Multi-Head Latent Attention (MLA)
The motivation behind Multi-head Latent Attention (MLA) is similar to Grouped-Query Attention (GQA). Both are solutions for reducing KV-cache memory requirements. The difference between GQA and MLA is that MLA shrinks the cache by compressing what gets stored rather than by reducing how many K/Vs are stored by sharing heads.
MLA, originally proposed in the DeepSeek-V2 paper, became such a defining DeepSeek-era idea (especially after DeepSeek-V3 and R1). It is more complicated to implement than GQA, more complicated to serve, but nowadays also often more compelling once model size and context length get large enough that cache traffic starts to dominate, because at the same rate of memory reduction, it could maintain better modeling performance (more on that later).
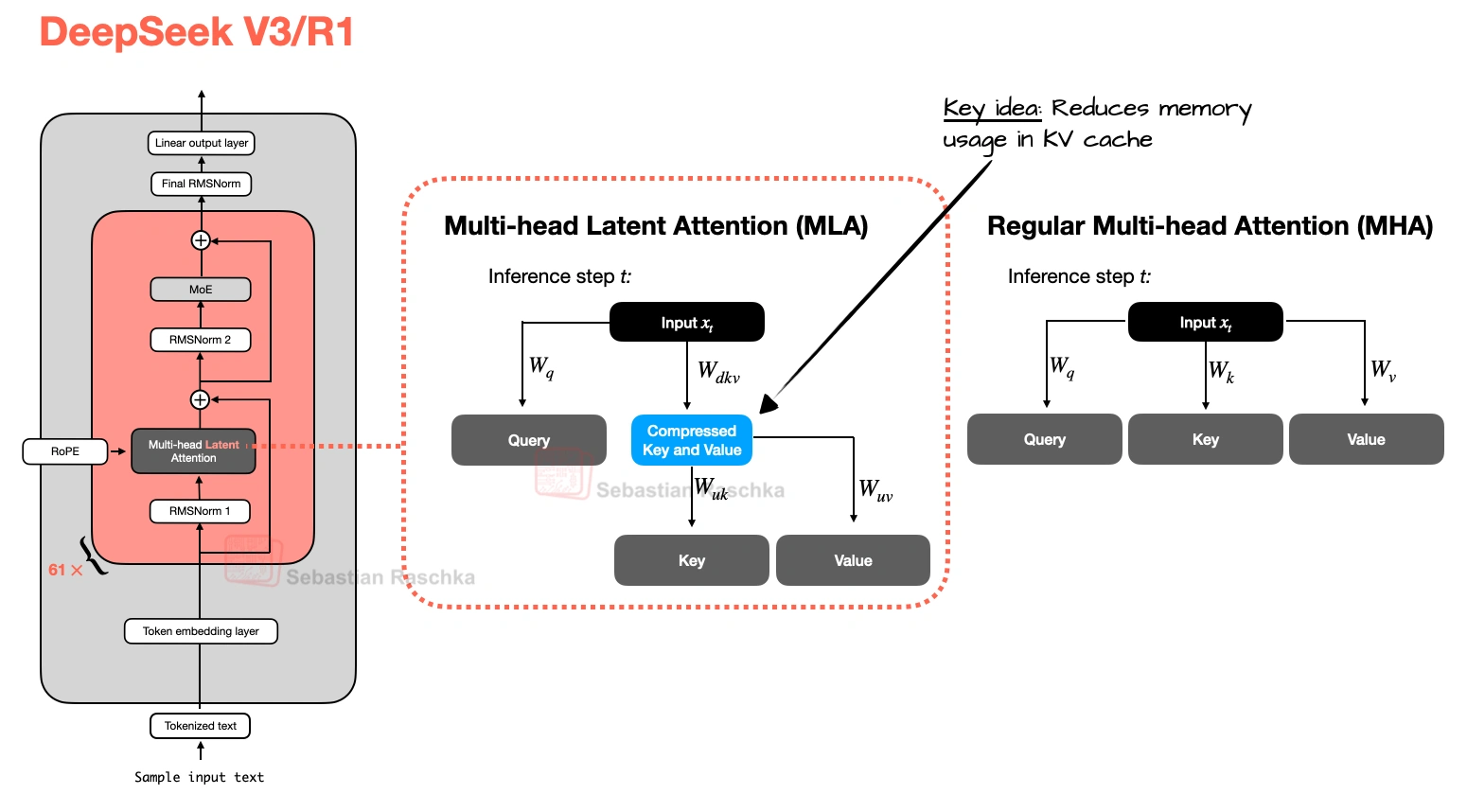
Core move
Compress keys and values before they enter the KV cache
Practical benefit
It can save KV-cache memory aggressively without the quality drop often associated with more extreme sharing schemes
Example architectures
DeepSeek V3, Kimi K2, GLM-5, Ling 2.5, LongCat-Flash-Lite, Mistral Large 3, and Sarvam 105B
Compression, Not Sharing
Instead of caching full-resolution key and value tensors as in MHA and GQA, MLA stores a latent representation and reconstructs the usable state when needed. Essentially, it is a cache compression strategy embedded inside attention, as illustrated in the previous figure.
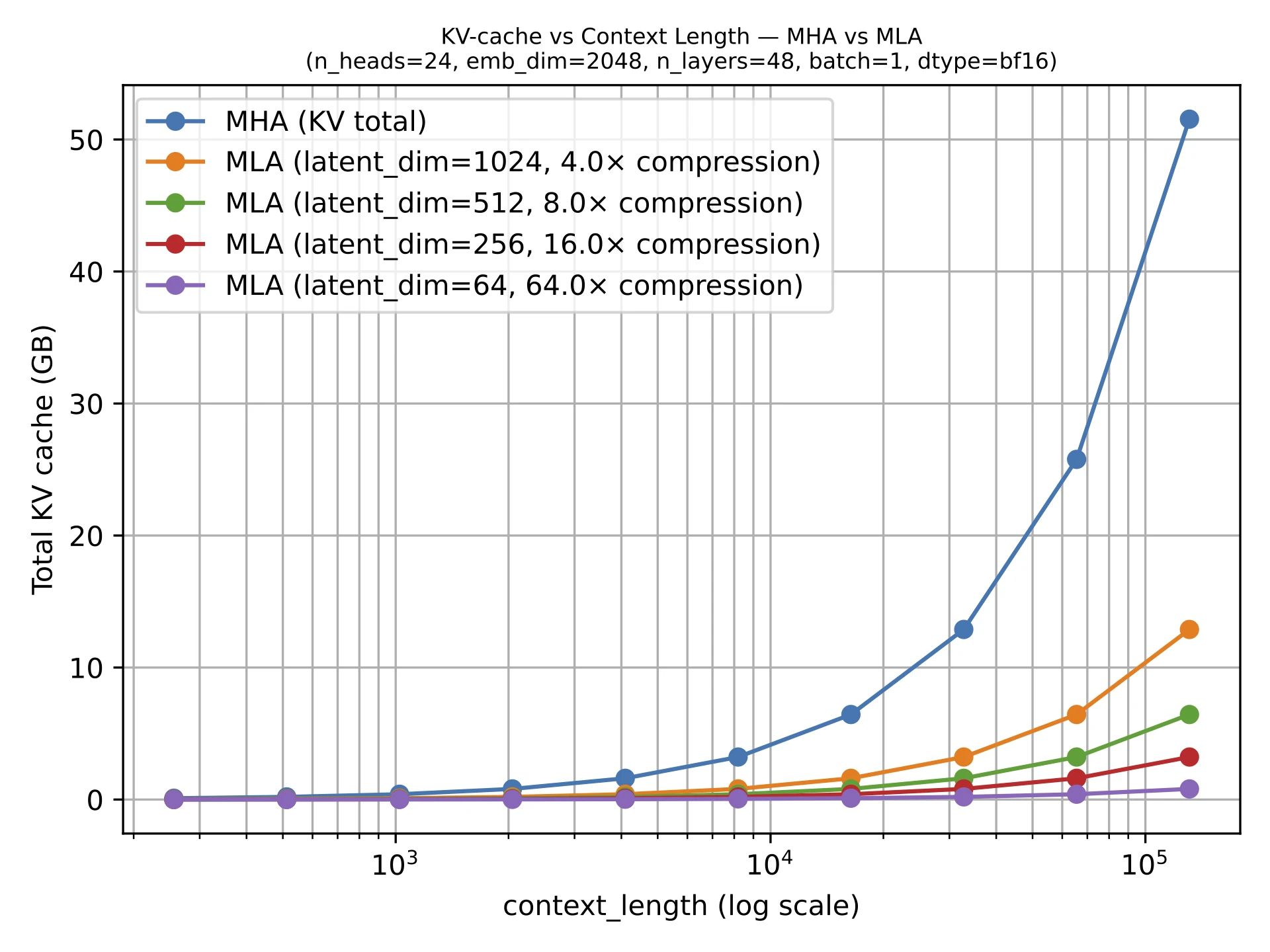
The figure below shows the savings compared to regular MHA.
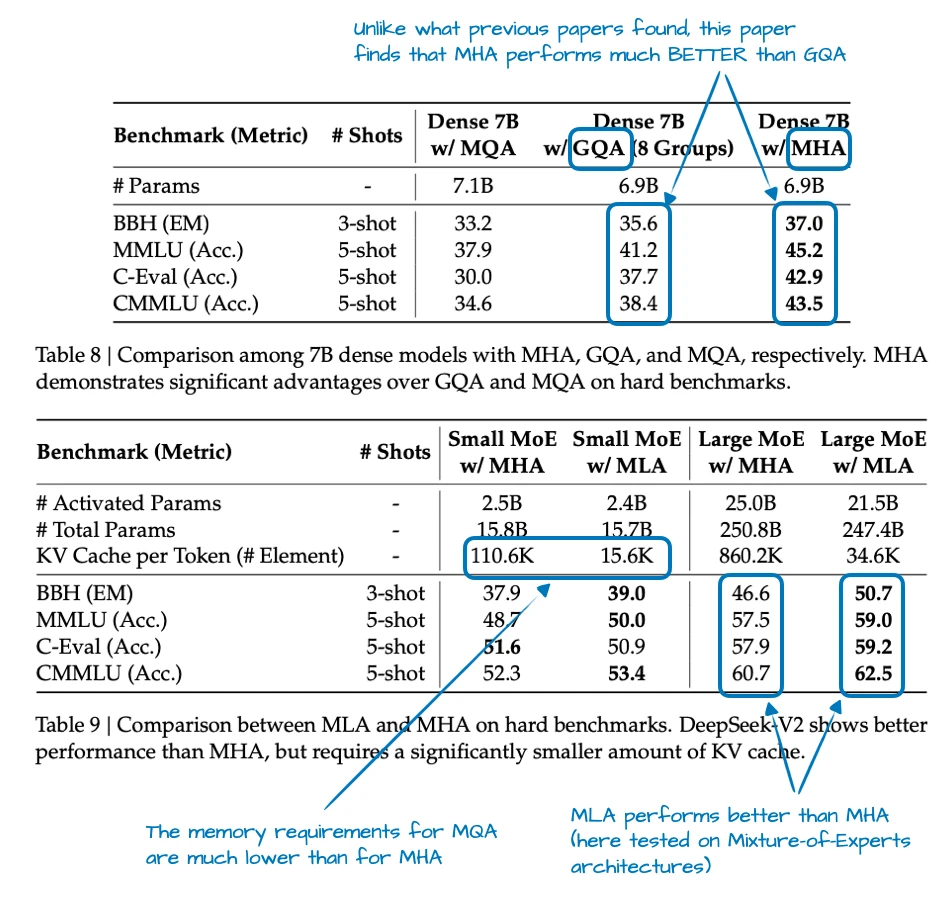
Ablation Studies
The DeepSeek-V2 paper provided some ablations where GQA looked worse than MHA in terms of modeling performance, while MLA held up much better and could even outperform MHA when tuned carefully. That is a much stronger justification than “it saves memory.”
In other words, MLA is a preferable attention mechanism for DeepSeek not just because it was efficient, but because it looked like a quality-preserving efficiency move at large scale. (But colleagues tell me that MLA only works well at a certain size. For smaller models, let’s say <100B, GQA seems to work better, or, is at least easier to tune and get right.)
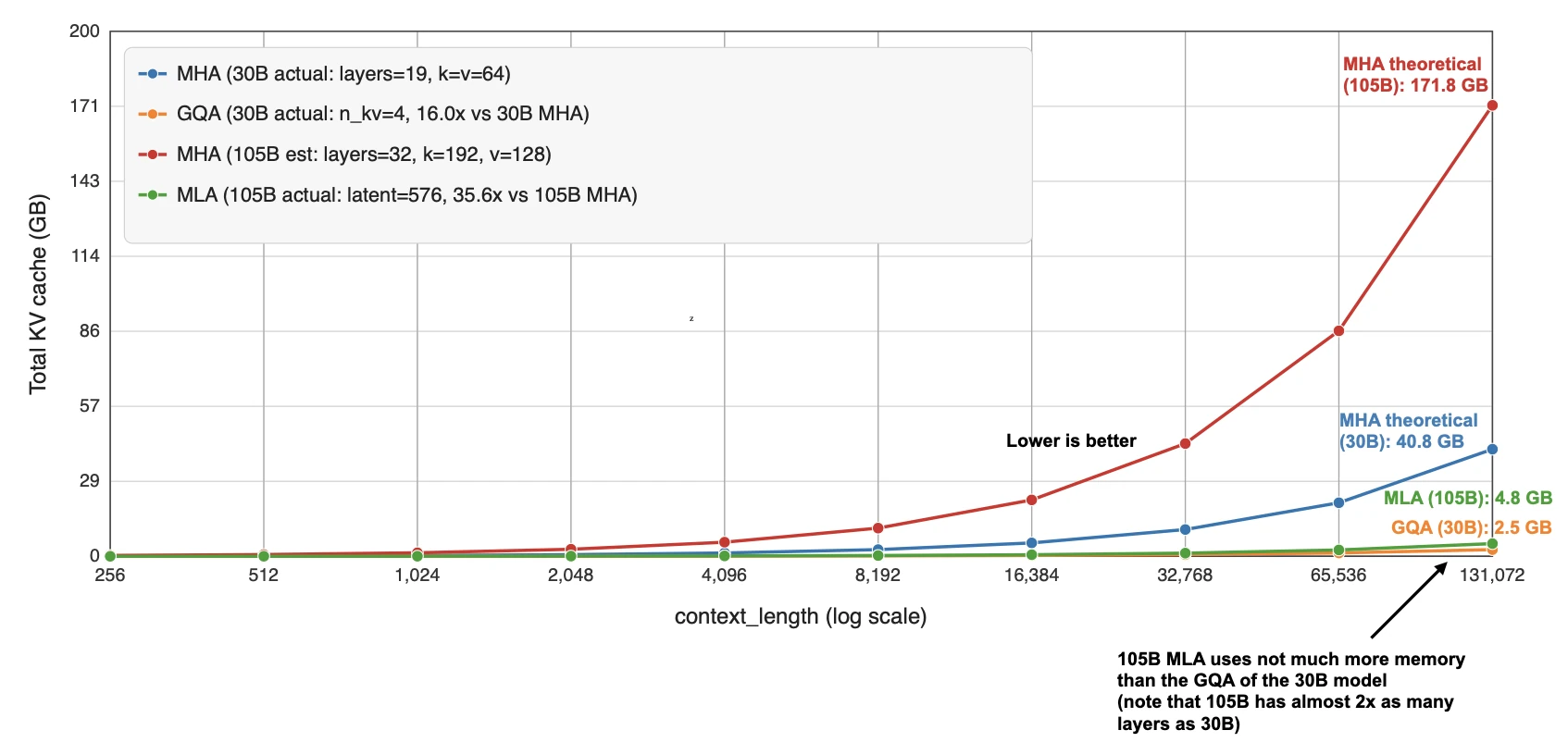
How It Spread After DeepSeek
Once DeepSeek V3/R1, V3.1 etc. normalized the design after its introduction in V2, it started showing up in a second wave of architectures. Kimi K2 kept the DeepSeek recipe and scaled it up. GLM-5 adopted MLA together with DeepSeek Sparse Attention (from DeepSeek V3.2). Ling 2.5 paired MLA with a linear-attention hybrid. Sarvam released two models where the 30B model stayed with classic GQA and the 105B model switched to MLA.
That last pair is particularly useful as it puts the technical-complexity discussion aside. I.e., the Sarvam team implemented both variants and deliberately chose to then use GQA for one variant and MLA for the other. So, in a sense, that makes MLA feel less like a theoretical alternative and more like a concrete architectural upgrade path once a family scales up.
Sources