Talks and Events
I’m always open to event invitations—thank you for thinking of me! Please check out my Contact page for details.
Talks
From Scratch to Scale: Turning LLM Code into Architecture Insights
PyCon DE & PyData 2026 (upcoming), Darmstadt on April 14–16, 2026. Keynote at 10:30 am CEST (Germany time).

Python has been at the center of my work in machine learning and AI for more than a decade. It is where I start from scratch, experiment with ideas, and build systems that help me understand how large language models really work.
In this keynote, I will look at what it means to build and study LLMs in Python today. Starting from small, from-scratch implementations, I will show how Python and PyTorch help us understand modern model architectures, compare new designs against reference code, and learn details that papers often leave out. I will then connect those implementation lessons to current LLM trends, especially the push to reduce inference costs and KV-cache pressure as reasoning models and agentic workflows need longer contexts. At the end, I will also share a practical roadmap of libraries, open projects, and learning resources for going from first principles to real-world LLM development.
Conference website for more information: https://2026.pycon.de
[Slides]
The Building Blocks of Today’s and Tomorrow’s Large Language Models
Oct 23th, in San Francisco, CA at PyTorch Conference 2025.

In this talk, you’ll learn about the latest trends in large language model (LLM) architectures. We’ll look at how the architectural building blocks have evolved this year, with a focus on current transformer-based models (including Llama, GPT-OSS, Gemma, Qwen, and DeepSeek). The talk will also spotlight emerging non-transformer approaches that may signal what comes next for LLM research and development.
You can find more information about the talk on the PyTorch Conference 2025 website here).
Note: Due to a conflict, I had to reschedule my trip and will now be speaking on Oct 23 (11:00 am PDT, room 2022-2024) instead of Oct 22nd.
I’ll also be at the PyTorch Conference for a book signing. Come say hi between 3:20 and 3:50 pm PDT in the Expo Hall.
Recording of the talk:
Understanding LLMs: From Foundations to Reasoning Models
Jan 31st at the University of Michigan, Feb 3rd at Boston University, and Feb 20th at University of South Dakota

In this talk, we will explore the foundations of large language models (LLMs), from their core implementation and training processes to the key advancements that have reshaped the field in recent years. We’ll then connect these fundamentals to the latest breakthroughs in reasoning models, examining the four primary approaches used to develop and enhance their reasoning capabilities.
LLMs Then and Now: Navigating the Architectural Timeline of LLMs
Sep 19th, in San Francisco, CA at PyTorch Conference 2024.

In this talk, you’ll learn about the architectural difference between the original GPT model and the various Llama models. Moreover, you’ll also learn about new pre-training recipes used for Qwen 2, Gemma 2, Apple’s Foundation Models, and Llama 3, as well as some of the efficiency tweaks introduced by Mixtral, Llama 3, and Gemma 2.
You can find more information about the talk on the PyTorch Conference 2024 website here.
Pretraining and Finetuning LLMs from the Ground Up
July 8th, in Tacoma, WA at SciPy 2024.

This tutorial is aimed at coders interested in understanding the building blocks of large language models (LLMs), how LLMs work, and how to code them from the ground up in PyTorch. We will kick off this tutorial with an introduction to LLMs, recent milestones, and their use cases. Then, we will code a small GPT-like LLM, including its data input pipeline, core architecture components, and pretraining code ourselves. After understanding how everything fits together and how to pretrain an LLM, we will learn how to load pretrained weights and finetune LLMs using open-source libraries.
You can find more information about the talk on the SciPy 2024 website here.
Understanding the LLM Development Cycle: Building, Training, and Finetuning
June 5th, ACM Tech Talk.

This talk will guide you through the key stages of developing large language models (LLMs), from initial coding to deployment. We will start by explaining how these models are built, including the coding of their architectures. Next, we will discuss the processes of pre-training and finetuning, showing what these stages involve and why they are important. Throughout the talk, we will provide real examples and encourage questions, making this a practical and interactive session for anyone interested in how LLMs are created and used.
You can register for this virtual talk for free here.
The Fundamentals of Modern Deep Learning with PyTorch
May 15th, 2024 in Pitsburgh at the PyCon 2024.

I’ll be giving a 3.5 hour deep learning workshop at PyCon 2024 in May. This tutorial is aimed at Python
programmers new to PyTorch and deep learning. However, even more experienced deep learning practitioners and PyTorch users may be exposed to new concepts and ideas when exploring other open source libraries to extend PyTorch.
It’s my first PyCon, and I’m very excited!
LoRA in Action: Insights from Finetuning LLMs with Low-Rank Adaptation
Fri 14 Dec, 2023 in New Orleans at the NeurIPS 2023 Large Language Model Efficiency Challenge: 1 LLM + 1GPU + 1Day workshop.

Low-rank adaptation (LoRA) stands as one of the most popular and effective methods for efficiently training custom Large Language Models (LLMs). As practitioners of open-source LLMs, we regard LoRA as a crucial technique in our toolkit.
In this talk, I will delve into some practical insights gained from running hundreds of experiments with LoRA, addressing questions such as: How much can I save with quantized LoRA? Are Adam optimizers memory-intensive? Should we train for multiple epochs? How do we choose the LoRA rank?
Moreover, the talk will include ideas for future experiments and talking points to stimulate discussions in the workshop, such as mechanisms to avoid overfitting in LoRA and strategies for combining LoRA weights from multiple experiments.
Using Open-Source LLMs and Parameter-Efficient Finetuning Techniques
Fri 13 Oct, 2023 at Packt’s Put GenAI to Work virtual conference.

- This session will teach you how to utilize the latest open-source Large Language Models (LLMs), such as Falcon, Llama 2, and Code Llama, on your own GPU-supported hardware.
- We will also cover parameter-efficient finetuning techniques like low-rank adaptation (LoRA) and QLoRA to optimize these LLMs. Moreover, you will learn how to prepare and formate new datasets for finetuning these open-source models.
Finetuning Open-Source LLMs
Tue 3 Oct, 2023 at MLOps.community’s virtual LLMs in Production conference.

This conference keynote talk offers a quick dive into the world of finetuning Large Language Models (LLMs), covering
- common usage scenarios for pretrained LLMs
- parameter-efficient finetuning
- a hands-on guide to using the ‘Lit-GPT’ open-source repository for LLM finetuning
Introduction to Machine Learning and Deep Learning with Python
Mon 18 Sep, 2023 at posit::conf 2023 in Chicago.

This 8-hour workshop introduced participants to the machine and deep learning fundamentals using a modern open-source stack.
The first part started with a brief introduction to Python’s scientific computing libraries, including NumPy, Pandas, and Matplotlib, which provide the foundation for data analysis and visualization. From there, we dove into the scikit-learn API, a user-friendly, open-source library for machine learning in Python.
In the second part of this workshop, we covered deep learning concepts and introduced PyTorch, the most widely used deep learning research library. Next, we trained multi-layer neural networks efficiently using multi-GPU and mixed-precision techniques with Lightning Fabric. Finally, we will explored how to organize PyTorch code with PyTorch Lightning and finetune vision transformers and large language models.
LLMs for Everything and Everyone
Tue 5 Sep, 2023 at SDSC 2023 in Atlanta, Georgia.

This invited keynote talk covered the LLM training cycle, explaining how to train modern LLMs. The main portion of the talk was focused on how individuals with limited resources and big companies with larger budgets can use and customize LLMs.
In this talk, I also touched on the recent research advances and what to expect next for the next generation of LLMs.
Modern Deep Learning with PyTorch
Mon 10 Jul, 2023 at SciPy 2023 in Austin, Texas.

A 4-hour workshop at SciPy 2023 covering the following topics:
- Introduction to Deep Learning
- Understanding the PyTorch API
- Training Deep Neural Networks
- Accelerating PyTorch Model Training
- Organizing PyTorch Code
- More Tips and Techniques
- Finetuning LLMs
I have a GitHub repository with all the materials here and I believe it was recorded, so I hope it will be publicly available at some point!
Scaling PyTorch Model Training With Minimal Code Changes
Wed 21 Jun, 2023 in Vancouver at CVPR 2023.

In this tutorial, I will show you how to accelerate the training of LLMs and Vision Transformers with minimal code changes using open-source libraries. The code materials are available at https://github.com/rasbt/cvpr2023, and I also have a write-up of the talk here.
How To Triple Your Model’s Inference Speed
Febuary 2023, virtual event.

Webinar on tripling the inference speed of stable diffusion and other generative AI models.
Generative AI and Large Language Models
January, 2023, virtual event at the StateOfTheArt() conference.

StateOfTheArt() 2023 conference with me giving the opening keynote on generative AI and large language models with an open Q&A session.
Using Deep Learning When Class Labels Have A Natural Order – Predicting Ratings and Rankings using PyTorch Lightning July 2022 at SciPy 2022 in Austin, Texas. [Slides] [Code] [Recording]

Many real-world prediction problems come with ordered labels, for example, customer satisfaction (dissatisfied, neutral, satisfied), disease severity (none, moderate, severe), and many more. Sure, we can use conventional machine learning and deep learning classifier on such problems, but you will see why that’s not ideal. Moreover, you will learn how we can modify any deep neural network classifier such that it takes the ordering information into account – it requires changing less than five lines of code!
Introduction to PyTorch and Scaling PyTorch Code with LightningLite May 2022. Invited virtual talk at Data Umbrella [Slides] [Recording Part 1: PyTorch] [Recording Part 2: LightningLite] [Recording Part 3: Q&A]
This talk will introduce attendees to using PyTorch for deep learning. We will start by covering PyTorch from the ground up and learn how it can be both powerful and convenient. At times, Machine learning models can become so large that they can’t be trained on a notebook anymore. Being able to take advantage AI-optimized accelerators such as GPU or TPU and scaling the training of models to hundreds of these devices is essential to the researcher and data scientist. However, adding support for one or several of these in the source code can be complex, time consuming and error-prone. What starts as a fun research project ends up being an engineering problem with hard to debug code. This talk will introduce LightningLite, an open source library that removes this burden completely. You will learn how you can accelerate your PyTorch training script in just under ten lines of code to take advantage of multi-GPU, TPU, multi-node, mixed-precision training and more.
Customer Ratings, Letter Grades, and Other Rankings: Using Deep Learning When Class Labels Have A Natural Order
February 2022. Invited talk at ReWork Deep Learning Summit, San Francisco
[Slides] [Recording] [Alt. Recording]

Deep learning offers state-of-the-art results for classifying images and text. Common deep learning architectures and training procedures focus on predicting unordered categories, such as recognizing a positive and negative sentiment from written text or indicating whether images contain cats, dogs, or airplanes. However, in many real-world problems, we deal with prediction problems where the target variable has an intrinsic ordering. For example, think of customer ratings (e.g., 1 to 5 stars) or medical diagnoses (e.g., disease severity labels such as none, mild, moderate, and severe). This talk will describe the core concepts behind working with ordered class labels, so-called ordinal data. We will cover hands-on PyTorch examples showing how to take existing deep learning architectures for classification and outfit them with loss functions better suited for ordinal data while only making minimal changes to the core architecture.
Transformers from the Ground Up
August 2021. Invited talk at PyData Jeddah
[Slides] [Code] [Video]

In recent years deep learning-based transformer models have revolutionized natural language processing. First of all, this talk will explain how transformers work. Then, we will examine some popular transformers like GPT and BERT and understand how they differ. Equipped with this understanding, we will then take a look at how we can fine-tune a BERT model for sentiment classification in Python.
Introduction to Generative Adversarial Networks
July 2021. Invited lecture at the
International Summer School on Deep Learning, Gdansk
[Slides] [Code]

This lecture introduces the main concepts behind Generative Adversarial Networks (GANs) and explains the main ideas behind the objective function for optimizing the generator and discriminator subnetworks. Hands-on examples include GANs for handwrittten digit and face generation, implemented in PyTorch. Lastly, this talks summarizes some of the main milestone GAN architectures that emerged in recent years.
Designing Generative Adversarial Networks for Privacy-enhanced Face Recognition
July 2021. Invited keynote talk at the
14th International Conference on
Human System Interaction (HSI 2021)
[Slides] [Video]

After introducing the main concepts behind face recognition and soft-biometric attribute mining (i.e., the extraction of information such as age, gender, race, health information, and others), this talk discusses different methods for hiding soft-biometric information from facial recognition systems. After introducing the main methodologies, the talk focuses on the PrivacyNet architecture, which is a GAN-based approach to collective and selective facial privacy.
Modern Machine Learning: An Introduction to the Latest Techniques
April 2021. Invited talk at the Chan Zuckerberg Initiative’s
Seed Network Computational Biology conference.
[Slides]

This talk aims to introduce and explain the most relevant methods for predictive modeling with large and complicated data. The first part discusses the established and proven methods for image, text, and tabular data based on machine learning and deep learning. The second part surveys the most recent research directions and promising methods for building the next-generation of deep learning-based predictive models.
Machine Learning in Python: Recent Trends, Technologies, and Challenges
March 2021. Invited talk at ODSC East 2021.
[Slides]

The first part of this talk covers the recent advancement in hardware and software for deep learning. The second part focuses on the current challenges in deep learning as well as the recent research progress.
Machine Learning in Python: Recent Trends, Technologies, and Challenges
April 2020. Invited talk at the Port Harcourt School of AI in Nigeria.
[Slides]

This talk focuses on the recent trends in machine learning, including hardware and software. A particular focus is on the Python scientific computing ecosystem and contemporary deep learning libraries.
Machine Learning and Artificial Intelligence in 2020: Recent Trends, Technologies, and Challenges March 2020. Invited talk at ODSC East 2020 in Boston. [Slides]

Not even a decade ago, machine learning was a profession for an elite few. Nowadays, we don’t have to be math or engineering wizards to implement state-of-the-art predictive models. Advances in computing hardware, and especially the utilization of GPUs for training deep neural networks, make it feasible to develop predictive models that achieve human-level performance in various natural language processing and image recognition challenges. The manifold software layers and APIs that are allowing us to utilize these hardware resources are becoming ever so convenient. In this talk, I will highlight the research and technology advances and trends of the last year(s), concerning GPU-accelerated machine learning and deep learning, and focusing on the most profound hardware and software paradigms that have enabled it.
Machine-Learning & AI-based Approaches for GPCR Bioactive Ligand Discovery September 2019. Invited talk at the Cambridge Healthtech Institute’s 14th Annual GPCR-Based Drug Discovery — Discovery on Target Conference, Boston, MA. [Slides]

This talk provides an overview of the latest advances for automating the discovery of bioactive ligands using machine learning. Specific applications are covering the discovery of a strong GPCR pheromone inhibitor as well as predictive models utilizing flexible and rigid rigid states of GPCRs to predict wether GPCR are in active and inactives states. Lastly, the talk concludes with the recent developments in deep learning that are aimed at replacing the need for hand-engineering molecular representations by automatic representation learning using deep learning techniques.
Convolutional Neural Networks for Predicting and Hiding Personal Traits from Face Images. July 2019. Keynote talk at the International Summer School on Deep Learning, Poland, Gdansk. [Slides]
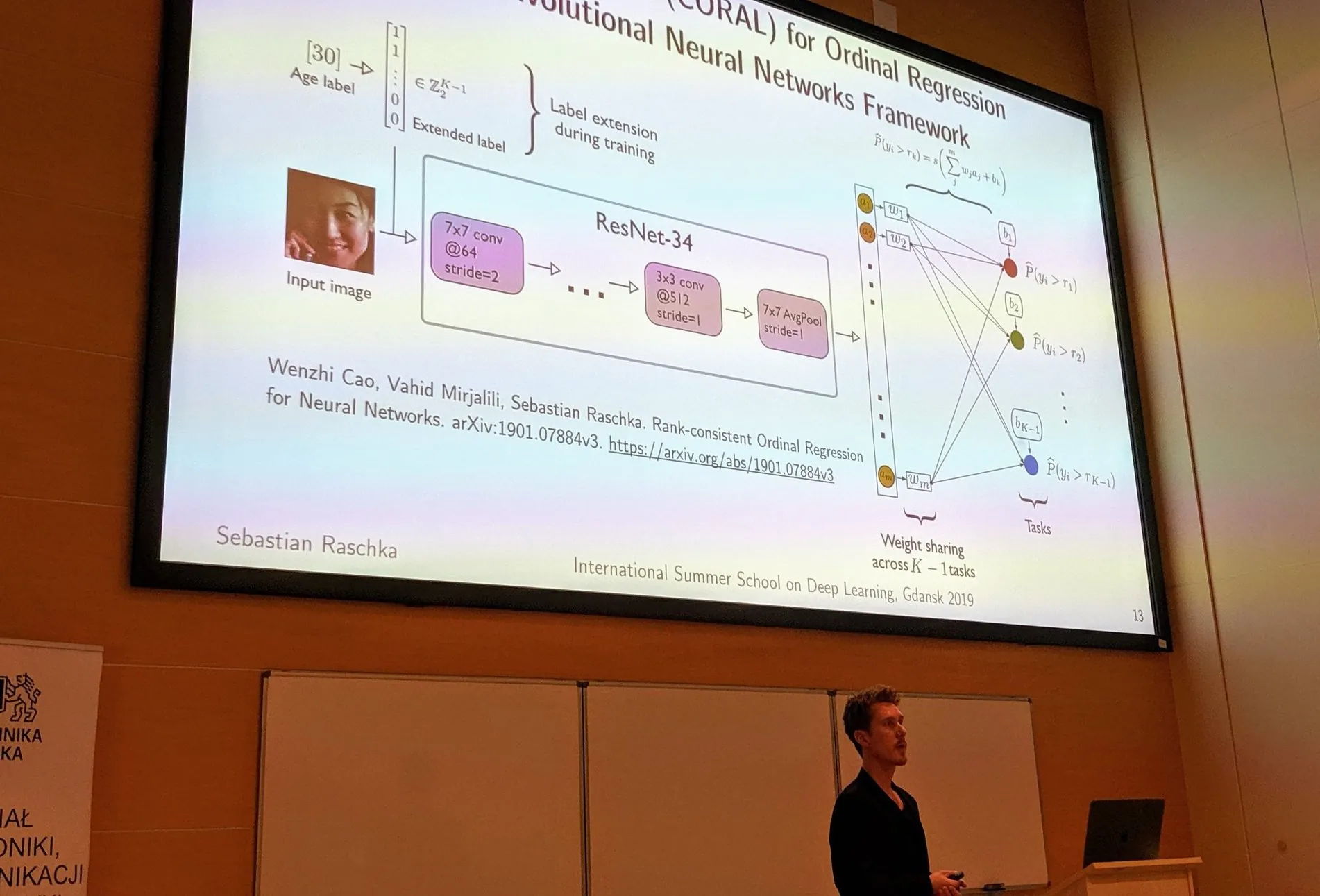
In this talk, I present In recent years, we have developed many July 2019. Deep Learning-centric applications that enhance our everyday life. However, as more and more data is collected and extracted, the protection and respect for users’ privacy have become a big concern. First, this talk will introduce methods for extracting soft-biometric attributes from facial images – soft-biometric characteristics include a person’s age, gender, race, and health status. Then, I will cover methods designed to conceal soft-biometric information to enhance the privacy of users. However, many useful security-related applications rely on face recognition technology for user verification and authentication. Hence, the approaches being presented focus on a dual objective: concealing personal information that can be obtained from face images while preserving the utility of these images for face matching.
Imparting privacy to face images: designing semi-adversarial neural networks for multi-objective optimization tasks April 2018. Invited talk at the TomTom Fest-sponsored Applied Machine Learning Conference. VA, Charlottesville. [Slides]

In this talk, I present a novel neural network architecture, semi-adversarial neural networks that we developed to minimize the performance of once classifier while maximizing the performance of another. This approach is then applied to perturb face images in such as way that biometric face matching is minimally impacted while soft biometric attributes (e.g., gender information) becomes inaccessible as a means to impart privacy to face images.
Machine Learning with Python February 2018. Invited workshop talk at MSU Data Science, East Lansing, MI. [Slides]

This workshop provides an introduction to machine learning covering important concepts regarding regression analysis, classification, and model evaluation as well as the tools being used to conduct experiments. Tool-wise, the focus is on Python’s scikit-learn machine learning library, but TensorFlow and PyTorch are being introduced as well.
Uncovering Hidden Patterns of Molecular Recognition December 2017. Thesis talk at Michigan State University. East Lansing, MI. [Slides]

It happened in 1958 that John Kendrew’s group determined the three-dimensional structure of myoglobin at a resolution of 6 Å. This first view of a protein fold was a breakthrough at that time. Now, more than half a century later, both experimental and computational techniques have substantially improved as well as our understanding of how proteins and ligands interact. Yet, there are many unanswered questions to be addressed and patterns to be uncovered. This talk discusses the analysis of a large dataset of non-homologous proteins bound to their biological ligands, to test a hypothesis that arose from observations made throughout different inhibitor discovery projects: “proteins favor donating H-bonds to ligands and avoid using groups with both H-bond donor and acceptor capacity.”
Building hypothesis-driven virtual screening pipelines for millions of molecules November 2017. Invited talk at ODSC West. San Francisco, CA. [Slides]

In this talk, I will introduce a novel, hypothesis-driven filtering strategy and open-source toolkit for virtual screening, Screenlamp, which I developed and successfully applied to a identify potent inhibitors of G-protein coupled receptor-mediated signaling in vertebrates. And going beyond the mere identification of potent protein inhibitors, I will talk about techniques to integrate the computational predictions with experimental knowledge. Leveraging experimental data, supervised feature selection and extraction techniques will be introduced to identify the discriminants of biological activity using open-source machine learning libraries such as scikit-learn.
An Introduction to Deep Learning with TensorFlow August 2017. Invited talk at PyData Ann Arbor. Ann Arbor, MI. [Slides]

A talk about representing mathematical functions as computation graphs, computing derivatives, and implementing complex deep neural networks conveniently and efficiently using TensorFlow.
Machine Learning and Performance Evaluation November 2016. Invited talk at DataPhilly. Philadelphia, PA. [Slides]

Every day in scientific research and business applications, we rely on statistics and machine learning as support tools for predictive modeling. To satisfy our desire to model uncertainty, to predict trends, and to predict patterns that may occur in the future, we developed a vast library of tools for decision making. In other words, we learned to take advantage of computers to replicate the real world, making intuitive decisions more quantitative, labeling unlabeled data, predicting trends, and ultimately trying to predict the future. Now, whether we are applying predictive modeling techniques to our research or business problems, we want to make “good” predictions!
Detecting the Native Ligand Orientation by Interfacial Rigidity October 2016. Invited Talk at the BMB Department Retreat 2016. East Lansing, MI. [Slides]
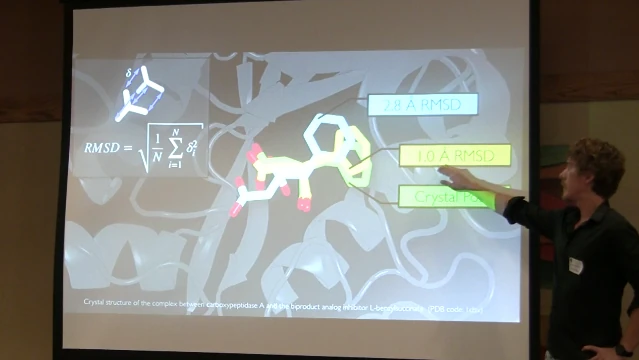
Presenting our novel novel approach to protein-ligand docking mode prediction based on graph theory.
Getting Started With Data Science September 2016. Inivited talk at Michigan State Data Science. East Lansing, MI. [Slides]
 Introduction to data science at our new MSU data science club.
Introduction to data science at our new MSU data science club.
Learning Scikit-learn – An Introduction to Machine Learning in Python August 2016. Inivited talk at PyData Chigaco 2016. Chicago, IL. [Video]
 Introduction to machine learning at PyData Chicago.
Introduction to machine learning at PyData Chicago.
Machine Learning with Scikit-learn July 2016. Machine learning workshop at SciPy 2016. Austin, TX. [Course material]

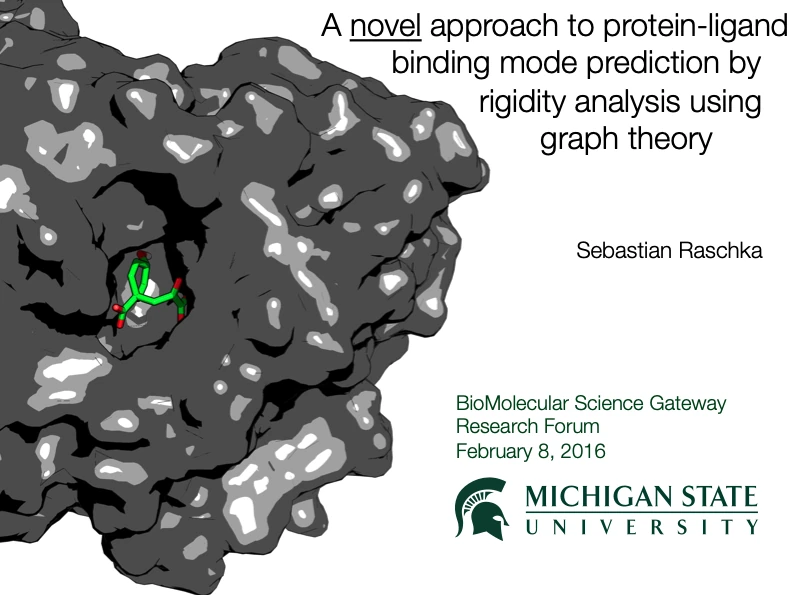
A Novel Approach to Protein-Ligand Binding Mode Prediction by Rigidity Analysis Using Graph Theory.
February 2015. BioMolecular Sciences Gateway. East Lansing, MI.
[Slides]
An Introduction to Supervised Machine Learning and Pattern Classification: The Big Picture February 2015. ICER NextGen Bioinformatics Seminars at MSU. East Lansing, MI. [Slides]

MusicMood - Machine Learning for Automatic Music Mood Prediction Based on Song Lyrics
December 2014. PSA Group Seminars. East Lansing, MI.
[Slides]

Podcasts
2026
04/13/2026 LLM Architecture in 2026: What You Need to Know with Sebastian Raschka – Vanishing Gradients podcast with Hugo Bowne-Anderson. (YouTube / Spotify / Apple Podcasts)
02/26/2026 AI Trends 2026: OpenClaw Agents, Reasoning LLMs, and More – The TWIML AI Podcast with Sam Charrington. (YouTube / Spotify / Apple Podcasts)
02/23/2026 LLMs in 2026: What’s Real, What’s Hype, and What’s Coming Next – Info-Tech Research Group. (YouTube / Spotify / Apple Podcasts)
02/01/2026 State of AI 2026 with Sebastian Raschka, Nathan Lambert, and Lex Fridman — Lex Fridman podcast. (YouTube / Lex Fridman podcast)

01/29/2026 State of LLMs 2026: RLVR, GRPO, Inference Scaling — MAD podcast with Matt Turck. (YouTube / Spotify / Apple Podcasts)

2025
03/07/2025 Fireside chat with Sebastian Raschka (via Patrick Rotzetter)
2024
11/21/2024 Build LLMs From Scratch with Sebastian Raschka #52 with Neil Leiser from AI Stories. (Apple Podcasts / Spotify / YouTube)

08/01/2024 On the state of open LLMs, Llama 3.1, and AI education with Nathan Lambert from Interconnects.ai.

05/07/2024. Episode 26: Developing and Training LLMs From Scratch on the Vanishing Gradients podcast with Hugo Bowne-Anderson (Website, Apple Podcasts, Spotify, Stitcher Radio or Overcast). There’s also a YouTube video version here.

03/19/2024. SDS 767: Open-Source LLM Libraries and Techniques, with Dr. Sebastian Raschka on the SuperDataScience podcast with Jon Krohn (Website, Apple Podcasts, Spotify, Stitcher Radio or TuneIn).

03/14/2024. 34 - LLMs and Python with Sebastian Raschka on The Python Show with Mike Driscoll. (Spotify, Substack, Apple Podcasts).
02/07/2024. Leading With Data Ep 22, talking about LLMs, training them from scratch, developing platforms for running experiments, and more!
2023
07/28/2023. Machine Learning Q and AI author interview with Sebastian Raschka
04/13/2023. Interview on large language models (LLMs) on the Soul Searching podcast by Ryan Dsouza.
02/15/2023. Learning from Machine Learning with Seth Levine.
01/30/2023. Infinite Machine Learning with Prateek Yoshi.

2022
The Data Exchange with Ben Lorica [YouTube] [Apple Podcasts] [Spotify]

The Gradient with Daniel Bashir
How AI Happens with Rob Stevenson [Apple Podcasts] [Spotify]
The Machine Learning Podcast with Jay Shah – Making Machine Learning More Accessible [YouTube]
The TWIML AI Podcast with Sam Charrington – Advancing Hands-On Machine Learning Education with Sebastian Raschka [YouTube]
Before 2022
Deep Tech Musings – #4 Drug Discovery Using ML and AI
The African Data Scientist – #6 - Dr Sebastian Raschka on how Africa can thrive in the age of AI and Data Science, AI and Data Science in the African educational ecosystem, how to write a good book on Machine Learning!
Podcast.__init__ – Teaching Python Machine Learning - Episode 260 (Apr 2020)
Chai Time Data Science – Statistics, Open Source & ML Research, Python for ML, Interview with Sebastian Raschka (Mar 2020) – [Audio] [Video]
- Data Framed – Biology and Deep Learning by DataCamp
- Partially Derivative – Model Evaluation with Sebastian Raschka
- Data Science at Home – 30 min with data scientist Sebastian Raschka
- Becoming a Data Scientist Podcast: Episode 08 - Sebastian Raschka
- […]
Panels
Open-Source LLMs
Sep 2023. Southern Data Science Conference. Atlanta, Georgia
In this panel, I discussed the role and future of open-source LLMs with co-panelist Paige Bailey from Google DeepMind.

Does Numerical Computing Have An Open Future
July 2022. Anaconda Conference. Austin, Texas.
Was honored to be invited to the open-source and numerical computing panel at Anaconda’s 10 year anniversary event alongside Travis Oliphant, Paige Bailey, and Ryan Abernathy!
[🎥 Video recording on YouTube]

Beyond Large Language Models
June 2022. Lightning DevCon. NYC, New York.
It was a pleasure moderating the research panel on the future of deep learning (beyond large language models) featuring Kyunghyun Cho, Soumith Chintala, and Danqi Chen.

Interviews
- Reddit AMA in r/MachineLearning on March 4, 2022
- How to use the power of the community to learn faster by Radek Osmulski
- New Faculty Focus: Sebastian Raschka – He brings an interest in machine learning to the Department of Statistics via UW-Madison College of Letters & Science
- Python Interviews: Discussions with prolific programmers, book edited by Mike Driscoll
- Quora Session Oct 2016
- AMA at Analytics Vidhya
- Data Preparation Tips, Tricks, and Tools: An Interview with the Insiders, interview via KDnuggets
- “Machine Learning can be useful in almost every problem domain:” An interview with Sebastian Raschka (Sep 2017) via Packt Publishing
- How Python rose to the top of the data science world (Aug 2017), via Computer Business Reviews
- The Future of Machine Learning and Data Science (Aug 2017), via Computer Business Reviews
- Why is Python so good for AI and Machine Learning? 5 Python Experts Explain (Mar 2018) via Packt DataHub
Commentaries, Guest Posts, and Other Articles
2025
- DeepSeek Founders Are Worth $1 Billion or $150 Billion Depending Who You Ask on Bloomberg, 10 Feb, 2025
2023
-
Why Developers Are Flocking to LLaMA, Meta’s Open Source LLM in The New Stack, 5 May, 2023
- ChatGPT detection tool thinks Macbeth was generated by AI. What happens now? in VentureBeat, 01 Feb, 2023
- Así son las empresas fantasma que evitan que ChatGPT o tu Roomba se descontrolen in El Confidencial, 28 Jan, 2023
Before 2023
- Advancing machine learning while protecting privacy in Wisconsin State Journal, May 2019
- Machine Learning & Artificial Intelligence: Main Developments in 2017 and Key Trends in 2018 via KDnuggets
- The Impact of Machine Learning on Healthcare via The Huffington Post
- Learning Machine Learning in 10 Days via KDnuggets
- If You’re New To Machine Learning, Be Choosy About What You Read via Forbes
- There’s Never Been A Better Time To Get Into Machine Learning via Forbes
- Everyone is talking about deep learning these days, but what the heck is it? Sebastian Raschka shows us how deep learning differs from machine learning in this 3-pager, featured in monthly Hacker Bits print magazine
- Trifecta: Python, Machine Learning, + Dueling Languages, guest post via Open Data Science
- What is Softmax Regression and How is it Related to Logistic Regression?, guest post via KDnuggets
- A Concise Overview of Standard Model-fitting Methods, guest post via KDnuggets
- A Visual Explanation of the Back Propagation Algorithm for Neural Networks, guest post via KDnuggets
- How to Select Support Vector Machine Kernels, guest post via KDnuggets
- The Difference Between Deep Learning and Regular Machine Learning, guest post via KDnuggets
- Why Implement Machine Learning Algorithms From Scratch?, guest post via KDnuggets
- The Development of Classification as a Learning Machine, guest post via KDnuggets
- When Does Deep Learning Work Better Than SVMs or Random Forests?, guest post via KDnuggets
- How to Explain Machine Learning to a Software Engineer, guest post via KDnuggets
- Regularization in Logistic Regression: Better Fit and Better Generalization?, guest post via KDnuggets
- “What is Softmax regression and how is it related to Logistic regression?” translated into Chinese
- […]
Mentions
2023
- 3 AI Research Content Creators Reveal Their Work Process on July 28, 2023 by Deci.ai
- Why detecting AI-generated text is so difficult (and what to do about it) by MIT Tech Review
Before 2023
- 6 Books Machine Learning Engineers Should Read by Data Driven Investor
- 100+ Handpicked AI And Machine Learning Blogs & Communities via https://www.theinsaneapp.com
- The 51 Best Python Books to Consider Reading Right Now via Business Intelligence Solutions Review
- Nothing artificial here: 30 AI experts to follow on Twitter via TechBeacon
- The 100 Most Influential People In AI – 2021 Edition via AI Newsletter
- Rocket your Machine Learning practice with this book by Jaime Zornoza
- Python Machine Learning: A Comprehensive Handbook for Machine Learning, via Analytics Vidhya
- Top 20 AI Influencers on Twitter (April 20), via theawardsmagazine.com
- Best Python Book of The Month via pythonbooks.org
- 50 Most Popular AI-Influencers of North America 2019 via AIthority
- The 2018 InfoQ Editors’ Recommended Reading List: Part Two via InfoQ
- List of Deep Learning Books to Read via MarkTechPost
- The 10 best books about A.I. via Big Think
- Top Influential Developers in AI via Onanalytica
- The Best Data Science Books of All-time via Book Scrolling
- 73 Best Tensorflow Books of All Time via Bookauthority
- Book Review Python Machine Learning - Second Edition via InfoQ
- Introduction to Market Basket Analysis in Python
- On state of contemporary machine Learning research, via DIGIMAG 76 - SPRING 2017
- Recapping SciPy 2017
- Jupyter Digest: April 2017 via O’Reilly
- How to choose a great Data Science book via Open Data Science
- 50 of the Best Data Science Blogs via Springboard
- ACM Computing Reviews’ Notable Computing Books and Articles of 2016
- Top 2016 KDnuggets Stories
- Popular Data Science Books Every Data Scientist Must Read by DeZyre
- Top 22 Python Programming Books via A.I. & Optimization
- Machine Learning Top 10 Articles For The Past Month [Oct 2016]
- Top 10 Essential Books for the Data Enthusiast, via KDnuggets
- 7 Must Read Python Books, by William P. Ross
- Artificial Intelligence: Experts To Follow on Twitter via techopedia
- 5 Machine Learning Projects You Can No Longer Overlook via KDnuggets
- 10 Big Data Books To Boost Your Career via InformationWeek
- 15 GitHub Repositories for Data Scientists via Ciencia e Dados - Data Science for Professionals
- Top 10 IPython Notebook Tutorials for Data Science and Machine Learning via KDnuggets News
- 50 Data leaders to follow on Twitter via DATAwerq
- Publisher’s picks: 29 open source books for 2015 via opensource.com
- Top 20 Python Machine Learning Open Source Projects via KDnuggets
- Artificial Intelligence & Machine Learning: Top 100 Influencers and Brands via onalytica
- Amazon Top 20 Books in AI & Machine Learning, via KDnuggets
- 4 Great Machine Learning eBooks via Data Science Central
- Book Review: Python Machine Learning by Sebastian Raschka by Alex Turner at WhatPixel
- A review of “Python Machine Learning” via BCS - The Chartered Institute for IT
- Top Data Scientists to Follow & Best Data Science Tutorials on GitHub via Analytics Vidhya
- The Case for Machine Learning in Business by Matthew Mayo at KDnuggets
- 11 IPython Tutorials for Data Science and Machine Learning via Data Science Central
- […]