Gated Attention
Gated attention is best understood as a modified full-attention block rather than as a separate attention family.
In the architectures covered here, it usually appears inside hybrid stacks that still keep an occasional full-attention layer for exact content retrieval, but add a few stability-oriented changes on top of an otherwise familiar scaled dot-product attention block.
Where It Appears
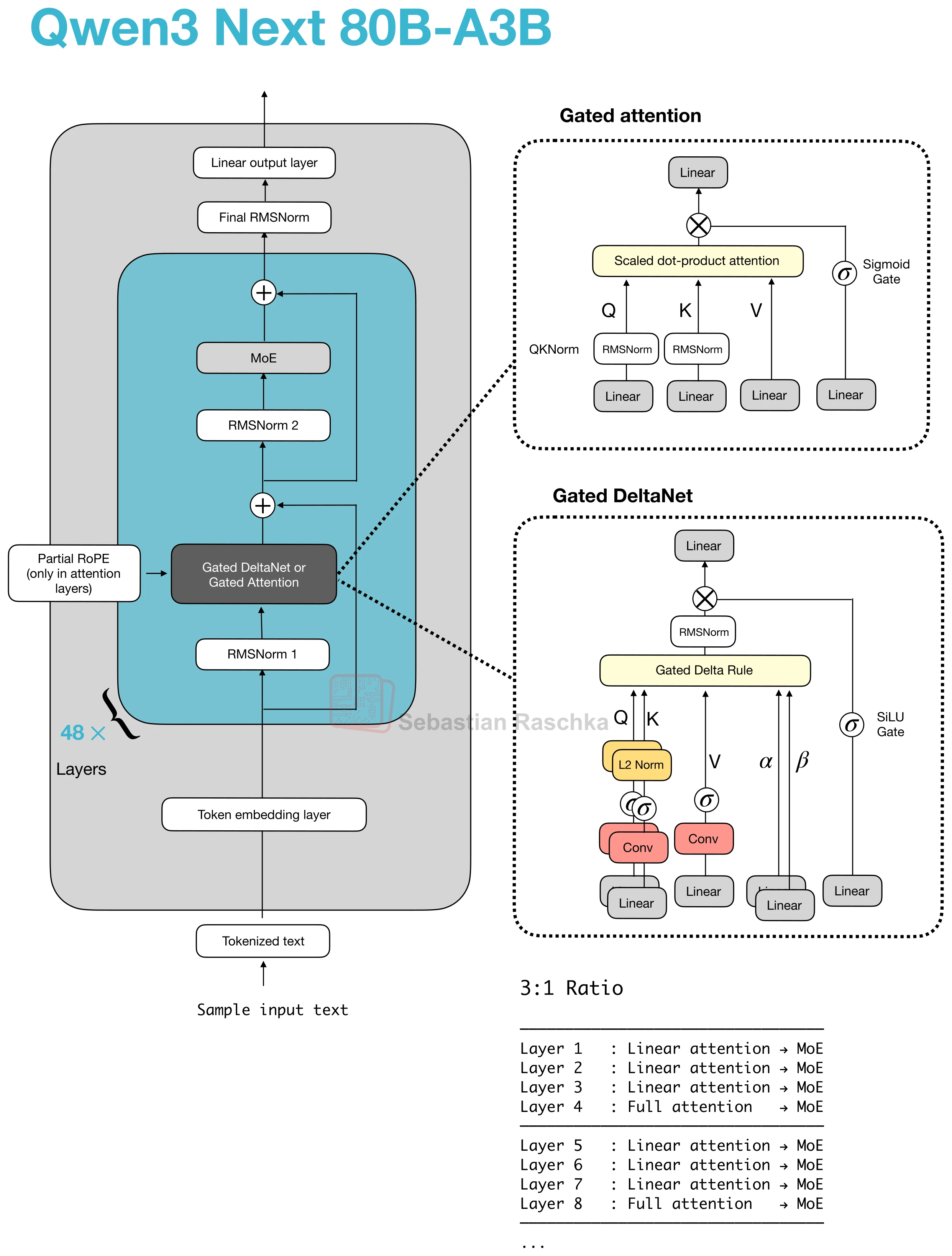
Qwen3-Next and Qwen3.5 architectures show that these recent hybrids do not replace attention everywhere. Instead, they replace most attention layers with a cheaper alternative and keep a smaller number of full-attention layers in the stack.
Those remaining full-attention layers are where gated attention typically appears. Qwen3-Next and Qwen3.5 use it together with Gated DeltaNet in a 3:1 pattern.
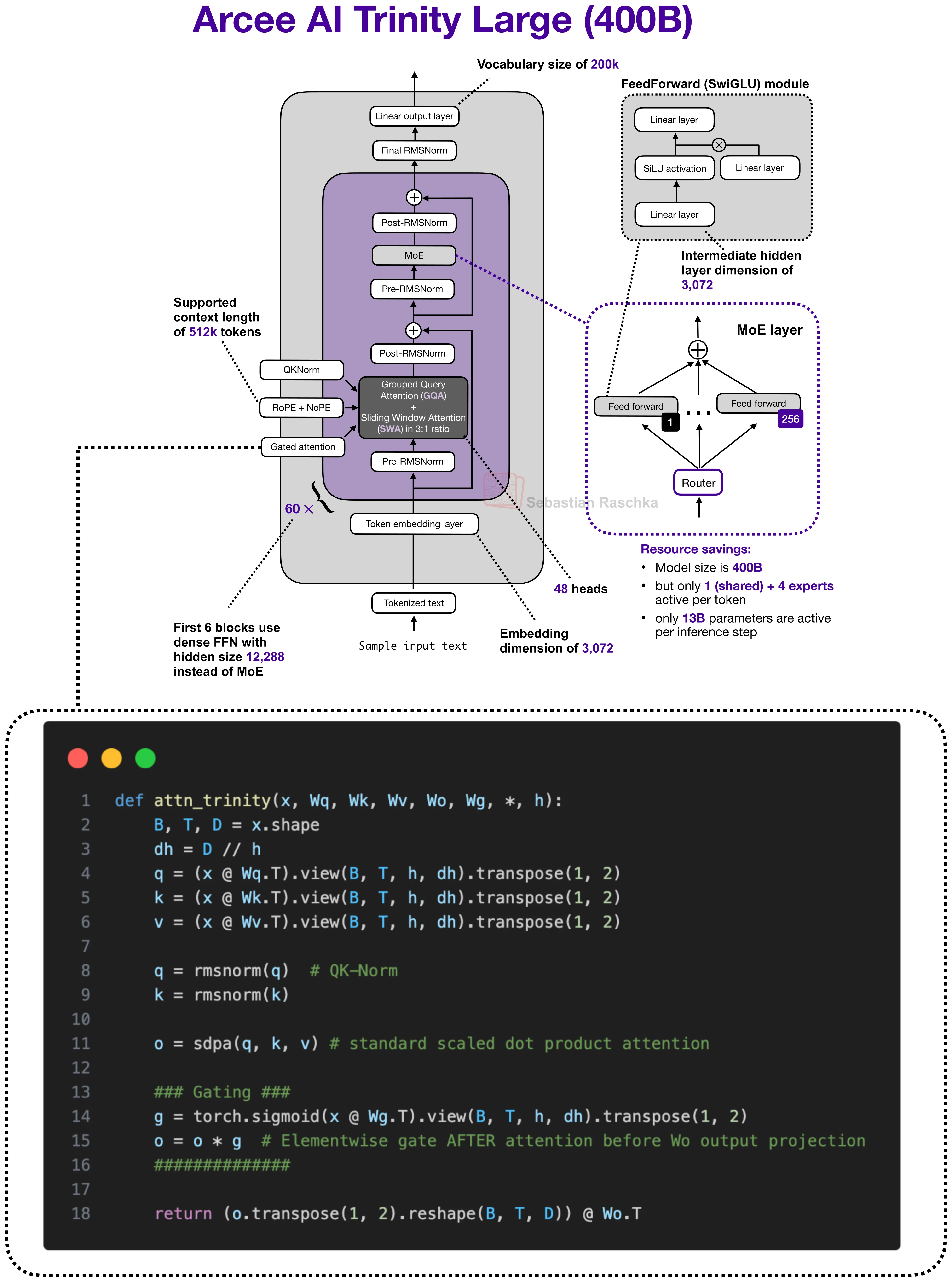
But hybrid architectures aside, Trinity uses a related gating idea in a more conventional attention stack, as shown in the previous figure above.
What Changes Relative To Standard Attention
The gated attention block in Qwen-style hybrids is essentially standard scaled-dot-product attention with a few changes on top. In the original Gated Attention paper, those changes are presented as a way to make the retained full-attention layers behave more predictably inside a hybrid stack.
The block still looks like standard (full) attention, but it adds:
- an output gate that scales the attention result before it is added back to the residual,
- a zero-centered QK-Norm variant instead of standard RMSNorm for q and k,
- partial RoPE.
These are not changes on the scale of MLA or linear attention. They are better understood as stability and control changes applied to an otherwise familiar attention block.
Gated Attention in Trinity
As mentioned above, Trinity does not use the full Qwen-style Gated DeltaNet hybrid, but it borrows a similar gating idea for attention. Trinity applies elementwise gating to the scaled dot-product before the output projection, which the Trinity technical report associates with reduced attention sinks, better long-sequence generalization, and improved training stability.
Sources