DeepSeek Sparse Attention
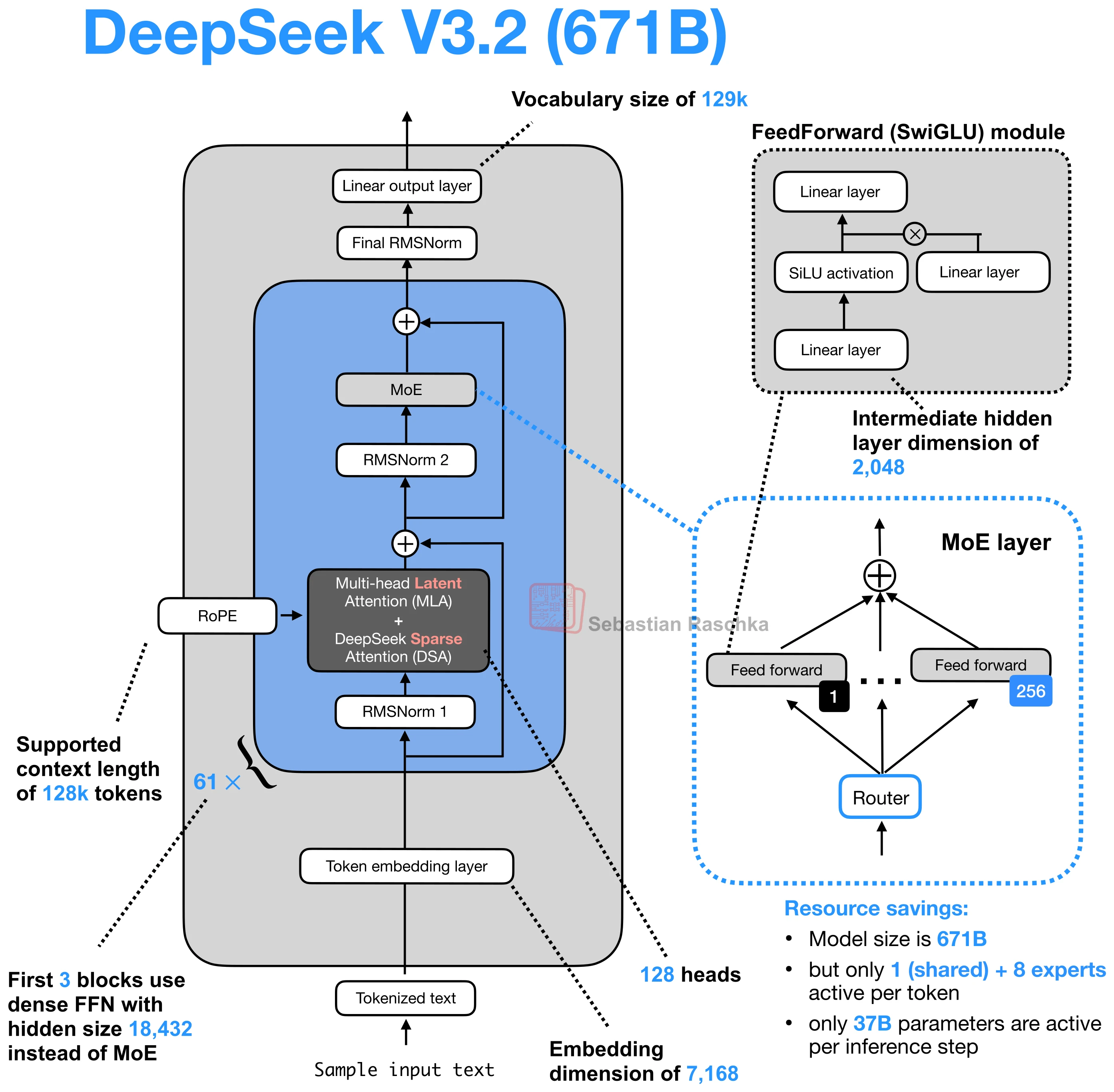
DeepSeek Sparse Attention is one of the architectural changes that appeared in the DeepSeek V3.2 line and later showed up again in GLM-5.
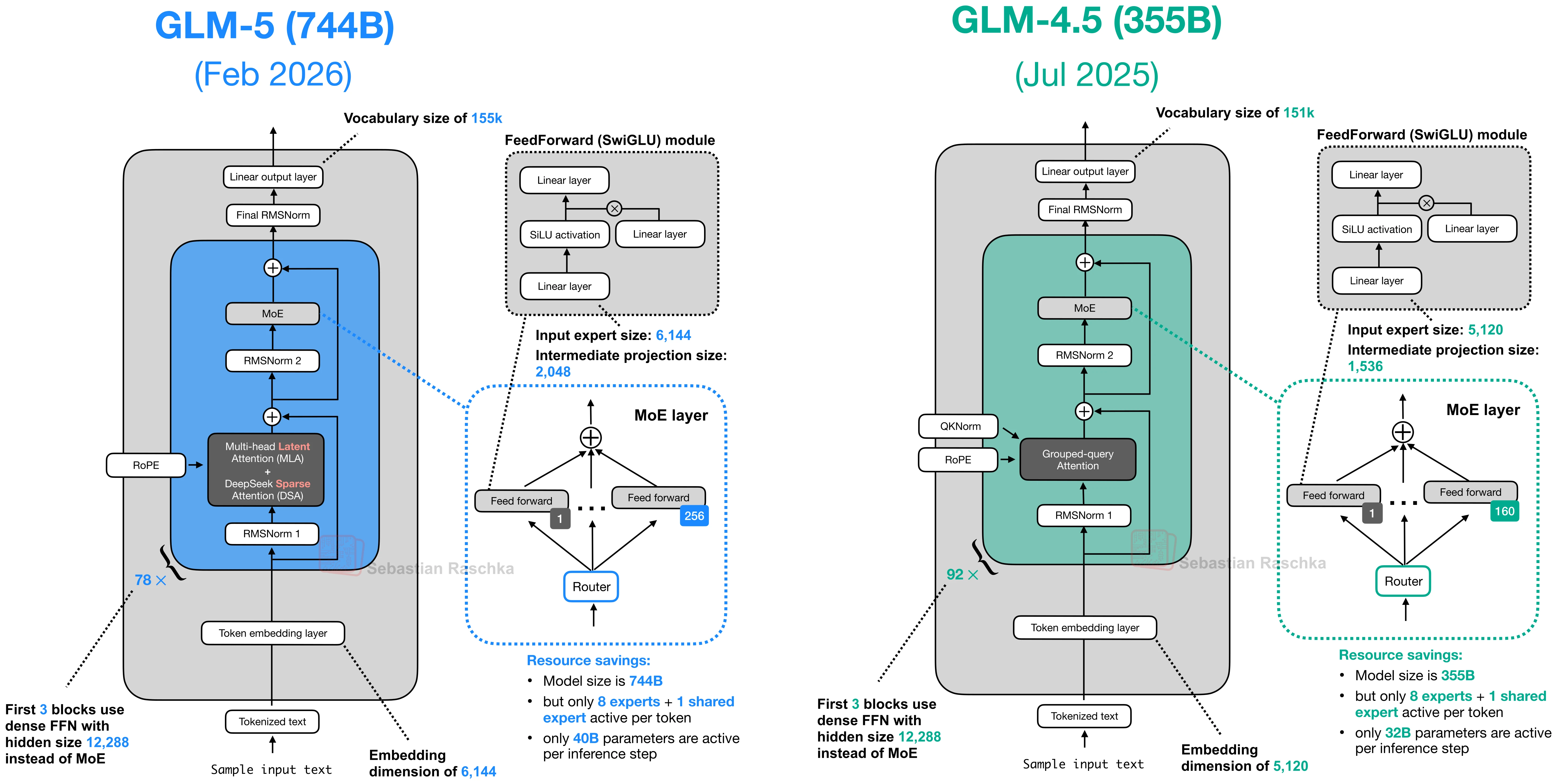
In the gallery, it is best read as part of a broader efficiency-oriented stack. DeepSeek V3.2 combines it with Multi-head Latent Attention (MLA), and GLM-5 adopts the same pair for the same general reason, namely, reducing inference cost when context lengths get large.
Summary
Use a lightning indexer and token selector to keep only a learned subset of past tokens
Practical benefit
Reduce long-context attention cost without hard-coding a fixed local window
Example architectures
DeepSeek V3.2 and GLM-5
Changes Relative To Sliding-Window Attention
Let’s briefly take a step back and start with sliding-window attention. In sliding-window attention, the current token does not attend to the full prefix but only to a fixed local window. This is the same broad idea behind DeepSeek Sparse Attention, where each token also only attends to a subset of previous tokens.
However, the selected tokens are not determined by a fixed-width local window. Instead, DeepSeek Sparse Attention uses a learned sparse pattern. In short, it uses an indexer-plus-selector setup, where a lightning indexer computes relevance scores, and a token selector keeps only a smaller set of high-scoring past positions.
The way the subset of tokens is selected is the main difference from sliding-window attention. Sliding-window attention hard-codes locality. DeepSeek Sparse Attention still limits attention to a subset, but it lets the model decide which prior tokens are worth revisiting.
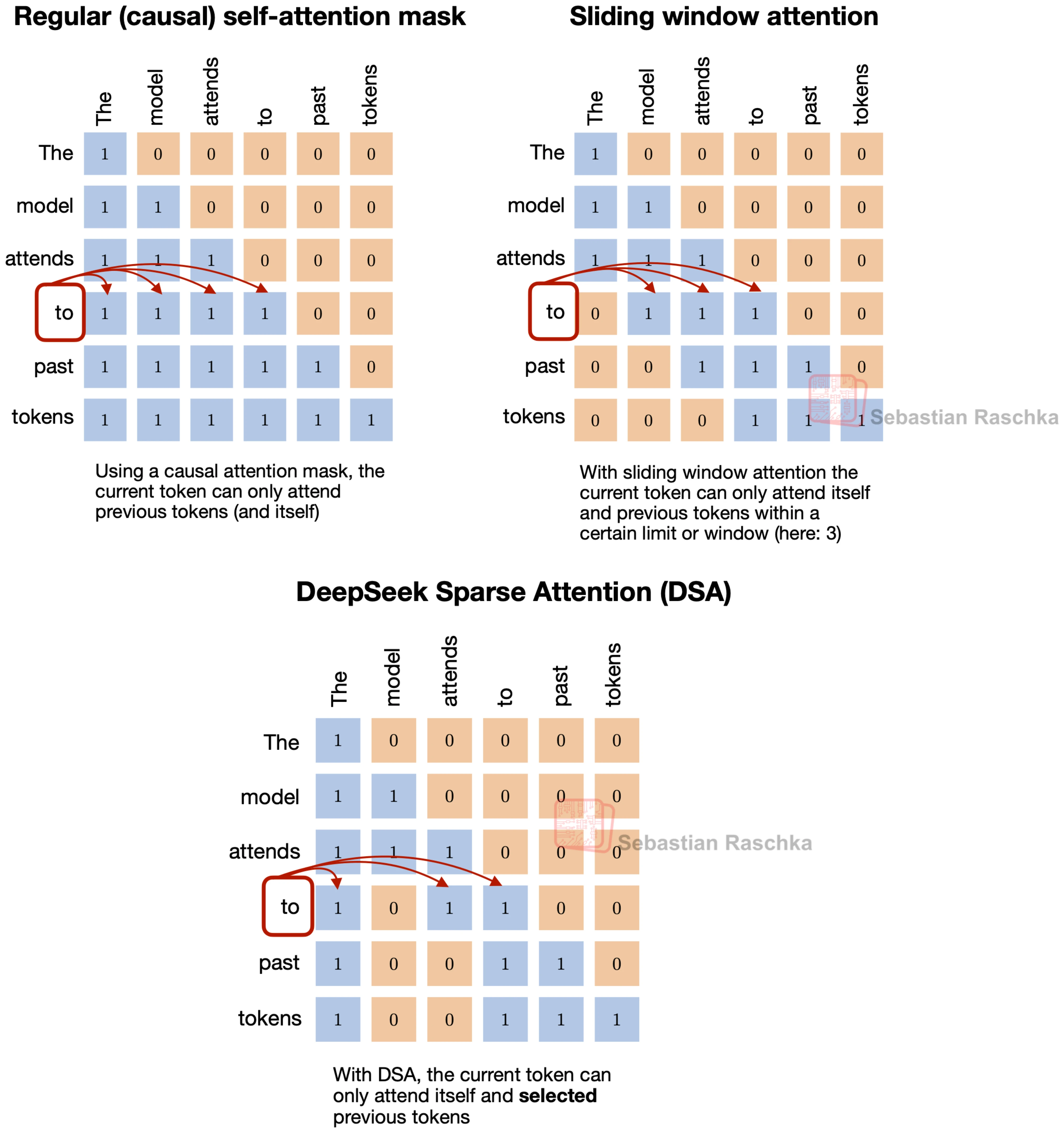
DeepSeek Sparse Attention still avoids full-prefix attention, but unlike sliding-window attention, the kept positions do not have to form one contiguous local block. They can come from different parts of the prefix if the indexer and selector score them highly enough.
That is why DeepSeek Sparse Attention is not just a small adjustment to a standard decoder block like sliding-window attention, but a more specific decision about how the model should revisit prior context.
DeepSeek Sparse Attention and MLA
DeepSeek V3.2 uses both Multi-head Latent Attention (MLA) and DeepSeek Sparse Attention. MLA reduces KV-cache cost by compressing what gets stored. DeepSeek Sparse Attention reduces how much of the prior context the model has to revisit. Put differently, one optimizes the cache representation, the other optimizes the attention pattern on top of it.
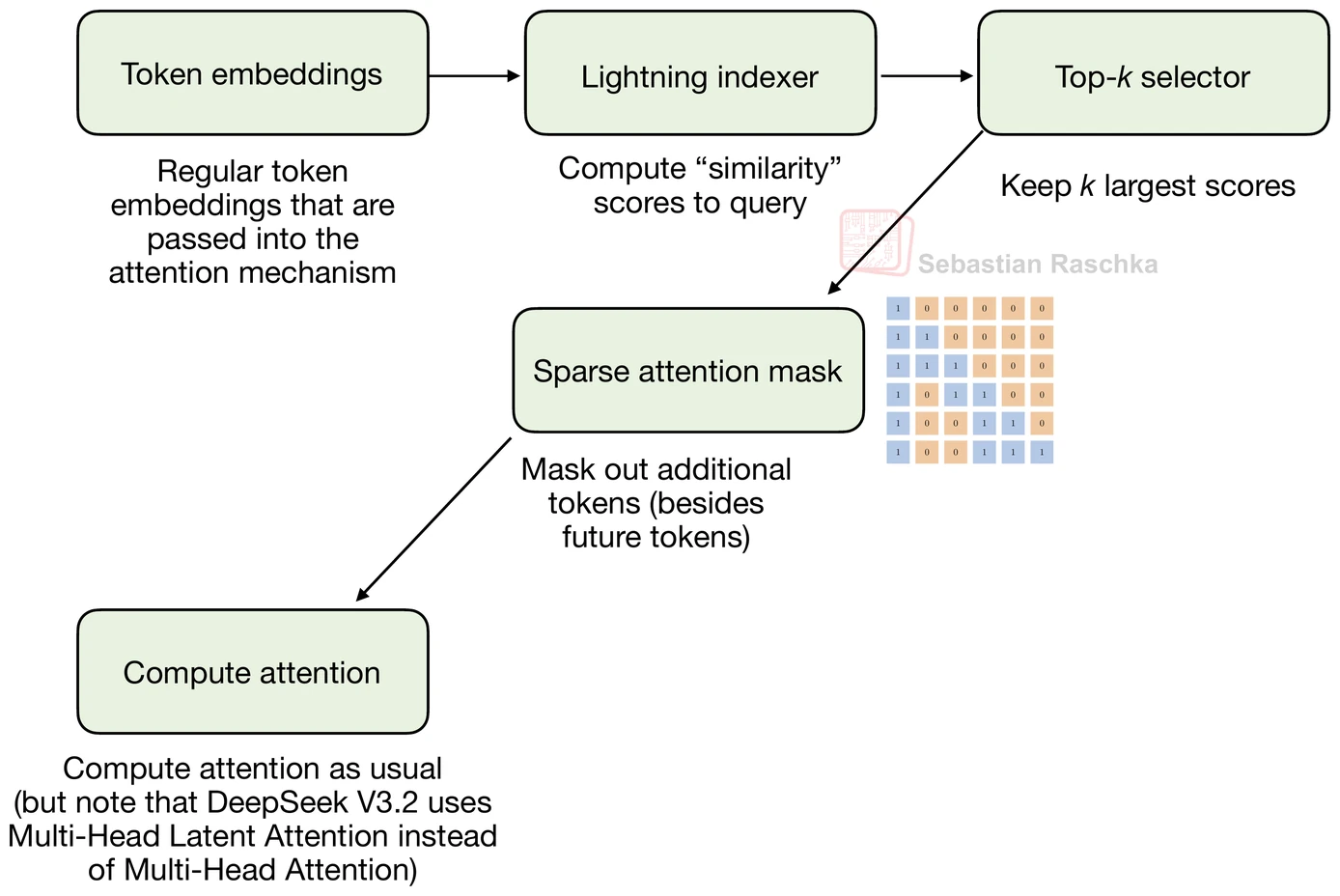
The sparse pattern is not random. The first stage is a lightning indexer that scores previous tokens for each new query token. It uses MLA’s compressed token representations and computes a learned similarity score over the prior context, so the model can rank which earlier positions are worth revisiting.
The second stage is a token selector. It keeps only a smaller high-scoring subset, for example, a top-k set of past
positions, and turns that subset into the sparse attention mask. So the main point is that DeepSeek Sparse Attention
does not hard-code the sparsity pattern. It learns which past tokens to keep.
DeepSeek Sparse Attention is relatively new and relatively complicated to implement, which is why it has not been so widely adopted as Grouped-Query Attention (GQA) yet.
Sources