LLM Architecture Gallery
A curated reference for modern language-model architectures
Compare architecture diagrams, implementation links, release dates, attention mechanisms, decoder types, and compact fact sheets without digging through individual posts.
The gallery focuses on text-only LLMs and language-model backbones. For multimodal releases, cards usually describe the text decoder/backbone rather than every vision, audio, or image-generation component.
Corrections are welcome in the issue tracker. If the latest changes are missing, try a hard reload (macOS: Command + Shift + R; Windows: Ctrl + F5).
Poster and print-ready download
Several readers asked for a way to support this project, so the gallery is now available as a physical poster on Redbubble and, upon request, as a print-ready digital download on Gumroad. I ordered the Redbubble print to check the quality; the photo shows the Medium size (26.9 x 23.4 in).
Architecture diff tool
Select two models to compare their architectures
If you want to compare two architectures side by side instead of browsing the gallery, use this diff tool.
You can use the selectors here or the Model A / Model B actions on each card.
No models match this search.
GPT-2 XL (1.5B)
Late-2019 dense baseline included here as a reference point for how much decoder stacks have changed since GPT-2.
- Scale
- 1.5B parameters
- Context (tokens)
- 1,024
- License
- OpenAI "Modified MIT" license
- Date
- 2019-11-05
- Decoder type
- Dense
- Attention
- MHA with learned absolute positional embeddings
- Layer mix
- 48 MHA
- KV cache / token (bf16) info
- 300 KiB · High
- Key detail
- Classic GPT-2 recipe with dropout, GELU, LayerNorm, and full multi-head attention.
Related concepts
Compare
Llama 3 (8B)
Reference dense Llama stack used to contrast OLMo 2's normalization and attention choices.
- Scale
- 8B parameters
- Context (tokens)
- 8,192
- License
- Llama 3 Community License Agreement
- Date
- 2024-04-18
- Decoder type
- Dense
- Attention
- GQA with RoPE
- Layer mix
- 32 GQA
- KV cache / token (bf16) info
- 128 KiB · Moderate
- Key detail
- Pre-norm baseline; wider than OLMo 2 at a similar scale.
Compare
Llama 3.2 (1B)
Small dense Llama baseline in the Qwen comparison, with fewer layers but more width.
- Scale
- 1B parameters
- Context (tokens)
- 128,000
- License
- Llama Community License Agreement (variant-specific)
- Date
- 2024-09-25
- Decoder type
- Dense
- Attention
- GQA
- Layer mix
- 16 GQA
- KV cache / token (bf16) info
- 32 KiB · Low
- Key detail
- Wider architecture with more heads than Qwen3 0.6B.
Compare
OLMo 2 (7B)
Transparent dense model that keeps classic MHA and pushes normalization changes for training stability.
- Scale
- 7B parameters
- Context (tokens)
- 4,096
- License
- Apache License 2.0
- Date
- 2024-11-25
- Decoder type
- Dense
- Attention
- MHA with QK-Norm
- Layer mix
- 32 MHA
- KV cache / token (bf16) info
- 512 KiB · Very high
- Key detail
- Uses inside-residual post-norm instead of the usual pre-norm layout.
Compare
DeepSeek V3 (671B)
DeepSeek's flagship template kicked off the recent wave of large open MoE models.
- Scale
- 671B total, 37B active (5.5% active)
- Context (tokens)
- 128,000
- License
- DeepSeek License Agreement v1.0
- Date
- 2024-12-26
- Decoder type
- Sparse MoE
- Attention
- MLA
- Layer mix
- 61 MLA
- KV cache / token (bf16) info
- 68.6 KiB · Low
- Key detail
- Uses a dense prefix, shared expert, and MTP-1 objective to keep a very large model practical.
Compare
DeepSeek R1 (671B)
Reasoning-tuned DeepSeek model built on the V3 architecture rather than a new base design.
- Scale
- 671B total, 37B active (5.5% active)
- Context (tokens)
- 128,000
- License
- MIT License
- Date
- 2025-01-20
- Decoder type
- Sparse MoE
- Attention
- MLA
- Layer mix
- 61 MLA
- KV cache / token (bf16) info
- 68.6 KiB · Low
- Key detail
- Architecture matches DeepSeek V3, including the MTP-1 path; the main change is the reasoning-oriented training recipe.
Compare
Gemma 3 (27B)
Gemma's flagship text stack leans on local attention more aggressively than Gemma 2.
- Scale
- 27B parameters
- Context (tokens)
- 128,000
- Vocabulary
- 262,144 (~262k)
- License
- Gemma Terms of Use + Gemma Prohibited Use Policy
- Date
- 2025-03-11
- Decoder type
- Dense
- Attention
- GQA with QK-Norm and 5:1 sliding-window/global attention
- Layer mix
- 52 sliding-window + 10 global
- KV cache / token (bf16) info
- 496 KiB · Very high
- Key detail
- Built around a 27B sweet spot with heavier local attention and a large 262k multilingual vocabulary.
Compare
Mistral Small 3.1 (24B)
Fast dense 24B model that drops the sliding-window setup used in older Mistral releases.
- Scale
- 24B parameters
- Context (tokens)
- 128,000
- License
- Apache License 2.0
- Date
- 2025-03-18
- Decoder type
- Dense
- Attention
- Standard GQA
- Layer mix
- 40 GQA
- KV cache / token (bf16) info
- 160 KiB · Moderate
- Key detail
- Latency-focused design with a smaller KV cache and fewer layers than Gemma 3 27B.
Compare
Llama 4 Maverick (400B)
Meta's large MoE follows the DeepSeek V3 playbook but with a more conventional attention stack.
- Scale
- 400B total, 17B active (4.3% active)
- Context (tokens)
- 1,000,000
- License
- Llama 4 Community License Agreement
- Date
- 2025-04-05
- Decoder type
- Sparse MoE
- Attention
- GQA
- Layer mix
- 36 chunked + 12 full GQA
- KV cache / token (bf16) info
- 192 KiB · High
- Key detail
- Alternates dense and MoE blocks and uses fewer, larger experts than DeepSeek V3.
Compare
Qwen3 (0.6B)
Tiny current-generation Qwen model that trades width for more depth and a low memory footprint.
- Scale
- 0.6B parameters
- Context (tokens)
- 32,768
- License
- Apache License 2.0
- Date
- 2025-04-28
- Decoder type
- Dense
- Attention
- GQA
- Layer mix
- 28 GQA
- KV cache / token (bf16) info
- 112 KiB · Moderate
- Key detail
- Deeper than Llama 3.2 1B and unusually practical for local experiments and teaching.
Compare
Qwen3 (235B-A22B)
Large sparse Qwen variant that stays very close to DeepSeek V3 while removing the shared expert.
- Scale
- 235B total, 22B active (9.4% active)
- Context (tokens)
- 128,000
- License
- Apache License 2.0
- Date
- 2025-04-28
- Decoder type
- Sparse MoE
- Attention
- GQA with QK-Norm
- Layer mix
- 94 GQA
- KV cache / token (bf16) info
- 188 KiB · High
- Key detail
- High-capacity MoE design optimized for serving efficiency without a shared expert.
Compare
Qwen3 (30B-A3B)
Small sparse Qwen3 model that sits close to GPT-OSS in active size but uses a deeper stack.
- Scale
- 30B total, 3B active (10% active)
- Context (tokens)
- 128,000
- License
- Apache License 2.0
- Date
- 2025-04-28
- Decoder type
- Sparse MoE
- Attention
- GQA
- Layer mix
- 48 GQA
- KV cache / token (bf16) info
- 96 KiB · Moderate
- Key detail
- Deeper, narrower MoE alternative to GPT-OSS without a shared expert.
Compare
Qwen3 (32B)
Large dense Qwen3 model that serves as the clearest like-for-like comparison for OLMo 3 32B.
- Scale
- 32B parameters
- Context (tokens)
- 128,000
- License
- Apache License 2.0
- Date
- 2025-04-28
- Decoder type
- Dense
- Attention
- GQA with QK-Norm
- Layer mix
- 64 GQA
- KV cache / token (bf16) info
- 256 KiB · High
- Key detail
- Reference dense Qwen stack with QK-Norm and 8 KV heads.
Compare
Qwen3 (4B)
Mid-size dense Qwen3 model used here as a clean baseline against SmolLM3 and Tiny Aya.
- Scale
- 4B parameters
- Context (tokens)
- 32,768
- License
- Apache License 2.0
- Date
- 2025-04-28
- Decoder type
- Dense
- Attention
- GQA with QK-Norm
- Layer mix
- 36 GQA
- KV cache / token (bf16) info
- 144 KiB · Moderate
- Key detail
- Compact Qwen3 dense stack with QK-Norm and a 151k vocabulary.
Compare
Qwen3 (8B)
Dense Qwen3 baseline used here to show how little OLMo 3 changed the overall decoder recipe.
- Scale
- 8B parameters
- Context (tokens)
- 128,000
- License
- Apache License 2.0
- Date
- 2025-04-28
- Decoder type
- Dense
- Attention
- GQA with QK-Norm
- Layer mix
- 36 GQA
- KV cache / token (bf16) info
- 144 KiB · Moderate
- Key detail
- Reference Qwen3 dense stack with QK-Norm and 8 KV heads.
Compare
SmolLM3 (3B)
Compact dense model that experiments with leaving out positional encodings in selected layers.
- Scale
- 3B parameters
- Context (tokens)
- 131,072
- License
- Apache License 2.0
- Date
- 2025-06-19
- Decoder type
- Dense
- Attention
- GQA with periodic NoPE layers
- Layer mix
- 36 GQA
- KV cache / token (bf16) info
- 72 KiB · Low
- Key detail
- Every fourth layer omits RoPE to test a NoPE-style cadence.
Compare
Kimi K2 (1T)
Trillion-parameter Moonshot model that essentially scales the DeepSeek V3 recipe upward.
- Scale
- 1T total, 32B active (3.2% active)
- Context (tokens)
- 128,000
- License
- Modified MIT License
- Date
- 2025-07-10
- Decoder type
- Sparse MoE
- Attention
- MLA
- Layer mix
- 61 MLA
- KV cache / token (bf16) info
- 68.6 KiB · Low
- Key detail
- More experts and fewer MLA heads than DeepSeek V3.
Compare
GLM-4.5 (355B)
Agent-oriented instruction/reasoning hybrid that borrows DeepSeek's dense-prefix MoE layout.
- Scale
- 355B total, 32B active (9% active)
- Context (tokens)
- 128,000
- License
- MIT License
- Date
- 2025-07-28
- Decoder type
- Sparse MoE
- Attention
- GQA with QK-Norm
- Layer mix
- 92 GQA
- KV cache / token (bf16) info
- 368 KiB · Very high
- Key detail
- Starts with three dense layers before MoE routing, keeps a shared expert, and uses MTP during training.
Compare
GPT-OSS (120B)
Larger gpt-oss variant keeps the same alternating-attention recipe as the 20B model.
- Scale
- 117B total, 5.1B active (4.4% active)
- Context (tokens)
- 128,000
- License
- Apache License 2.0
- Date
- 2025-08-04
- Decoder type
- Sparse MoE
- Attention
- GQA with alternating sliding-window and global layers
- Layer mix
- 18 sliding-window + 18 global
- KV cache / token (bf16) info
- 72 KiB · Low
- Key detail
- Shared architectural template scaled up for OpenAI's flagship open-weight release.
Compare
GPT-OSS (20B)
OpenAI's smaller open-weight MoE model favors width and alternating local/global attention.
- Scale
- 21B total, 3.6B active (17.1% active)
- Context (tokens)
- 128,000
- License
- Apache License 2.0
- Date
- 2025-08-04
- Decoder type
- Sparse MoE
- Attention
- GQA with alternating sliding-window and global layers
- Layer mix
- 12 sliding-window + 12 global
- KV cache / token (bf16) info
- 48 KiB · Low
- Key detail
- Wider and shallower than Qwen3, with attention bias and sink mechanisms.
Compare
Gemma 3 (270M)
Tiny Gemma 3 variant that preserves the family's local-global attention recipe at a toy scale.
- Scale
- 270M parameters
- Context (tokens)
- 128,000
- Vocabulary
- 262,144 (~262k)
- License
- Gemma Terms of Use + Gemma Prohibited Use Policy
- Date
- 2025-08-14
- Decoder type
- Dense
- Attention
- Multi-query attention with QK-Norm and 5:1 sliding-window/global attention
- Layer mix
- 15 sliding-window + 3 global
- KV cache / token (bf16) info
- 18 KiB · Very low
- Key detail
- Keeps the Gemma 3 stack shape while shrinking down to 4 attention heads, a single KV head, and the same 262k vocabulary.
Compare
Grok 2.5 (270B)
Rare production-model release that shows an older MoE style with fewer, larger experts.
- Scale
- 270B parameters
- Context (tokens)
- 131,072
- License
- Grok 2 Community License Agreement
- Date
- 2025-08-22
- Decoder type
- Sparse MoE
- Attention
- GQA
- Layer mix
- 64 GQA
- KV cache / token (bf16) info
- 256 KiB · High
- Key detail
- Adds an always-on SwiGLU path that effectively behaves like a shared expert.
Compare
Qwen3 Next (80B-A3B)
Efficiency-focused Qwen refresh that swaps standard attention for a DeltaNet-attention hybrid.
- Scale
- 80B total, 3B active (3.8% active)
- Context (tokens)
- 262,144
- License
- Apache License 2.0
- Date
- 2025-09-09
- Decoder type
- Sparse hybrid
- Attention
- 3:1 Gated DeltaNet and Gated Attention
- Layer mix
- 12 gated attention + 36 DeltaNet
- KV cache / token (bf16) info
- 24 KiB · Very low
- Key detail
- Adds many more experts, a shared expert, native 262k context, and MTP for speculative decoding.
Related concepts
Compare
MiniMax M2 (230B)
MiniMax's flagship returns to full attention and looks like a leaner, sparser cousin of Qwen3.
- Scale
- 230B total, 10B active (4.3% active)
- Context (tokens)
- 196,608
- License
- Modified MIT License
- Date
- 2025-10-23
- Decoder type
- Sparse MoE
- Attention
- GQA with QK-Norm and partial RoPE
- Layer mix
- 62 GQA
- KV cache / token (bf16) info
- 248 KiB · High
- Key detail
- Uses per-layer QK-Norm, much sparser MoE routing than Qwen3, and MTP during training.
Compare
Kimi Linear (48B-A3B)
Linear-attention hybrid that keeps a transformer backbone but replaces most full-attention layers.
- Scale
- 48B total, 3B active (6.3% active)
- Context (tokens)
- 1,000,000
- License
- MIT License
- Date
- 2025-10-30
- Decoder type
- Sparse hybrid
- Attention
- 3:1 Kimi Delta Attention and MLA
- Layer mix
- 7 MLA + 20 Kimi Delta Attention
- KV cache / token (bf16) info
- 7.9 KiB · Very low
- Key detail
- Uses NoPE in MLA layers and channel-wise gating for long-context efficiency.
Related concepts
Compare
OLMo 3 (32B)
Scaled-up OLMo 3 keeps the same block design but moves to grouped-query attention.
- Scale
- 32B parameters
- Context (tokens)
- 65,536
- License
- Apache License 2.0
- Date
- 2025-11-20
- Decoder type
- Dense
- Attention
- GQA with QK-Norm and 3:1 sliding-window/global attention
- Layer mix
- 48 sliding-window + 16 global
- KV cache / token (bf16) info
- 256 KiB · High
- Key detail
- Keeps post-norm while scaling width and applying YaRN only on global layers.
Compare
OLMo 3 (7B)
New transparent Allen AI model that keeps OLMo's post-norm flavor while modernizing context handling.
- Scale
- 7B parameters
- Context (tokens)
- 65,536
- License
- Apache License 2.0
- Date
- 2025-11-20
- Decoder type
- Dense
- Attention
- MHA with QK-Norm and 3:1 sliding-window/global attention
- Layer mix
- 24 sliding-window + 8 global
- KV cache / token (bf16) info
- 512 KiB · Very high
- Key detail
- Retains post-norm, keeps MHA, and applies YaRN only on global layers.
Compare
DeepSeek V3.2 (671B)
DeepSeek's successor keeps the V3 template but adds sparse attention to cut long-context costs.
- Scale
- 671B total, 37B active (5.5% active)
- Context (tokens)
- 128,000
- License
- MIT License
- Date
- 2025-12-01
- Decoder type
- Sparse MoE
- Attention
- MLA with DeepSeek Sparse Attention
- Layer mix
- 61 MLA
- KV cache / token (bf16) info
- 68.6 KiB · Low
- Key detail
- Adds sparse attention while retaining the DeepSeek V3-style MTP path.
Related concepts
Compare
Mistral Large 3 (673B)
Mistral's new flagship effectively adopts the DeepSeek architecture and retunes the expert sizes.
- Scale
- 673B total, 41B active (6.1% active)
- Context (tokens)
- 262,144
- License
- Apache License 2.0
- Date
- 2025-12-02
- Decoder type
- Sparse MoE
- Attention
- MLA
- Layer mix
- 61 MLA
- KV cache / token (bf16) info
- 68.6 KiB · Low
- Key detail
- Near-clone of DeepSeek V3 with larger experts, fewer routed experts, and multimodal support.
Compare
Nemotron 3 Nano (30B-A3B)
NVIDIA's Nano model is the most extreme transformer-state-space hybrid in the gallery.
- Scale
- 30B total, 3B active (10% active)
- Context (tokens)
- 1,000,000
- License
- NVIDIA Nemotron Open Model License
- Date
- 2025-12-04
- Decoder type
- Hybrid MoE
- Attention
- Mostly Mamba-2 with a few GQA layers
- Layer mix
- 6 GQA + 23 Mamba-2 + 23 MoE
- KV cache / token (bf16) info
- 6 KiB · Very low
- Key detail
- Interleaves Mamba-2 and MoE blocks, using attention only sparingly.
Related concepts
Compare
Xiaomi MiMo-V2-Flash (309B)
Large MoE model that pushes sliding-window attention harder than most contemporaries.
- Scale
- 309B total, 15B active (4.9% active)
- Context (tokens)
- 262,144
- License
- MIT License
- Date
- 2025-12-16
- Decoder type
- Sparse MoE
- Attention
- 5:1 sliding-window/global attention
- Layer mix
- 40 sliding-window + 8 global
- KV cache / token (bf16) info
- 144 KiB · Moderate
- Key detail
- Uses an unusually small 128-token local window plus multi-token prediction.
Compare
GLM-4.7 (355B)
Immediate GLM predecessor that stays closer to the older GLM-4.5 style before the MLA shift.
- Scale
- 355B total, 32B active (9% active)
- Context (tokens)
- 202,752
- License
- MIT License
- Date
- 2025-12-22
- Decoder type
- Sparse MoE
- Attention
- GQA with QK-Norm
- Layer mix
- 92 GQA
- KV cache / token (bf16) info
- 368 KiB · Very high
- Key detail
- Serves as the pre-MLA, pre-sparse-attention baseline and uses an MTP-3-style setup.
Compare
Arcee AI Trinity Large (400B)
Arcee's flagship blends several efficiency tricks into a DeepSeek-like coarse MoE design; the AA score shown here refers to the Trinity Large Thinking checkpoint.
- Scale
- 400B total, 13B active (3.3% active)
- Context (tokens)
- 512,000
- License
- Apache License 2.0
- Date
- 2026-01-27
- Decoder type
- Sparse MoE
- Attention
- GQA with gated attention and 3:1 sliding-window/global attention
- Layer mix
- 45 sliding-window + 15 global
- KV cache / token (bf16) info
- 240 KiB · High
- Key detail
- Combines QK-Norm, RoPE+NoPE, sandwich norm, and a coarse-grained MoE.
Compare
GLM-5 (744B)
Huge GLM refresh that adopts both MLA and DeepSeek Sparse Attention for flagship-scale inference.
- Scale
- 744B total, 40B active (5.4% active)
- Context (tokens)
- 202,752
- License
- MIT License
- Date
- 2026-02-11
- Decoder type
- Sparse MoE
- Attention
- MLA with DeepSeek Sparse Attention
- Layer mix
- 78 MLA
- KV cache / token (bf16) info
- 87.8 KiB · Moderate
- Key detail
- Bigger than GLM-4.7, with more experts, fewer layers, and DeepSeek-style MTP.
Related concepts
Compare
Nemotron 3 Super (120B-A12B)
The Super variant scales up Nano and adds both latent experts and native speculative decoding support.
- Scale
- 120B total, 12B active (10% active)
- Context (tokens)
- 1,000,000
- License
- NVIDIA Nemotron Open Model License
- Date
- 2026-03-11
- Decoder type
- Hybrid MoE
- Attention
- Mostly Mamba-2 with a few GQA layers
- Layer mix
- 8 GQA + 40 Mamba-2 + 40 MoE
- KV cache / token (bf16) info
- 8 KiB · Very low
- Key detail
- Adds latent-space MoE and shared-weight MTP for fast inference.
Compare
Gemma 4 (31B)
Dense Gemma 4 scales the family to a 256K-context multimodal checkpoint without changing the core local-global recipe much.
- Scale
- 30.7B parameters
- Context (tokens)
- 256,000
- Vocabulary
- 262,144 (~262k)
- License
- Apache License 2.0
- Date
- 2026-04-02
- Decoder type
- Dense
- Attention
- GQA with QK-Norm, unified K/V on global layers, p-RoPE on global layers, and 5:1 sliding-window/global attention
- Layer mix
- 50 sliding-window + 10 global
- KV cache / token (bf16) info
- 840 KiB · Very high
- Key detail
- Carries Gemma's unusual pre/post-norm stack into a larger 31B dense model with 256K context.
Compare
Gemma 4 (26B-A4B)
Sparse Gemma 4 variant that keeps the local:global attention backbone while swapping dense FFNs for MoE layers.
- Scale
- 25.2B total, 3.8B active (15.1% active)
- Context (tokens)
- 256,000
- Vocabulary
- 262,144 (~262k)
- License
- Apache License 2.0
- Date
- 2026-04-02
- Decoder type
- Sparse MoE
- Attention
- GQA with QK-Norm, unified K/V on global layers, p-RoPE on global layers, and 5:1 sliding-window/global attention
- Layer mix
- 25 sliding-window + 5 global
- KV cache / token (bf16) info
- 210 KiB · High
- Key detail
- Uses 128 total experts with only 8 routed plus 1 shared expert active per token.
Compare
Gemma 4 (12B)
Dense Gemma 4 12B Unified uses an encoder-free multimodal input path, while its text decoder keeps the 31B-style local-global attention recipe.
- Scale
- 12B parameters
- Context (tokens)
- 128,000
- Vocabulary
- 262,144 (~262k)
- License
- Apache License 2.0
- Date
- 2026-06-03
- Decoder type
- Dense
- Attention
- GQA with QK-Norm, unified K/V on global layers, p-RoPE on global layers, and 5:1 sliding-window/global attention
- Layer mix
- 40 sliding-window + 8 global
- KV cache / token (bf16) info
- 328 KiB · Very high
- Key detail
- Figure shows the 48-layer text decoder; the full 12B Unified model also projects audio, image, and video inputs directly into the decoder input stream.
Compare
Llama 3.2 (3B)
Small Llama baseline used to show how closely Nanbeige follows the mainstream compact decoder recipe.
- Scale
- 3B parameters
- Context (tokens)
- 128,000
- License
- Llama 3.2 Community License Agreement
- Date
- 2024-09-25
- Decoder type
- Dense
- Attention
- GQA
- Layer mix
- 28 GQA
- KV cache / token (bf16) info
- 112 KiB · Moderate
- Key detail
- Reference small-model Llama architecture with tied embeddings.
Compare
Qwen3 Coder Flash (30B-A3B)
Coding-tuned Qwen model that keeps a straightforward grouped-query MoE stack instead of the newer hybrid-attention variants.
- Scale
- 30B total, 3.3B active (11% active)
- Context (tokens)
- 256,000
- License
- Apache License 2.0
- Date
- 2025-07-31
- Decoder type
- Sparse MoE
- Attention
- GQA
- Layer mix
- 48 GQA
- KV cache / token (bf16) info
- 96 KiB · Moderate
- Key detail
- Uses 128 experts with 8 active per token and a native 256k context window for coding workloads.
Compare
Kimi K2.5 (1T)
Native-multimodal Moonshot flagship that keeps the K2/DeepSeek-style MoE layout and pushes native context to 256k.
- Scale
- 1T total, 32B active (3.2% active)
- Context (tokens)
- 256,000
- License
- Modified MIT License
- Date
- 2026-01-27
- Decoder type
- Sparse MoE
- Attention
- MLA
- Layer mix
- 61 MLA
- KV cache / token (bf16) info
- 68.6 KiB · Low
- Key detail
- Keeps the 384-expert K2 backbone, but adds multimodal capabilities (not shown) and doubles the native context length.
Compare
Step 3.5 Flash (196B)
Throughput-oriented MoE model that stays competitive with much larger DeepSeek-style systems.
- Scale
- 196B total, 11B active (5.6% active)
- Context (tokens)
- 262,144
- License
- Apache License 2.0
- Date
- 2026-02-01
- Decoder type
- Sparse MoE
- Attention
- GQA with 3:1 sliding-window attention
- Layer mix
- 36 sliding-window + 12 global
- KV cache / token (bf16) info
- 192 KiB · High
- Key detail
- Uses MTP-3 during both training and inference for unusually high throughput.
Compare
Nanbeige 4.1 (3B)
Small on-device oriented model that stays close to Llama 3.2 while nudging the scaling choices.
- Scale
- 3B parameters
- Context (tokens)
- 262,144
- License
- Apache License 2.0
- Date
- 2026-02-10
- Decoder type
- Dense
- Attention
- GQA
- Layer mix
- 32 GQA
- KV cache / token (bf16) info
- 64 KiB · Low
- Key detail
- Llama-like stack without tying input embeddings to the output layer.
Compare
MiniMax-M2.5 (230B)
Popular 230B coder that opts for a classic architecture instead of the newer hybrid-attention ideas.
- Scale
- 230B total, 10B active (4.3% active)
- Context (tokens)
- 196,608
- License
- Modified MIT License
- Date
- 2026-02-12
- Decoder type
- Sparse MoE
- Attention
- GQA with QK-Norm
- Layer mix
- 62 GQA
- KV cache / token (bf16) info
- 248 KiB · High
- Key detail
- Deliberately avoids sliding-window or linear-attention hybrids while keeping a 10B active path and three MTP modules.
Compare
Tiny Aya (3.35B)
Compact multilingual model from Cohere with a rare parallel transformer block.
- Scale
- 3.35B parameters
- Context (tokens)
- 8,192
- License
- Creative Commons Attribution-NonCommercial 4.0
- Date
- 2026-02-13
- Decoder type
- Dense
- Attention
- GQA with 3:1 sliding-window attention
- Layer mix
- 27 sliding-window + 9 global
- KV cache / token (bf16) info
- 72 KiB · Low
- Key detail
- Runs attention and the MLP in parallel while mixing RoPE with NoPE.
Compare
Ling 2.5 (1T)
Trillion-parameter long-context model that swaps DeltaNet for Lightning Attention.
- Scale
- 1T total, 63B active (6.3% active)
- Context (tokens)
- 256,000
- License
- MIT License
- Date
- 2026-02-15
- Decoder type
- Sparse hybrid
- Attention
- Lightning Attention plus MLA
- Layer mix
- 10 MLA + 70 Lightning Attention
- KV cache / token (bf16) info
- 11.2 KiB · Very low
- Key detail
- Uses a 7:1 linear-attention/MLA ratio and a much larger 63B active path.
Related concepts
Compare
Qwen3.5 (397B)
Mainline Qwen refresh that brings the Next-style hybrid attention into the flagship series.
- Scale
- 397B total, 17B active (4.3% active)
- Context (tokens)
- 262,144
- License
- Apache License 2.0
- Date
- 2026-02-16
- Decoder type
- Sparse hybrid
- Attention
- 3:1 Gated DeltaNet and Gated Attention
- Layer mix
- 15 gated attention + 45 DeltaNet
- KV cache / token (bf16) info
- 30 KiB · Low
- Key detail
- Turns the former Qwen3-Next side branch into the new core design with 512 experts and 17B active parameters.
Related concepts
Compare
Sarvam (30B)
Reasoning-oriented Indian-language sparse MoE that keeps GQA at the smaller size.
- Scale
- 30B total, 2.4B active (8% active)
- Context (tokens)
- 131,072
- License
- Apache License 2.0
- Date
- 2026-03-03
- Decoder type
- Sparse MoE
- Attention
- GQA with QK-Norm
- Layer mix
- 19 GQA
- KV cache / token (bf16) info
- 19 KiB · Very low
- Key detail
- Large vocabulary and strong Indic language support paired with a reasoning-focused sparse MoE design.
Compare
Sarvam (105B)
Larger Sarvam variant keeps the sparse MoE layout but switches from GQA to MLA.
- Scale
- 105B total, 10.3B active (9.8% active)
- Context (tokens)
- 131,072
- License
- Apache License 2.0
- Date
- 2026-03-03
- Decoder type
- Sparse MoE
- Attention
- MLA with KV LayerNorm and NoPE + RoPE
- Layer mix
- 32 MLA
- KV cache / token (bf16) info
- 36 KiB · Low
- Key detail
- Large vocabulary and strong Indic language support carried into the larger MLA-based sparse MoE variant.
Compare
Phi-4 (14B)
Microsoft's 14B dense Phi refresh stays close to Phi-3-medium but swaps its sliding-window attention for full-context GQA and a larger tokenizer.
- Scale
- 14B parameters
- Context (tokens)
- 16,384
- License
- MIT License
- Date
- 2024-12-12
- Decoder type
- Dense
- Attention
- GQA with RoPE
- Layer mix
- 40 GQA
- KV cache / token (bf16) info
- 200 KiB · High
- Key detail
- Classic pre-norm RMSNorm stack with GQA, 40 heads, 10 KV heads, and a 100,352-token vocabulary.
Compare
xLSTM (7B)
Recurrent 7B language model that replaces self-attention with xLSTM blocks built around matrix memory.
- Scale
- 7B parameters
- Context (tokens)
- No explicit limit
- License
- NXAI Community License Agreement
- Date
- 2025-03-17
- Decoder type
- Recurrent
- Attention
- No self-attention; mLSTM recurrent layers with matrix memory
- Layer mix
- 32 mLSTM
- KV cache / token (bf16) info
- 0 B · No cache
- Key detail
- Stateful recurrent architecture aimed at fast long-context inference without an explicit context window.
Related concepts
Compare
GLM-4.5-Air (106B)
Compact GLM-4.5 companion that keeps the same agent-oriented sparse MoE recipe at a smaller serving footprint.
- Scale
- 106B total, 12B active (11.3% active)
- Context (tokens)
- 128,000
- License
- MIT License
- Date
- 2025-07-28
- Decoder type
- Sparse MoE
- Attention
- GQA
- Layer mix
- 46 GQA
- KV cache / token (bf16) info
- 184 KiB · High
- Key detail
- Shrinks the GLM-4.5 layout to 46 layers, keeps the dense warmup, and inherits the MTP training recipe.
Compare
INTELLECT-3 (106B)
Large-scale RL post-training of GLM-4.5-Air that keeps the compact 106B sparse MoE backbone intact.
- Scale
- 106B total, 12B active (11.3% active)
- Context (tokens)
- 128,000
- License
- MIT License
- Date
- 2025-11-26
- Decoder type
- Sparse MoE
- Attention
- GQA
- Layer mix
- 46 GQA
- KV cache / token (bf16) info
- 184 KiB · High
- Key detail
- Keeps the GLM-4.5-Air architecture unchanged and shifts the capability profile through SFT plus large-scale RL.
Compare
LongCat-Flash-Lite (68.5B-A3B)
Meituan's LongCat-Next text backbone is a lightweight MoE that shifts a large share of parameters into N-gram embeddings while keeping sparse inference around 3B active parameters.
- Scale
- 68.5B total, ~3B active avg (4.4% active)
- Context (tokens)
- 256,000
- Vocabulary
- 131,072
- License
- MIT License
- Date
- 2026-01-28
- Decoder type
- Sparse MoE
- Attention
- MLA with RoPE + NoPE
- Layer mix
- 28 logical layers / 56 MLA sublayers
- KV cache / token (bf16) info
- 63 KiB · Low
- Key detail
- Uses N-gram embedding expansion, Shortcut MoE routing over 512 routed plus 256 zero/identity experts, and top-k 12 expert choices per token.
Compare
Mistral Small 4 (119B)
Multimodal Mistral Small refresh that jumps from the older dense 24B stack to an MLA-based sparse MoE design.
- Scale
- 119B total, 6.63B active (5.6% active)
- Context (tokens)
- 256,000
- License
- Apache License 2.0
- Date
- 2026-03-16
- Decoder type
- Sparse MoE
- Attention
- MLA
- Layer mix
- 36 MLA
- KV cache / token (bf16) info
- 22.5 KiB · Very low
- Key detail
- Uses 128 experts with 4 routed plus 1 shared expert active per token while unifying instruct, reasoning, and vision.
Compare
Nemotron 3 Nano (4B)
Compact on-device hybrid that compresses Nemotron Nano 9B v2 into a mostly Mamba-2 stack with only four attention layers.
- Scale
- 4B parameters
- Context (tokens)
- 262,144
- License
- NVIDIA Nemotron Open Model License
- Date
- 2026-03-16
- Decoder type
- Dense hybrid
- Attention
- GQA with only 4 attention layers
- Layer mix
- 4 GQA + 21 Mamba-2 + 17 FFN
- KV cache / token (bf16) info
- 16 KiB · Very low
- Key detail
- Uses a 42-layer stack with 21 Mamba-2 blocks, 17 ReLU² FFNs, and just 4 GQA layers.
Related concepts
Compare
MiniMax M2.7 (230B)
Agent-focused 230B follow-up built for self-evolution, agent harnesses, and productivity workflows.
- Scale
- 230B total, 10B active (4.3% active)
- Context (tokens)
- 196,608
- License
- MiniMax M2.7 Non-Commercial License
- Date
- 2026-03-18
- Decoder type
- Sparse MoE
- Attention
- GQA with QK-Norm
- Layer mix
- 62 GQA
- KV cache / token (bf16) info
- 248 KiB · High
- Key detail
- Keeps the M2.5-style 62-layer sparse MoE stack and adds three MTP modules for speculative decoding support.
Compare
Gemma 4 (E2B)
Smallest Gemma 4 edge model keeps the family's hybrid attention stack and adds native audio on a phone-scale multimodal footprint. Uses per-layer embeddings, which add small layer-specific token vectors without scaling the full compute path, so its compute footprint is closer to 2.3B than a full 5.1B dense model.
- Scale
- 5.1B parameters (2.3B effective)
- Context (tokens)
- 128,000
- Vocabulary
- 262,144 (~262k)
- License
- Apache License 2.0
- Date
- 2026-04-02
- Decoder type
- Dense
- Attention
- Multi-query attention with QK-Norm, unified K/V on global layers, p-RoPE on global layers, and 4:1 sliding-window/global attention
- Layer mix
- 28 sliding-window + 7 global
- KV cache / token (bf16) info
- 35 KiB · Low
- Key detail
- Uses a double-wide GELU MLP plus a single KV head to stay light enough for offline edge deployments.
Related concepts
Compare
Gemma 4 (E4B)
Larger Gemma 4 edge variant keeps the same multimodal hybrid recipe but doubles width and KV heads for a stronger 128K mobile checkpoint. Uses per-layer embeddings, which add small layer-specific token vectors without scaling the full compute path, so its compute footprint is closer to 4.5B than a full 8B dense model.
- Scale
- 8B parameters (4.5B effective)
- Context (tokens)
- 128,000
- Vocabulary
- 262,144 (~262k)
- License
- Apache License 2.0
- Date
- 2026-04-02
- Decoder type
- Dense
- Attention
- GQA with QK-Norm, unified K/V on global layers, p-RoPE on global layers, and 5:1 sliding-window/global attention
- Layer mix
- 35 sliding-window + 7 global
- KV cache / token (bf16) info
- 84 KiB · Moderate
- Key detail
- Steps up to a 42-layer stack with 2 KV heads while keeping the same edge-oriented local/global template.
Compare
DeepSeek V4-Flash (284B)
DeepSeek's efficient V4 preview keeps the million-token architecture while reducing the MoE scale to 284B parameters and 13B active parameters.
- Scale
- 284B total, 13B active (4.6% active)
- Context (tokens)
- 1,048,576
- License
- MIT License
- Date
- 2026-04-24
- Decoder type
- Sparse MoE
- Attention
- MLA-style CSA/HCA with mHC
- Layer mix
- 43 CSA/HCA
- KV cache / token (bf16) info
- 5.4 KiB · Very low
- Key detail
- Uses 256 experts, 6 routed plus 1 shared expert per token, hash-based routing, compressed attention, and the V4 MTP path.
Compare
DeepSeek V4-Pro (1.6T)
DeepSeek's flagship V4 preview scales to 1.6T parameters and introduces compressed sparse attention plus manifold-constrained hyper-connections for million-token contexts.
- Scale
- 1.6T total, 49B active (3.1% active)
- Context (tokens)
- 1,048,576
- License
- MIT License
- Date
- 2026-04-24
- Decoder type
- Sparse MoE
- Attention
- MLA-style CSA/HCA with mHC
- Layer mix
- 61 CSA/HCA
- KV cache / token (bf16) info
- 7.7 KiB · Very low
- Key detail
- Uses 384 experts, 6 routed plus 1 shared expert per token, hash-based routing, compressed attention caches, and the V4 MTP path.
Compare
Laguna XS.2 (33B)
Poolside's open-weight agentic coding MoE uses mixed sliding-window/global attention and activates only 3B of 33B parameters per token.
- Scale
- 33B total, 3B active (9.1% active)
- Context (tokens)
- 131,072
- License
- Apache License 2.0
- Date
- 2026-04-28
- Decoder type
- Sparse MoE
- Attention
- Gated GQA with QK-Norm and 3:1 sliding-window/global attention
- Layer mix
- 30 sliding-window + 10 global
- KV cache / token (bf16) info
- 160 KiB · Moderate
- Key detail
- Uses per-layer query-head counts, a 512-token SWA window, sigmoid MoE routing, and one shared expert alongside the top-8 routed experts.
Compare
ZAYA1-8B (8.4B)
Zyphra's compact reasoning MoE pairs CCA/GQA attention updates with top-1 routed expert FFN updates to keep fewer than 1B parameters active per token.
- Scale
- 8.4B total, 760M active/token (9% active)
- Context (tokens)
- 131,072
- Vocabulary
- 262,272
- License
- Apache License 2.0
- Date
- 2026-05-06
- Decoder type
- Sparse MoE
- Attention
- CCA with 4:1 GQA, RoPE, and Q/K L2 norm
- Layer mix
- 40 CCA/GQA attention + 40 top-1 MoE FFN entries
- KV cache / token (bf16) info
- 40 KiB · Low
- Key detail
- Key detail is CCA/GQA attention, which performs attention in a compressed latent space while keeping a 4:1 GQA layout. Sidenote: the config lists 80 alternating layer entries, equivalent to 40 CCA/GQA attention updates paired with 40 top-1 MoE FFN updates.
Compare
GLM-5.1 (744B)
Post-trained GLM refresh that keeps the GLM-5 backbone intact but targets stronger long-horizon agentic coding.
- Scale
- 744B total, 40B active (5.4% active)
- Context (tokens)
- 202,752
- License
- MIT License
- Date
- 2026-04-07
- Decoder type
- Sparse MoE
- Attention
- MLA with DeepSeek Sparse Attention
- Layer mix
- 78 MLA
- KV cache / token (bf16) info
- 87.8 KiB · Moderate
- Key detail
- Architecture stays aligned with GLM-5, including its MTP-capable backbone; the main shift is post-training.
Related concepts
Compare
Qwen3.6 (35B-A3B)
Compact Qwen3.6 open-weight MoE that keeps the Qwen3.5 hybrid Gated DeltaNet/Gated Attention recipe while activating only about 3B parameters.
- Scale
- 35B total, 3B active (8.6% active)
- Context (tokens)
- 262,144
- License
- Apache License 2.0
- Date
- 2026-04-15
- Decoder type
- Sparse hybrid
- Attention
- 3:1 Gated DeltaNet and Gated Attention
- Layer mix
- 10 gated attention + 30 DeltaNet
- KV cache / token (bf16) info
- 20 KiB · Very low
- Key detail
- Uses 256 experts with 8 routed plus 1 shared expert active inside a 40-layer hybrid stack.
Related concepts
Compare
Kimi K2.6 (1T)
Native-multimodal K2.5 successor that keeps the same 1T sparse MoE backbone while targeting stronger long-horizon coding, design, and agent orchestration.
- Scale
- 1T total, 32B active (3.2% active)
- Context (tokens)
- 256,000
- License
- Modified MIT License
- Date
- 2026-04-20
- Decoder type
- Sparse MoE
- Attention
- MLA
- Layer mix
- 61 MLA
- KV cache / token (bf16) info
- 68.6 KiB · Low
- Key detail
- Uses the same text architecture as Kimi K2.5, with the main change coming from the multimodal and agentic training recipe.
Compare
Qwen3.6 (27B)
Dense Qwen3.6 model that keeps the Qwen3.5-style Gated DeltaNet/Gated Attention hybrid stack while replacing MoE blocks with dense FFNs.
- Scale
- 27B parameters
- Context (tokens)
- 262,144
- License
- Apache License 2.0
- Date
- 2026-04-22
- Decoder type
- Dense hybrid
- Attention
- 3:1 Gated DeltaNet and Gated Attention
- Layer mix
- 16 gated attention + 48 DeltaNet
- KV cache / token (bf16) info
- 64 KiB · Low
- Key detail
- Uses a 64-layer dense hybrid layout with 48 DeltaNet layers and 16 full-attention layers.
Related concepts
Compare
Xiaomi MiMo-V2.5 (310B)
Omnimodal sparse MoE model that extends the MiMo-V2-Flash backbone with vision and audio encoders.
- Scale
- 310B total, 15B active (4.8% active)
- Context (tokens)
- 1,048,576
- License
- MIT License
- Date
- 2026-04-22
- Decoder type
- Sparse omnimodal MoE
- Attention
- 5:1 sliding-window/global attention
- Layer mix
- 39 sliding-window + 9 global
- KV cache / token (bf16) info
- 144 KiB · Moderate
- Key detail
- Adds native image, video, and audio encoders to the MiMo-V2-Flash-style sparse MoE backbone with MTP support.
Compare
Xiaomi MiMo-V2.5-Pro (1.02T)
Trillion-parameter sparse MoE model for long-horizon agentic and software-engineering tasks.
- Scale
- 1.02T total, 42B active (4.1% active)
- Context (tokens)
- 1,048,576
- Vocabulary
- 152,576 (~152k)
- License
- MIT License
- Date
- 2026-04-22
- Decoder type
- Sparse MoE
- Attention
- GQA with 6:1 sliding-window/global attention
- Layer mix
- 60 sliding-window + 10 global
- KV cache / token (bf16) info
- 350 KiB · Very high
- Key detail
- Scales the MiMo-V2.5 Pro stack to 70 layers, 384 routed experts, top-8 routing, and a 1M-token context window.
Compare
Ling 2.6 (1T)
Ling 2.5 successor that keeps the Lightning Attention and MLA hybrid stack while adding an MTP layer for multi-token prediction.
- Scale
- 1T total, 63B active (6.3% active)
- Context (tokens)
- 262,144
- License
- MIT License
- Date
- 2026-04-23
- Decoder type
- Sparse hybrid
- Attention
- Lightning Attention plus MLA
- Layer mix
- 10 MLA + 70 Lightning Attention + 1 MTP layer
- KV cache / token (bf16) info
- 11.2 KiB · Very low
- Key detail
- Keeps the 7:1 linear-attention/MLA ratio and adds one multi-token-prediction layer for speculative decoding.
Related concepts
Compare
Tencent Hy3-preview (295B-A21B)
Tencent Hunyuan's 295B sparse MoE preview combines a dense first FFN layer, GQA with QK-Norm, and one extra MTP layer for faster generation.
- Scale
- 295B total, 21B active (7.1% active)
- Context (tokens)
- 262,144
- License
- Tencent Hy Community License Agreement
- Date
- 2026-04-23
- Decoder type
- Sparse MoE
- Attention
- GQA with QK-Norm
- Layer mix
- 80 GQA + 1 MTP layer
- KV cache / token (bf16) info
- 320 KiB · Very high
- Key detail
- Uses 192 routed experts, 8 routed plus 1 shared expert active per token, sigmoid routing with expert bias, and a 3.8B MTP layer.
Compare
Granite 4.1 (30B)
IBM's dense 30B Granite 4.1 model keeps a straightforward long-context GQA transformer stack and improves tool calling, instruction following, and chat behavior through post-training.
- Scale
- 30B parameters
- Context (tokens)
- 131,072
- Vocabulary
- 100,352
- License
- Apache License 2.0
- Date
- 2026-04-29
- Decoder type
- Dense
- Attention
- GQA with RoPE
- Layer mix
- 64 GQA
- KV cache / token (bf16) info
- 256 KiB · High
- Key detail
- Uses a 4096-wide dense stack, 32 query heads, 8 KV heads, SwiGLU MLPs, shared input/output embeddings, and Granite-specific MuP scaling factors.
Compare
Command A+ (218B-A25B)
Cohere's open sparse MoE model scales the Command A parallel transformer block to 218B total parameters while keeping 25B active per token.
- Scale
- 218B total, 25B active/token (11.5% active)
- Context (tokens)
- 128K input, 64K output
- Vocabulary
- 262,144
- License
- Apache License 2.0
- Date
- 2026-05-20
- Decoder type
- Sparse MoE
- Attention
- 16:1 GQA with 3:1 sliding-window/global attention
- Layer mix
- 24 sliding-window + 8 global GQA/MoE
- KV cache / token (bf16) info
- 128 KiB · Moderate
- Key detail
- Runs attention and MoE in parallel, which Cohere reports gives similar quality to a sequential block with better throughput.
Compare
LFM2.5 (1.2B)
Liquid AI's 1.2B LFM2.5 model keeps the 16-layer hybrid LIV convolution and GQA stack at a wider hidden size.
- Scale
- 1.2B parameters
- Context (tokens)
- 128,000
- Vocabulary
- 65,536 (~65k)
- License
- LFM Open License v1.0
- Date
- 2026-05-28
- Decoder type
- Dense hybrid
- Attention
- LIV convolution blocks plus GQA
- Layer mix
- 10 LIV conv + 6 GQA
- KV cache / token (bf16) info
- 12 KiB · Very low
- Key detail
- Keeps the 16-layer LFM2.5 hybrid stack but doubles the hidden size to 2048 and uses 32 query heads.
Compare
LFM2.5 (350M)
Liquid AI's compact LFM2.5 model combines double-gated LIV convolution blocks with periodic GQA layers.
- Scale
- 350M parameters
- Context (tokens)
- 128,000
- Vocabulary
- 65,536 (~65k)
- License
- LFM Open License v1.0
- Date
- 2026-05-28
- Decoder type
- Dense hybrid
- Attention
- LIV convolution blocks plus GQA
- Layer mix
- 10 LIV conv + 6 GQA
- KV cache / token (bf16) info
- 12 KiB · Very low
- Key detail
- Uses a 16-layer hybrid stack with 10 LIV convolution layers and 6 GQA layers.
Compare
LFM2.5 (8B-A1B)
Liquid AI's sparse LFM2.5 model combines LIV convolution, GQA, and MoE routing with 4 of 32 experts active per token.
- Scale
- 8.3B total, 1.5B active (18.1% active)
- Context (tokens)
- 128,000
- Vocabulary
- 128,000
- License
- LFM Open License v1.0
- Date
- 2026-05-28
- Decoder type
- Sparse hybrid
- Attention
- LIV convolution blocks plus GQA and MoE
- Layer mix
- 18 LIV conv + 6 GQA + MoE FFNs
- KV cache / token (bf16) info
- 12 KiB · Very low
- Key detail
- Uses 24 layers, 32 MoE experts with 4 active per token, and leaves the first two layers dense before sparse routing begins.
Compare
JetBrains Mellum2 Thinking (12B-A2.5B)
JetBrains' Mellum2 Thinking is a compact reasoning-tuned sparse MoE for code and agentic workflows.
- Scale
- 12B total, 2.5B active (20.8% active)
- Context (tokens)
- 131,072
- Vocabulary
- 98,304 (~98k)
- License
- Apache License 2.0
- Date
- 2026-06-01
- Decoder type
- Sparse MoE
- Attention
- GQA with 3:1 sliding-window/full attention
- Layer mix
- 21 sliding-window + 7 full GQA
- KV cache / token (bf16) info
- 56 KiB · Low
- Key detail
- Uses 64 experts with 8 active per token, a 1024-token sliding window, and YaRN scaling on full-attention layers.
Compare
Nemotron 3 Ultra (550B-A55B)
NVIDIA's Ultra model scales the Nemotron 3 hybrid stack to 550B total parameters while keeping 55B active per token.
- Scale
- 550B total, 55B active (10% active)
- Context (tokens)
- 1,000,000
- License
- NVIDIA Nemotron Open Model License
- Date
- 2026-06-04
- Decoder type
- Hybrid MoE
- Attention
- Mostly Mamba-2 with a few GQA layers
- Layer mix
- 12 GQA + 48 Mamba-2 + 48 MoE
- KV cache / token (bf16) info
- 12 KiB · Very low
- Key detail
- Scales the latent-MoE hybrid to 108 layers with 48 Mamba-2, 48 latent MoE, and 12 GQA layers.
Related concepts
Compare
North Mini Code (30B-A3B)
Cohere's compact agentic coding MoE adapts the parallel Cohere2-MoE block to a 30B total, 3B active model.
- Scale
- 30B total, 3B active (10% active)
- Context (tokens)
- 256K input, 64K output
- Vocabulary
- 262,144
- License
- Apache License 2.0
- Date
- 2026-06-05
- Decoder type
- Sparse MoE
- Attention
- 8:1 GQA with 3:1 sliding-window/global attention
- Layer mix
- 36 sliding-window + 13 global GQA/MoE
- KV cache / token (bf16) info
- 98 KiB · Moderate
- Key detail
- Runs attention and MoE in parallel, with RoPE in sliding-window layers, NoPE in global layers, and top-8 routing over 128 experts.
Compare
Kimi K2.7 Code (1T)
Coding-focused K2.6 successor that keeps the same 1T sparse MoE text backbone and emphasizes long-horizon software engineering agents.
- Scale
- 1T total, 32B active (3.2% active)
- Context (tokens)
- 256,000
- License
- Modified MIT License
- Date
- 2026-06-12
- Decoder type
- Sparse MoE
- Attention
- MLA
- Layer mix
- 61 MLA
- KV cache / token (bf16) info
- 68.6 KiB · Low
- Key detail
- Keeps the Kimi K2.5/K2.6 text architecture and shifts the release focus toward coding-agent workflows.
Compare
MiniMax M3 (428B)
Native multimodal MiniMax model that adds sparse attention to an M2-style MoE backbone for 1M-token context.
- Scale
- 428B total, 23B active (5.4% active)
- Context (tokens)
- 1,048,576
- License
- MiniMax Community License
- Date
- 2026-06-13
- Decoder type
- Sparse MoE
- Attention
- GQA with QK-Norm and MiniMax Sparse Attention
- Layer mix
- 3 full GQA + 57 MiniMax Sparse Attention
- KV cache / token (bf16) info
- 120 KiB · Moderate
- Key detail
- Uses three dense prefix layers, then 57 sparse-attention MoE layers with 128 routed experts and 4 routed plus 1 shared expert active per token.
Related concepts
Compare
VibeThinker-3B (3B)
Qwen2.5-Coder-based dense reasoner whose gains mainly come from verifier-driven post-training rather than a new block design.
- Scale
- 3B parameters
- Context (tokens)
- 131,072
- Vocabulary
- 151,936 (~152k)
- License
- MIT License
- Date
- 2026-06-15
- Decoder type
- Dense
- Attention
- 8:1 GQA with RoPE
- Layer mix
- 36 GQA
- KV cache / token (bf16) info
- 36 KiB · Low
- Key detail
- Standard Qwen2.5-Coder-style dense stack strengthened by curriculum SFT, MGPO RL, Long2Short RL, offline self-distillation, and Instruct RL.
Compare
GLM-5.2 (744B)
Long-context GLM refresh that keeps the 744B sparse MoE backbone and adds IndexShare for 1M-token DSA inference.
- Scale
- 744B total, 40B active (5.4% active)
- Context (tokens)
- 1,048,576
- License
- MIT License
- Date
- 2026-06-17
- Decoder type
- Sparse MoE
- Attention
- MLA with DeepSeek Sparse Attention and IndexShare
- Layer mix
- 78 MLA/DSA
- KV cache / token (bf16) info
- 87.8 KiB · Moderate
- Key detail
- Reuses each full DSA indexer result across the next three layers, making 1M-token sparse attention cheaper.
Related concepts
Compare
Soofi S (30B-A3B)
German-English base model that retrains the Nemotron 3 Nano architecture on 26.68T tokens with a fully documented data mixture.
- Scale
- 31.6B total, 3.2B active (10.1% active)
- Context (tokens)
- 1,048,576
- License
- Custom license (preview)
- Date
- 2026-07-10
- Decoder type
- Hybrid MoE
- Attention
- Mostly Mamba-2 with 6 GQA layers and no positional embeddings (NoPE)
- Layer mix
- 6 GQA + 23 Mamba-2 + 23 MoE
- KV cache / token (bf16) info
- 6 KiB · Very low
- Key detail
- Reuses the Nemotron 3 Nano architecture without modification, isolating the effect of a German-English data and training recipe.
Related concepts
Compare
Inkling (975B)
Thinking Machines Lab's native multimodal model combines a 66-layer sparse MoE decoder with a 5:1 mix of local and global GQA.
- Scale
- 975B total, 41B active (4.2% active)
- Context (tokens)
- 1,048,576
- Vocabulary
- 200,058 (~200k)
- License
- Apache License 2.0
- Date
- 2026-07-15
- Decoder type
- Sparse MoE
- Attention
- GQA with QK-Norm and learned relative-position bias in a 5:1 sliding-window/global pattern
- Layer mix
- 55 sliding-window + 11 global GQA
- KV cache / token (bf16) info
- 484 KiB · Very high
- Key detail
- Uses learned relative-position bias instead of RoPE and adds four short convolutions to each decoder layer.
Compare
Source article
The Big LLM Architecture Comparison
The original comparison article that walks through the architecture figures in context and explains the key design choices across dense, MoE, MLA, and hybrid decoder families.
Read article
Source article
From GPT-2 to gpt-oss: Analyzing the Architectural Advances
A focused follow-up article on the GPT-2 to gpt-oss shift, covering the architectural changes around RoPE, SwiGLU, MoE, GQA, sliding-window attention, and RMSNorm.
Read article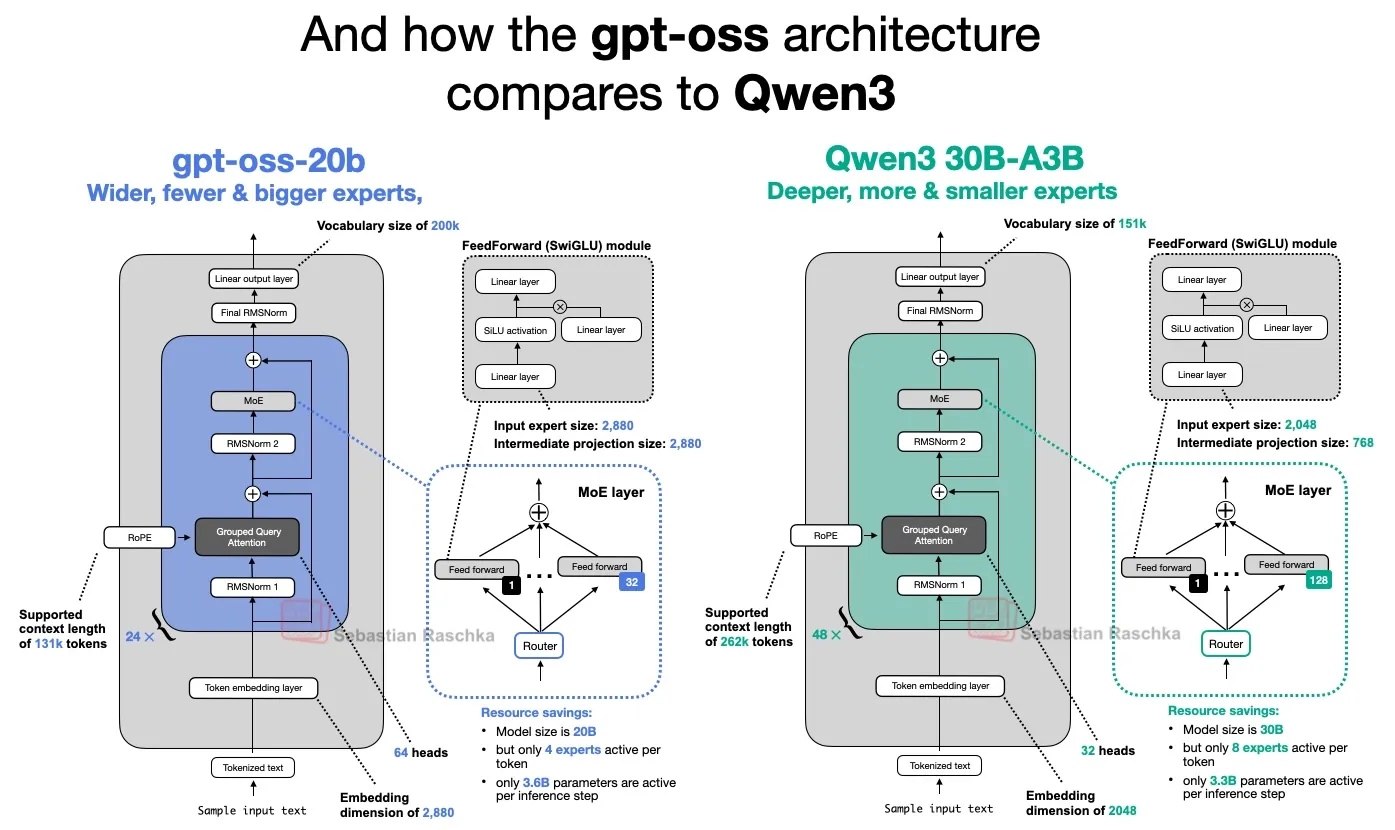
Source article
From DeepSeek V3 to V3.2: Architecture, Sparse Attention, and RL Updates
A DeepSeek-focused follow-up covering the V3.2 architecture updates, sparse attention changes, and the broader RL-related developments around the release.
Read article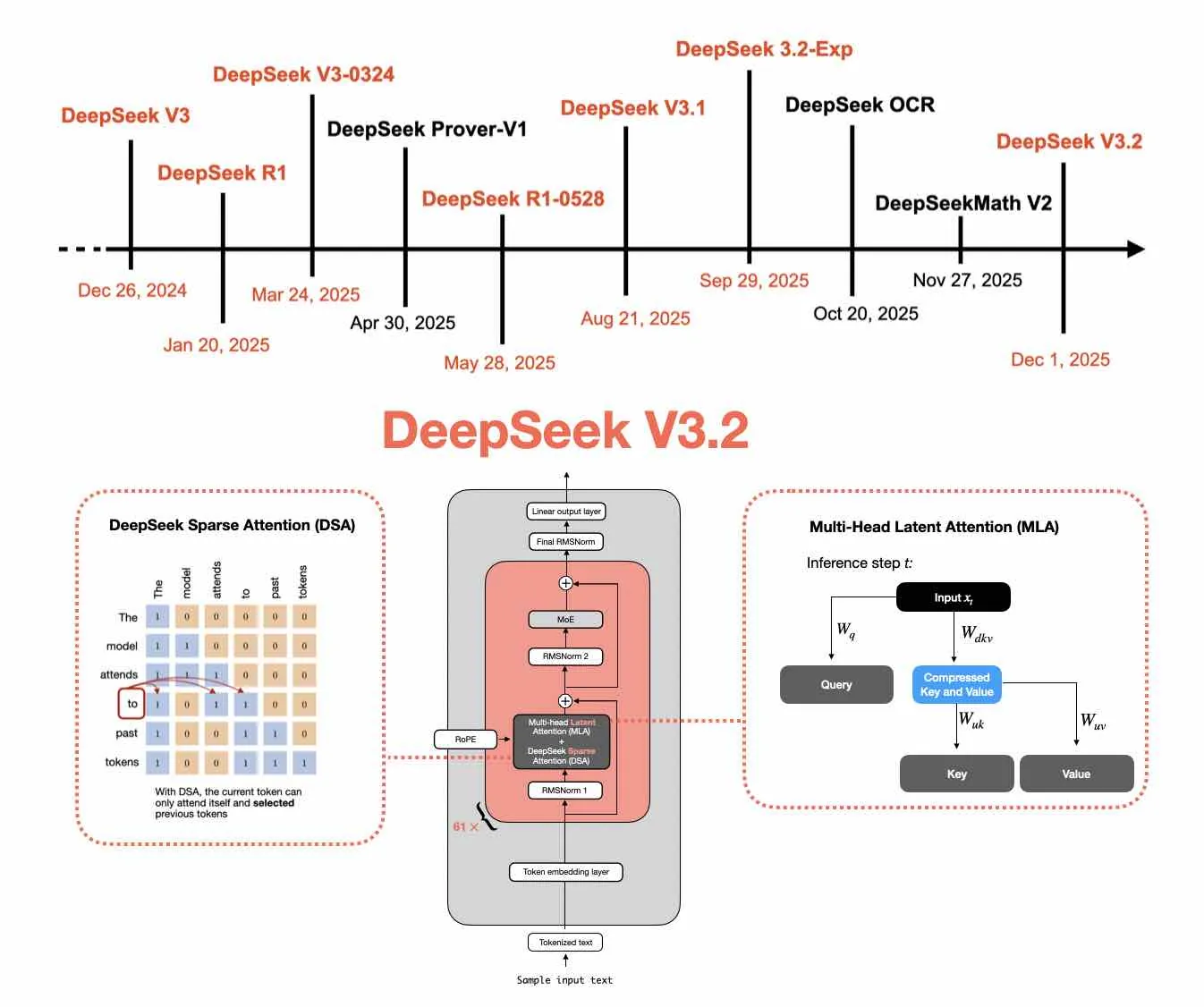
Source article
A Dream of Spring for Open-Weight LLMs
Follow-up article covering the additional open-weight architecture releases from early 2026, including the newer MiniMax, Qwen, Ling, and Sarvam families.
Read article
Cite / Share
Canonical URL
Short Description
A curated LLM Architecture Gallery with model architecture figures, compact fact sheets, source links, implementation links, and comparison tools for modern language models.
BibTeX
@misc{raschka2026llmarchitecturegallery,
author = {Raschka, Sebastian},
title = {LLM Architecture Gallery},
year = {2026},
month = {March},
url = {https://sebastianraschka.com/llm-architecture-gallery/},
note = {Accessed: 2026-07-20}
}Suggested Share Text
LLM Architecture Gallery by Sebastian Raschka: https://sebastianraschka.com/llm-architecture-gallery/
