QK-Norm
QK-Norm looks like a relatively negligible architecture change. It essentially just adds an extra RMSNorm for the queries and keys inside the attention mechanism. But it’s become a relatively popular technique to stabilize the training somewhat.
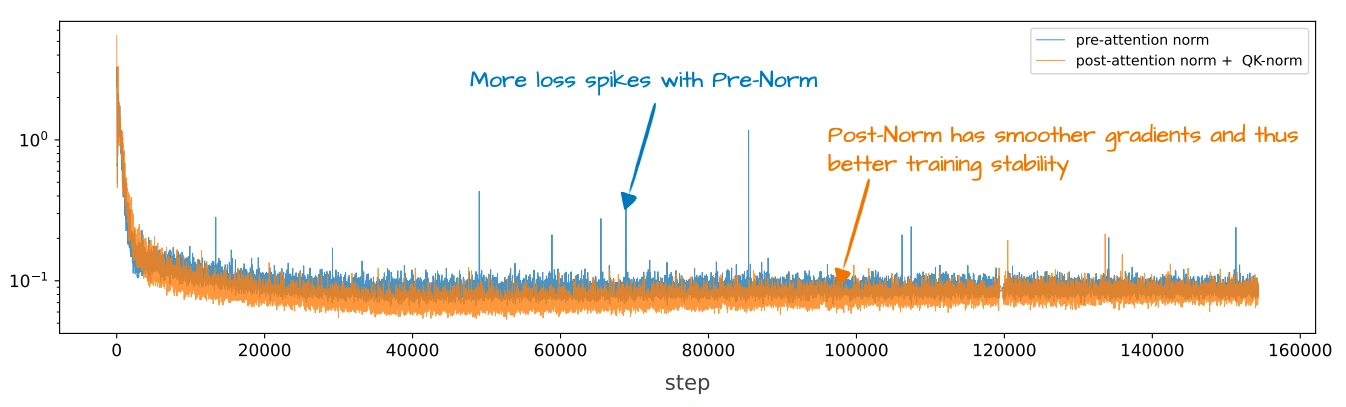
The plot above is the best ablation study I could find. However, it’s hard to say how much of the loss spike reduction is due to moving from Pre- to Post-norm and how much is due to adding QK-norm.
A Stabilizer, Not An Efficiency Trick
QK-Norm is easy to undersell because it sounds like “just another RMSNorm layer.” But its placement is what makes it interesting. It sits inside attention and normalizes the query and key projections before RoPE and before the dot products are computed. That means it is directly shaping the vectors that set the attention scores.
In code, the change is literally the extra normalization layers plus two lines in forward:
class GroupedQueryAttention(nn.Module):
def __init__(self, ..., qk_norm=True):
# ...
if qk_norm:
self.q_norm = RMSNorm(head_dim, eps=1e-6)
self.k_norm = RMSNorm(head_dim, eps=1e-6)
else:
self.q_norm = self.k_norm = None
# ...
def forward(self, x, mask, cos, sin):
# Apply projections
queries = self.W_query(x)
keys = self.W_key(x)
values = self.W_value(x)
# ...
# Optional QK normalization
if self.q_norm:
queries = self.q_norm(queries)
if self.k_norm:
keys = self.k_norm(keys)
# Apply RoPE
queries = apply_rope(queries, cos, sin)
keys = apply_rope(keys, cos, sin)
# ...
(See the Qwen3 from-scratch implementation for a full working example.)
So while GQA, MLA, and SWA are about inference efficiency, QK-Norm is mostly about keeping the optimization process calm enough that large models train reliably.
What Changed After It Became Common
Once QK-Norm was normalized as a default, teams started to tweak it instead of debating whether to use it at all. MiniMax M2 used a per-head variation. Qwen3-Next moved toward a zero-centered variant inside its gated attention blocks.
However, Tiny Aya is interesting for the opposite reason, where the Cohere team explicitly dropped it because they found that it could interact badly with long-context behavior (as one of the developers pointed out to me).
Sources