Grouped-Query Attention (GQA)
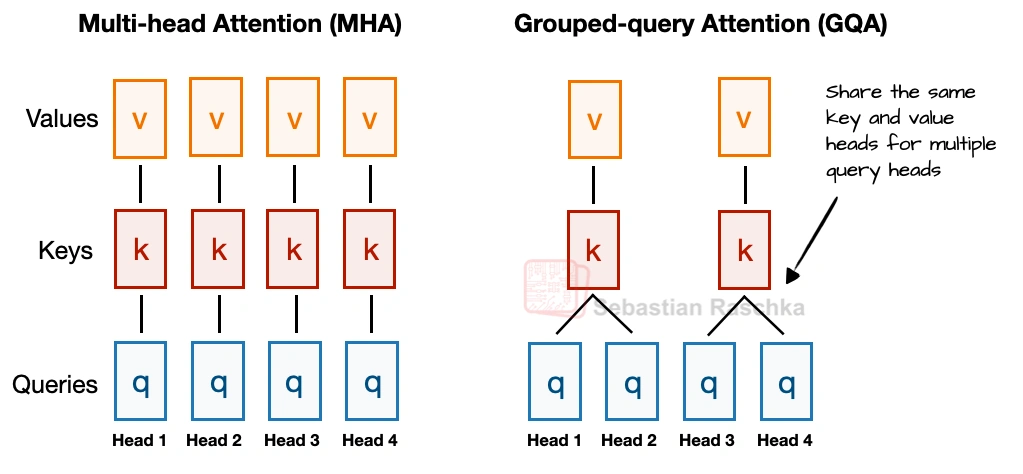
Grouped-query attention is an attention variant derived from standard multi-head attention. It was introduced in the 2023 paper GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints by Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. Instead of giving every query head its own keys and values, it lets several query heads share the same key-value projections, which makes KV caching much cheaper without changing the overall decoder recipe very much.
What it optimizes
KV-cache size, memory bandwidth, and long-context inference cost
Practical benefit
It delivers most of the practical benefits of a leaner attention stack without changing the decoder recipe much
Example architectures
Dense:
Llama 3 8B,
Qwen3 4B,
Gemma 3 27B,
Mistral Small 3.1 24B,
SmolLM3 3B, and
Tiny Aya 3.35B.
Sparse:
Llama 4 Maverick,
Qwen3 235B-A22B,
Step 3.5 Flash 196B, and
Sarvam 30B.
Why GQA Became Popular
In the first architecture comparison article, I framed GQA as the new standard replacement for classic multi-head attention (MHA). The reason is that standard MHA gives every head its own keys and values, which is more optimal from a modeling perspective but expensive once we have to keep all of that state in the KV cache during inference.
In GQA, we keep a larger set of query heads, but we reduce the number of key-value heads and let multiple queries share them. That lowers both parameter count and KV-cache traffic without making drastic implementation changes like multi-head latent attention (MLA). In practice, that made it a very attractive operating point for labs that wanted something cheaper than MHA but simpler to implement than newer compression-heavy alternatives like MLA.
Memory Savings
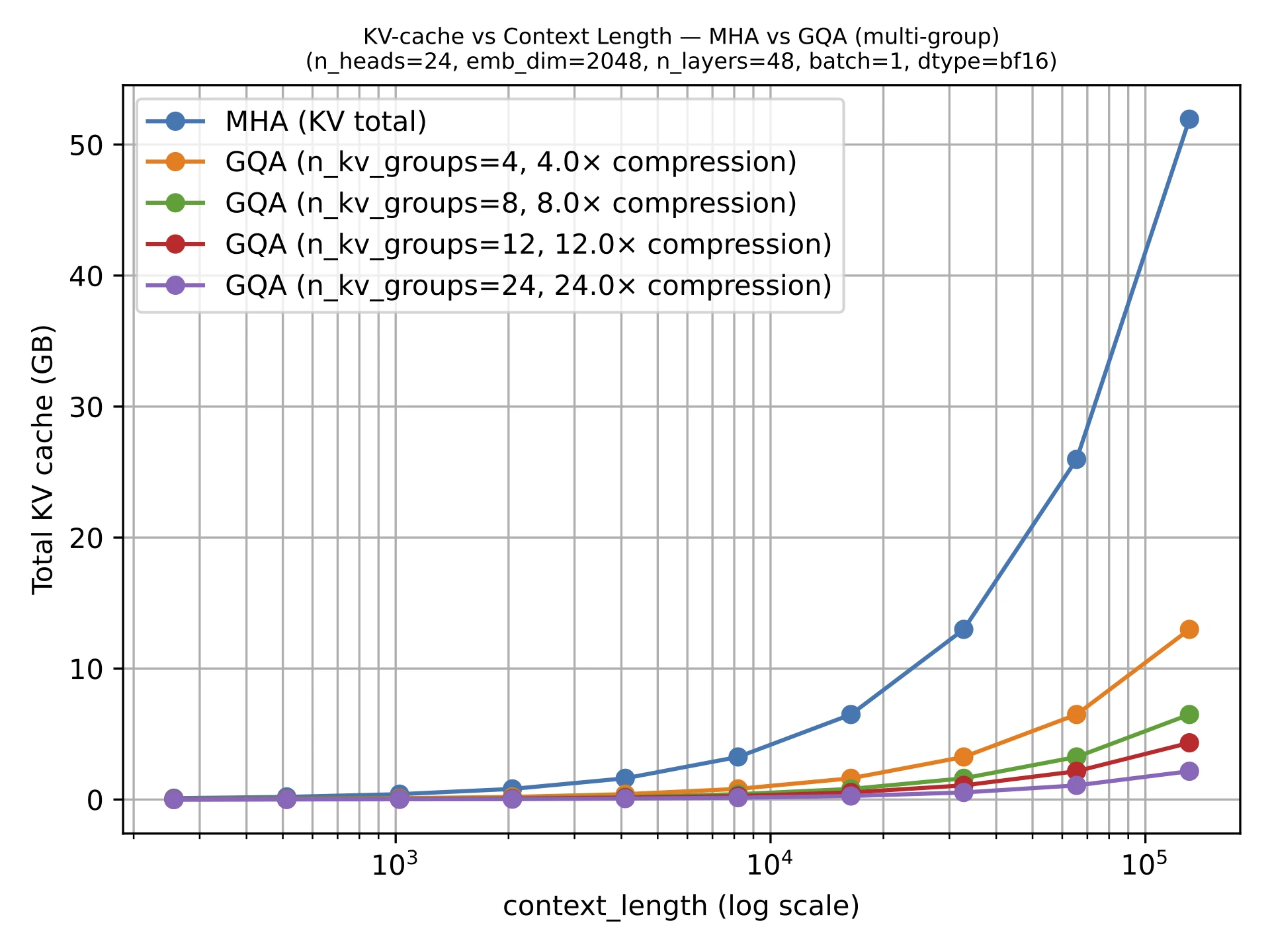
GQA results in big savings in KV storage and thus lower memory requirements, since the fewer key-value heads we keep per layer, the less cached state we need per token. That is why GQA becomes more useful as sequence length grows.
GQA is also a spectrum. If we reduce all the way down to one shared K/V group, we are effectively in multi-query attention territory, which is even cheaper but can hurt modeling quality more noticeably. The sweet spot is usually somewhere in between multi-query attention (1 shared group) and MHA (where K/V groups are equal to the number of queries), where the cache savings are large but the modeling degradation relative to MHA stays modest.
Why GQA Still Matters In 2026
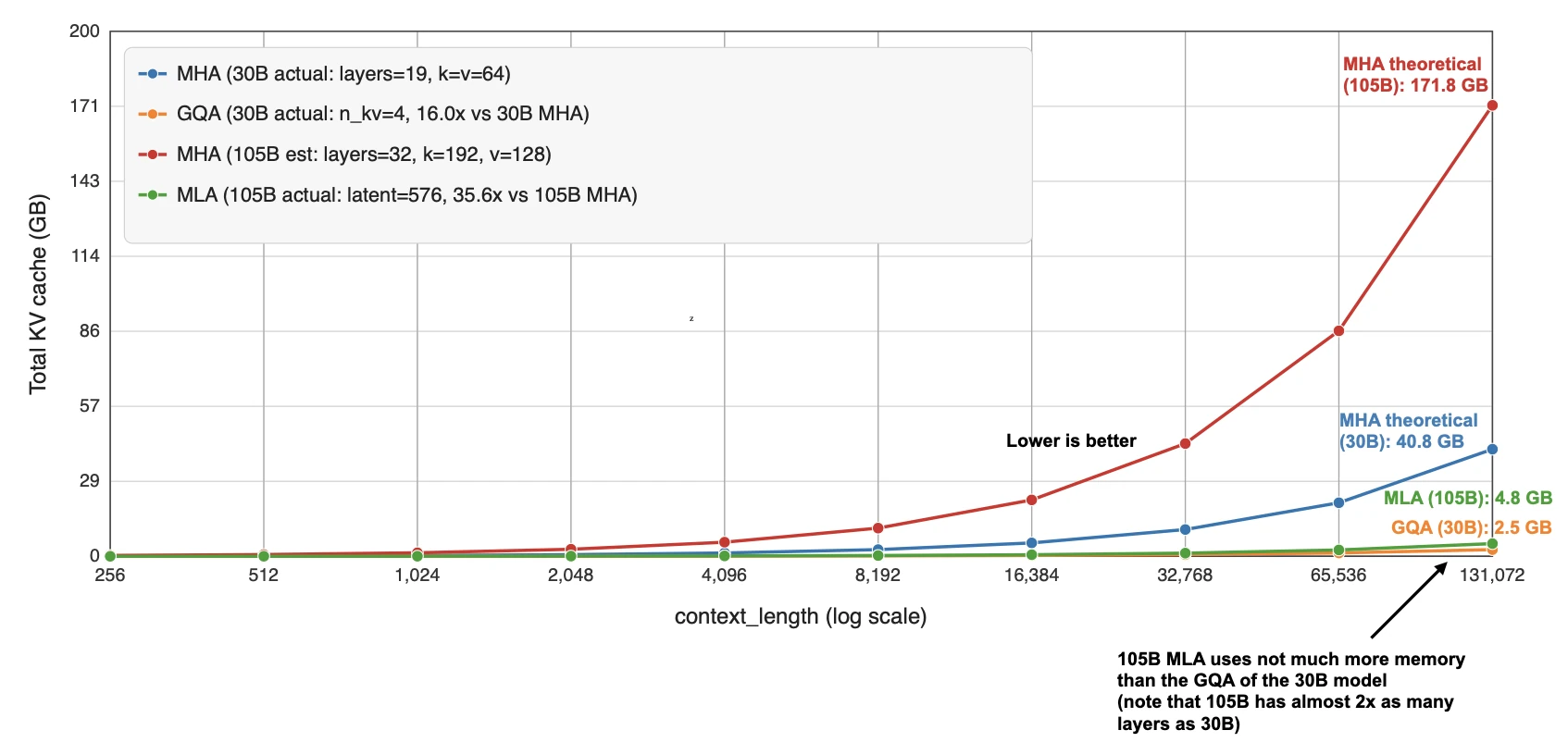
More advanced variants such as MLA are becoming popular because they can offer better modeling performance at the same KV efficiency levels (e.g., as discussed in the ablation studies of the DeepSeek-V2 paper), but they also involve a more complicated implementation. GQA remains appealing precisely because it is robust, easier to implement, and also easier to train (since there are fewer hyperparameter tunings necessary, based on my experience).
That is why some of the newer releases still stay deliberately classic here. E.g., in my Spring Architectures article, I mentioned that MiniMax M2.5 and Nanbeige 4.1 as models that remained very classic, using only grouped-query attention without piling on other efficiency tricks. Sarvam is a particularly useful comparison point as well: the 30B model keeps classic GQA, while the 105B version switches to MLA.
Sources