Sliding Window Attention (SWA)
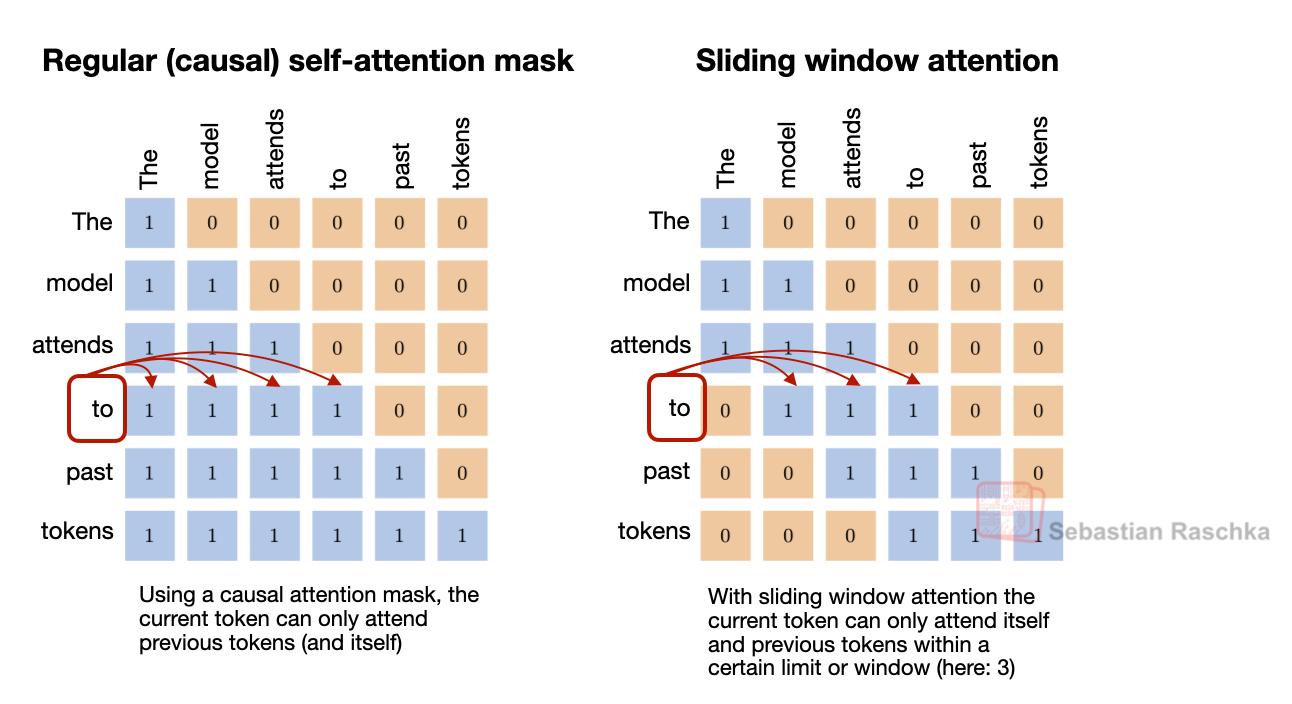
Sliding window attention reduces the memory and compute cost of long-context inference by limiting how many previous tokens each position can attend to. Instead of attending to the entire prefix, each token only attends to a fixed window of recent tokens around its position. Because attention is restricted to a local token neighborhood, this mechanism is often referred to as local attention.
Some architectures combine these local layers with occasional global attention layers so that information can still propagate across the entire sequence.
What changes
Selected layers only attend to a recent window instead of the entire context
Practical benefit
It reduces the cost and cache requirements of local layers while retaining occasional full-attention layers for long-range context
Example architectures
Gemma 3 27B, OLMo 3 32B, Xiaomi MiMo-V2-Flash, Arcee Trinity, Step 3.5 Flash, and Tiny Aya
Gemma 3 As A Reference Point
Gemma 3 is still one of the clearest recent SWA examples because it is easy to compare against Gemma 2. Gemma 2 already used a hybrid attention setup with a 1:1 ratio between local and global layers and a 4096-token window. Gemma 3 pushed this further to a 5:1 ratio and reduced the window size to 1024.
The key finding was not that local attention is cheaper, because that was already known. The more interesting takeaway from the Gemma ablation study was that using this more aggressively seemed to hurt modeling performance only slightly.
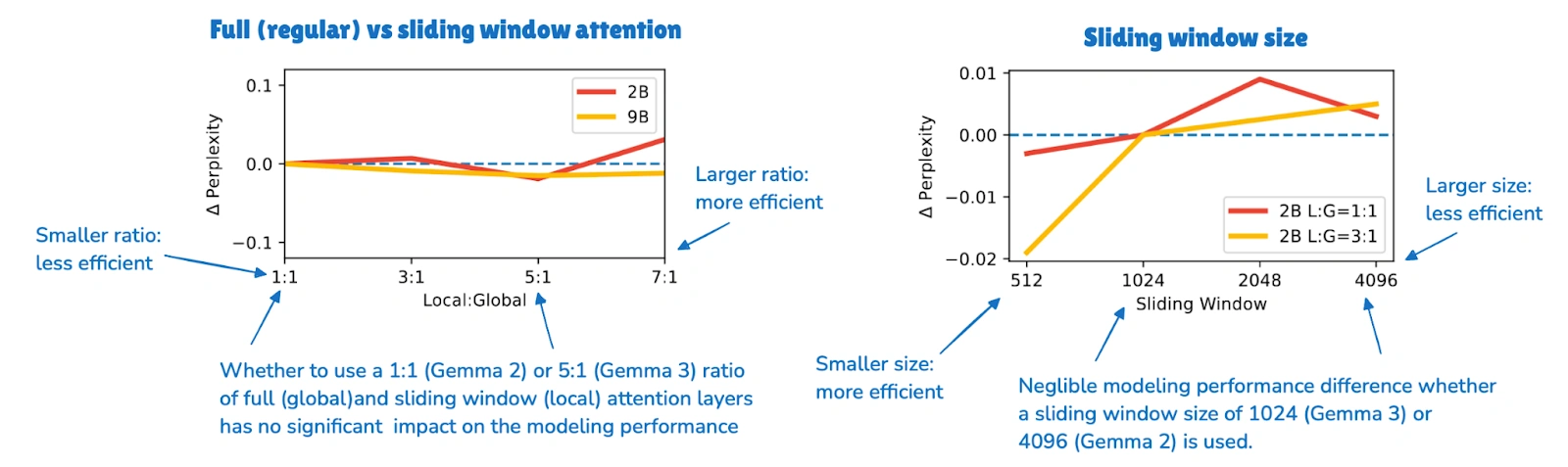
The Ratio And Window Size
In practice, saying that a model “uses SWA” does not mean it relies on SWA alone. What usually matters are the local-to-global layer pattern and the attention window size. The gallery includes several examples:
- Gemma 3 and Xiaomi use a 5:1 local-to-global pattern.
- OLMo 3 and Arcee Trinity use a 3:1 pattern.
- Xiaomi also uses a window size of 128, which is much smaller, and therefore more aggressive, than Gemma’s 1024.
Those details change how aggressively a model trades global visibility for efficiency. In that sense, SWA is less a single architecture choice than a design knob that can be tuned more or less aggressively.
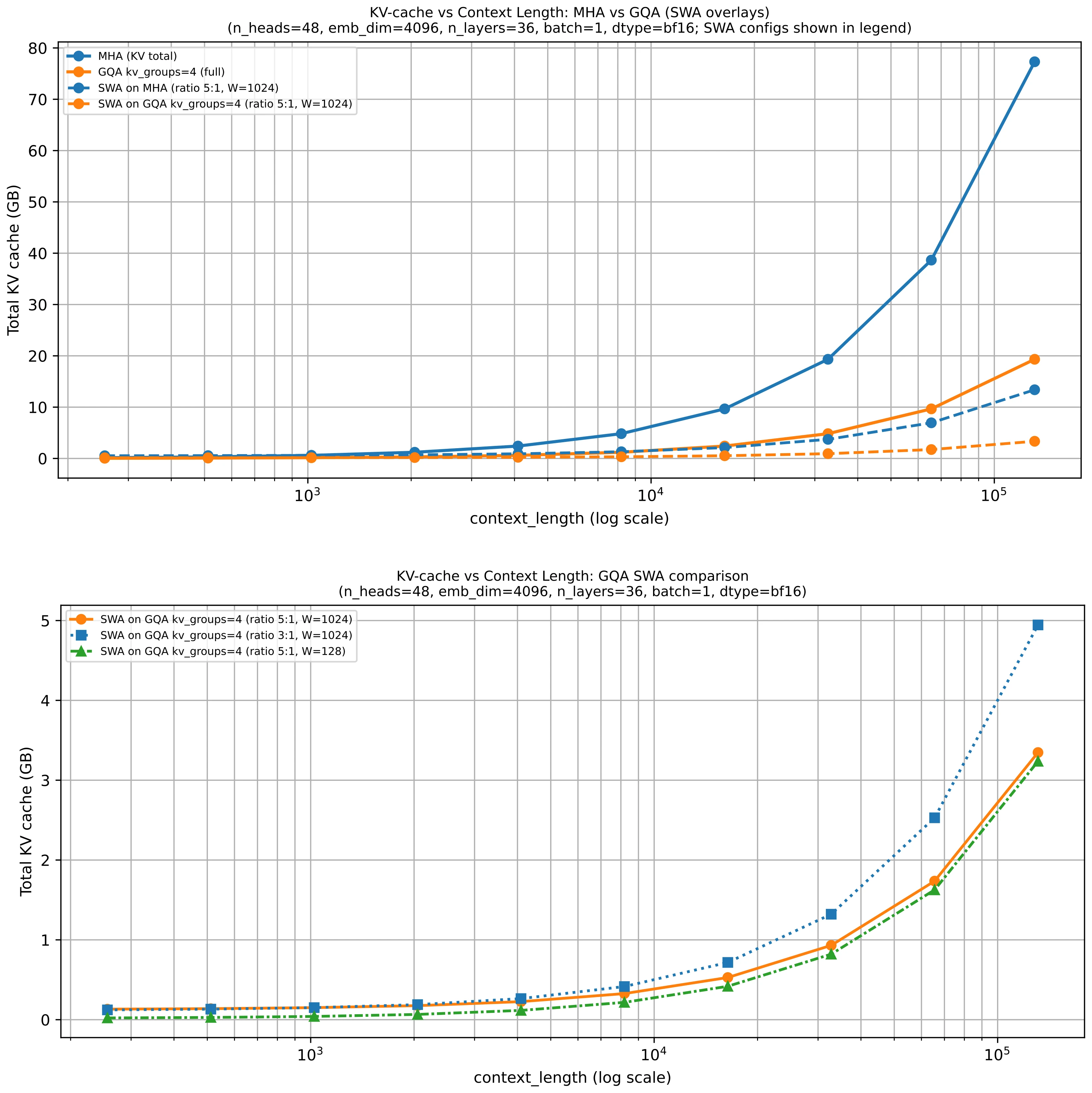
Why It Often Appears With GQA
SWA often appears together with GQA because the two ideas address different parts of the same inference problem. SWA reduces how much context a local layer has to consider. GQA reduces how much key-value state each token contributes to the cache.
That is why many recent dense models use both rather than treating them as alternatives. Gemma 3 is again a good reference point here, since it combines sliding window attention with grouped-query attention in the same architecture.
Sources