No Positional Embeddings (NoPE)
NoPE refers to omitting explicit positional information injection in selected attention layers.
In practice, the relevant modern version is usually not “remove all positional encoding everywhere.” Instead, models tend to omit RoPE only in certain layers and keep it in others.
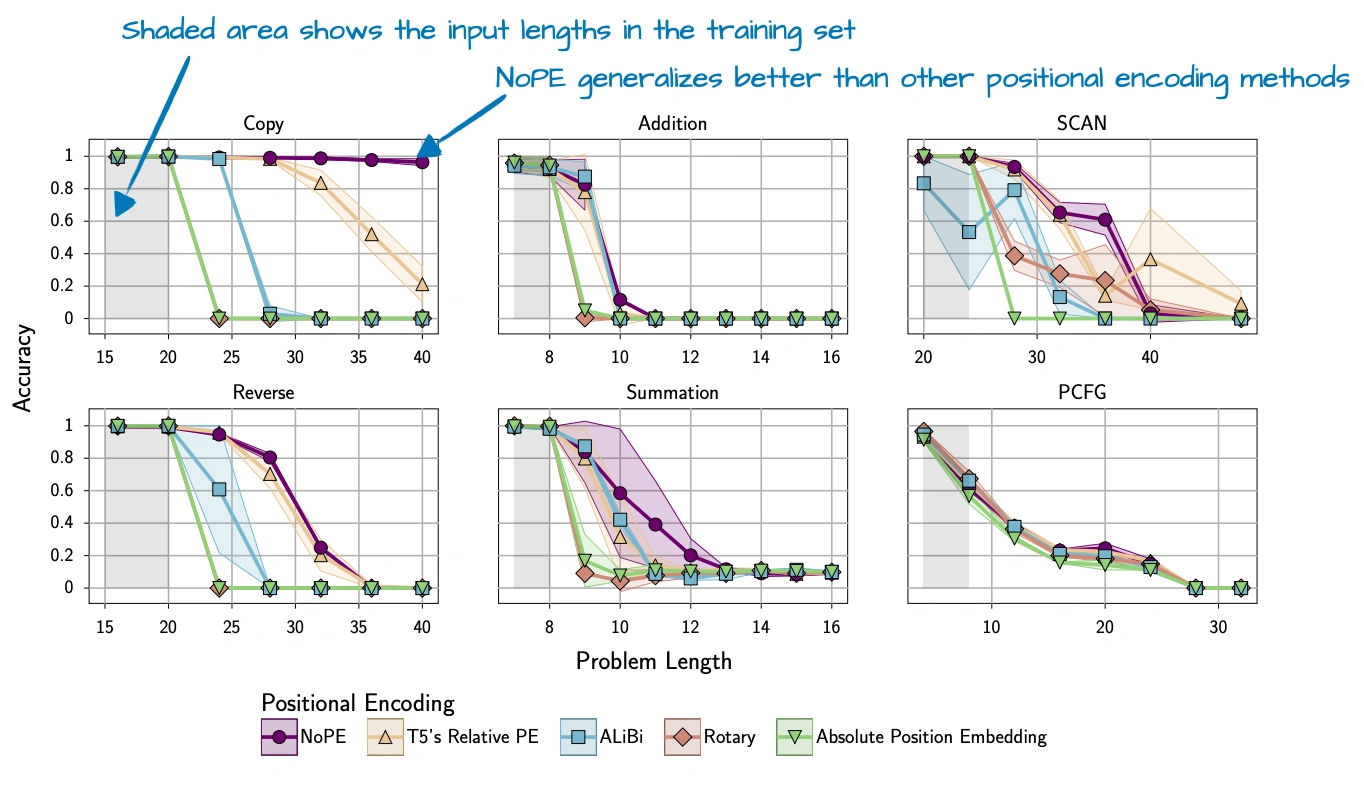
Why NoPE Can Still Work
The obvious question is how a model can keep track of token order if no positional signal is added. The key point, as discussed in the original NoPE paper, is that causal generation still imposes an ordering structure. A token can attend only to earlier tokens, not future ones.
So even without explicit positional embeddings, the computation is still directional. This does not mean that explicit positional information is useless. It only means that some layers may not need as much of it as we might expect.
The Practical Version Is Usually Mixed
SmolLM3 was a good recent example because it does not remove RoPE everywhere. Instead, it omits it in every fourth layer. Tiny Aya and Arcee Trinity use a similar idea in a slightly different way by mixing NoPE and RoPE across different attention patterns.
That is the useful practical takeaway. NoPE is usually not presented as a whole replacement for positional encoding, but as a selective design choice in parts of the stack where explicit position may be less necessary or less convenient.
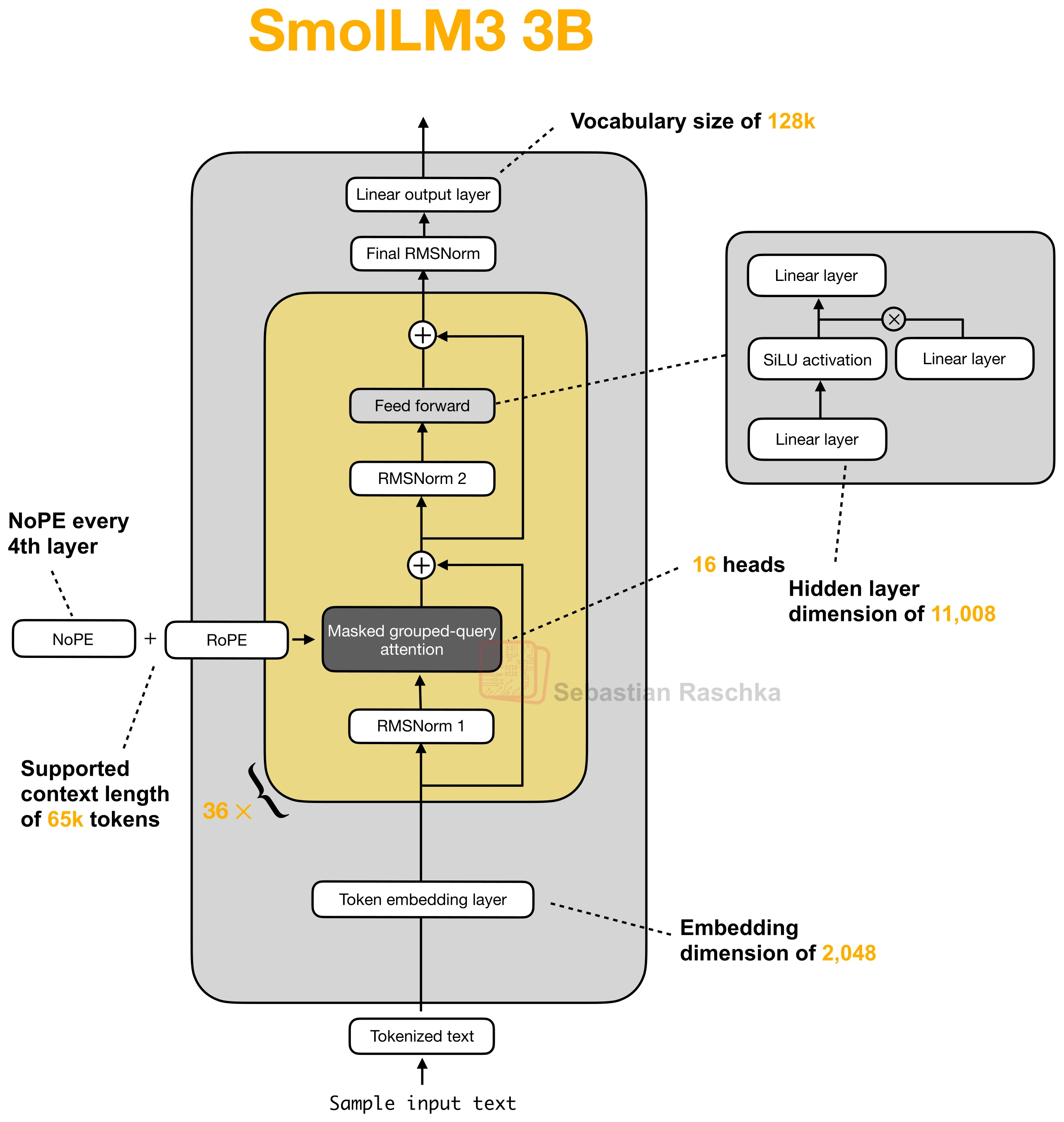
Why Models Still Keep RoPE Elsewhere
Recent hybrid and long-context models often keep RoPE in local or sliding-window attention layers while dropping it in selected global-attention layers. Kimi Linear is one example from the article, where its MLA layers use NoPE, while the positional bias is effectively handled by the linear-attention side.
This is also why NoPE tends to appear together with other architecture choices rather than by itself. In many recent models, it is part of a broader hybrid-attention setup.
Sources