
Short architecture note on Kimi K3, including LatentMoE, Kimi Delta Attention, Attention Residuals, NoPE, multimodality, and inference-efficiency choices.
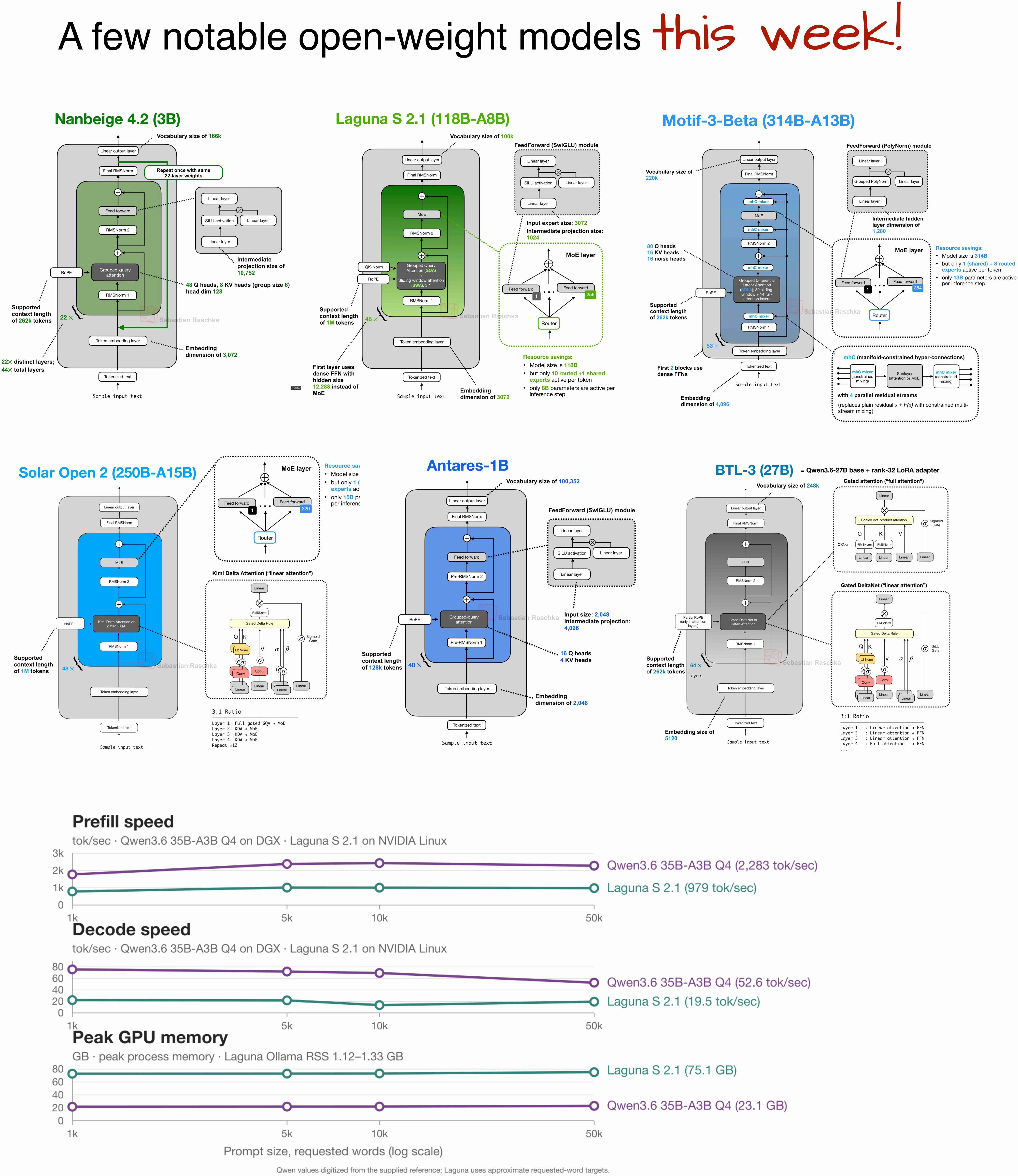 A Few Notable Open-Weight Models This Week
Short note on the architectures of six new open-weight models, including Nanbeige 4.2, Laguna S 2.1, Motif-3-Beta, Solar Open 2, Antares 1B, and BTL-3.
A Few Notable Open-Weight Models This Week
Short note on the architectures of six new open-weight models, including Nanbeige 4.2, Laguna S 2.1, Motif-3-Beta, Solar Open 2, Antares 1B, and BTL-3.
 Correction for Listing 6.5 in Build a Reasoning Model From Scratch
Short correction note for the random seed in Listing 6.5 on page 198 of Build a Reasoning Model From Scratch.
Correction for Listing 6.5 in Build a Reasoning Model From Scratch
Short correction note for the random seed in Listing 6.5 on page 198 of Build a Reasoning Model From Scratch.
This blog is a personal passion project. If you'd like to support my work, please consider my
Build a Large Language Model (From Scratch) book or its follow-up,
Build a Reasoning Model (From Scratch).
(I'm confident you'll get a lot out of these; they explain how LLMs work in depth you won't find elsewhere.)

Build a Large Language Model (From Scratch) is now available on
Amazon. Build a Reasoning Model (From Scratch) is in
Early Access at Manning.
If you read the book and have a few minutes to spare, I'd really appreciate a brief review. It helps us authors a lot!
Your support means a great deal! Thank you!