Hybrid Attention
Hybrid attention is a broader design pattern rather than a specific, single mechanism. The overall idea is to keep a transformer-like stack, but replace most of the expensive full-attention layers with cheaper linear or state-space sequence modules.
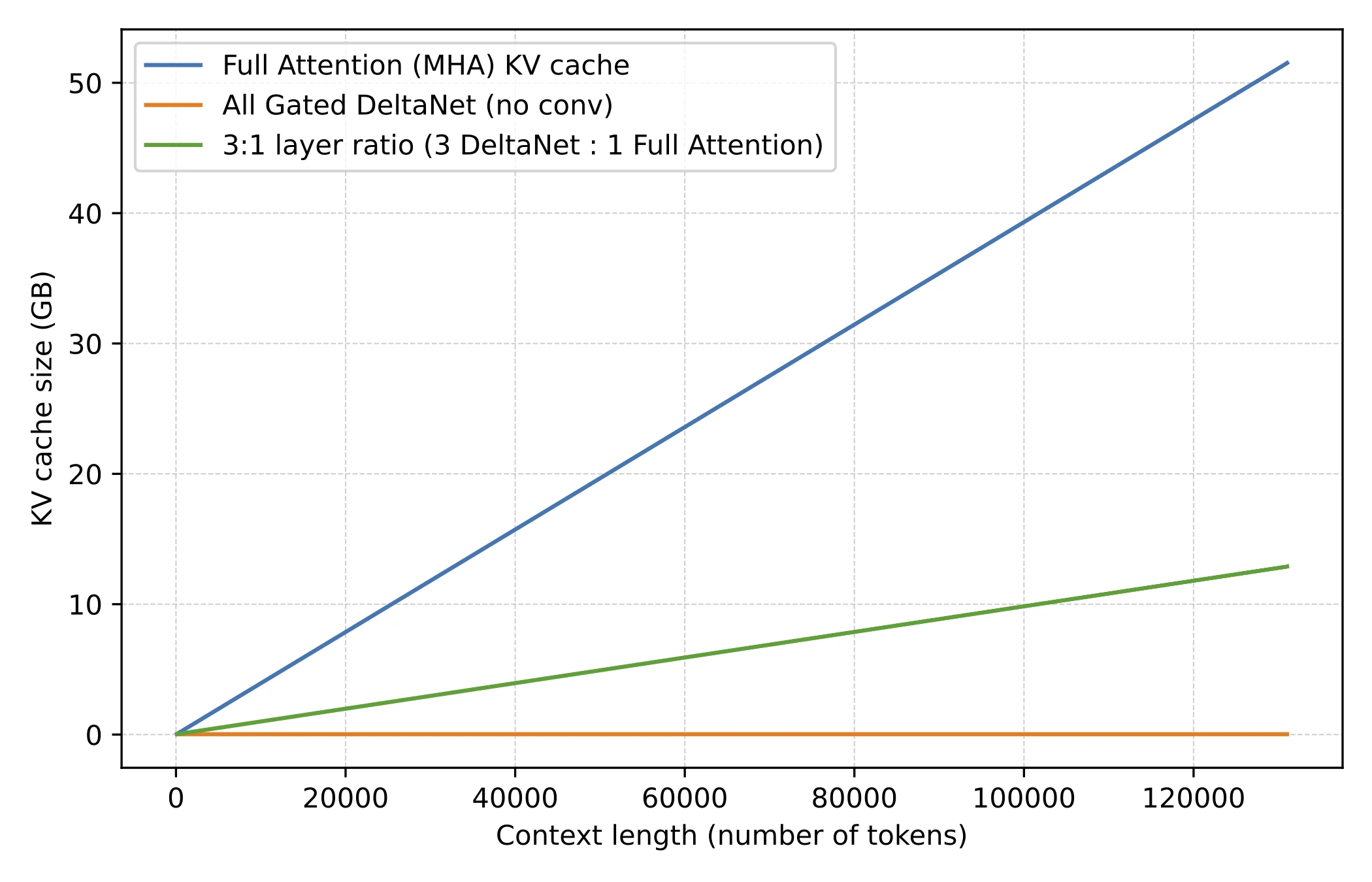
The motivation is long-context efficiency. Full attention grows quadratically with sequence length, so once models move to contexts like 128k, 256k, or 1M tokens, attention memory and compute become expensive enough that using cheaper sequence modules in most layers while keeping only a smaller number of heavier retrieval layers starts making more sense. (Note that this comes with a bit of a modeling performance trade-off, though.)
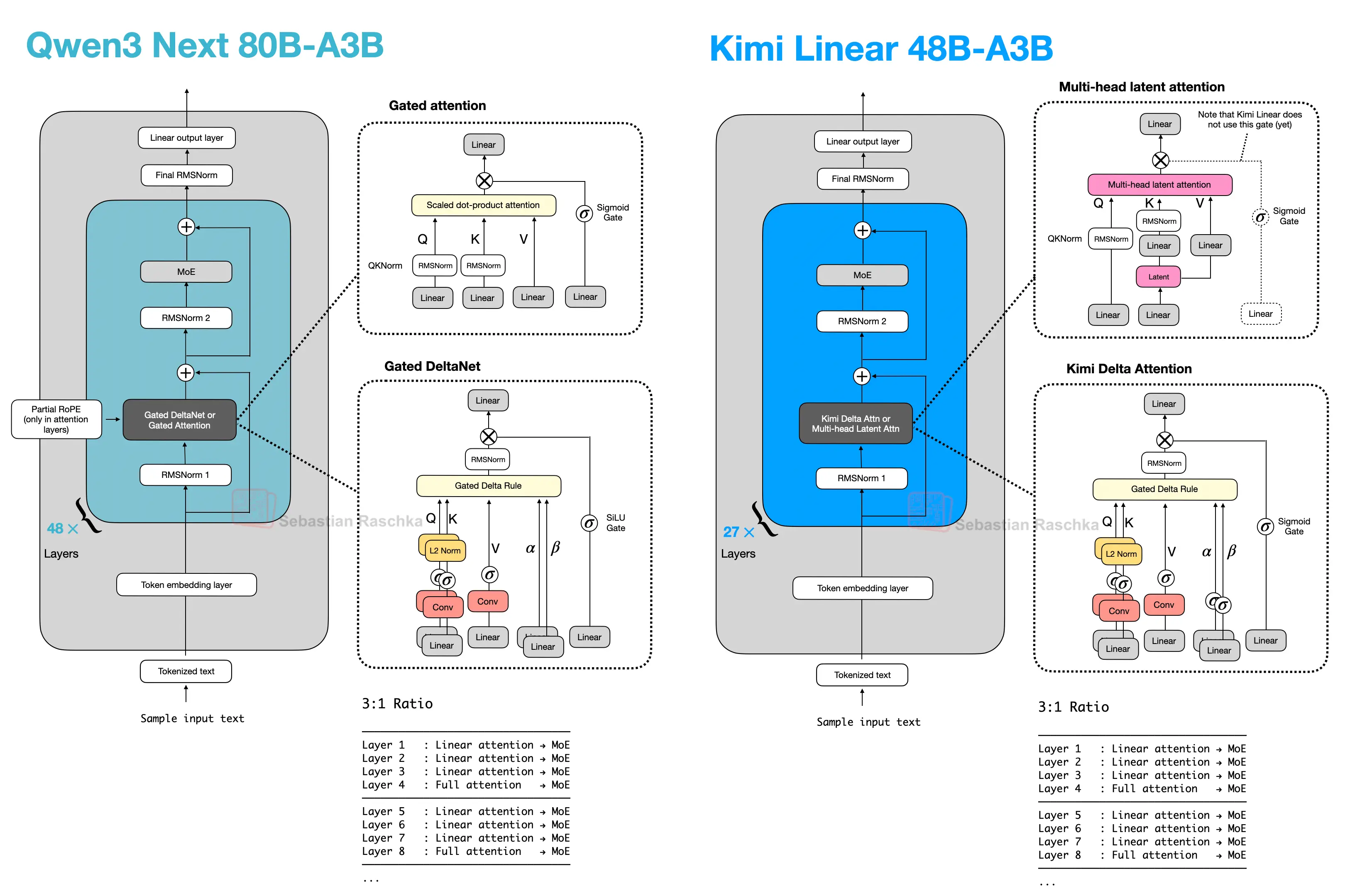
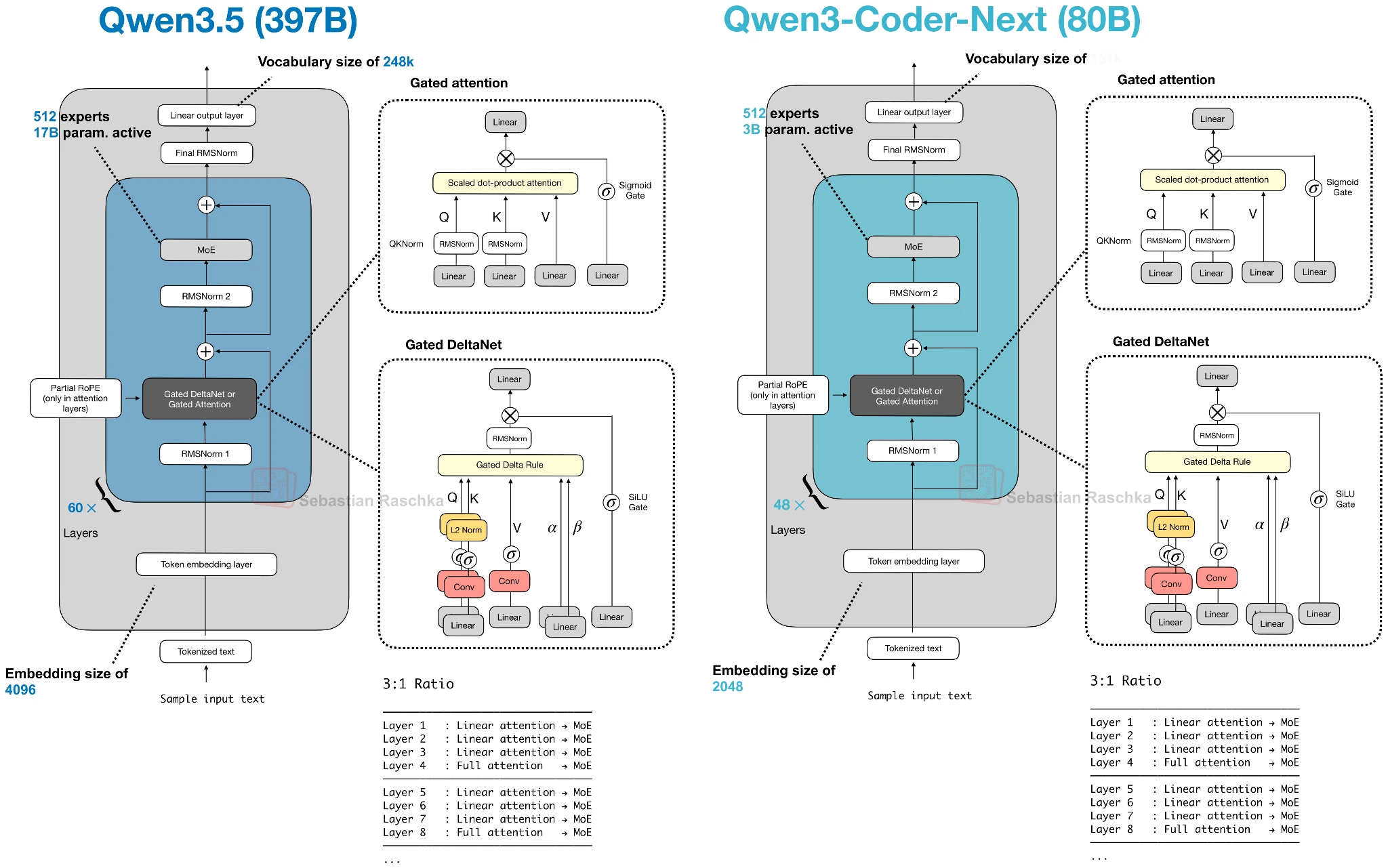
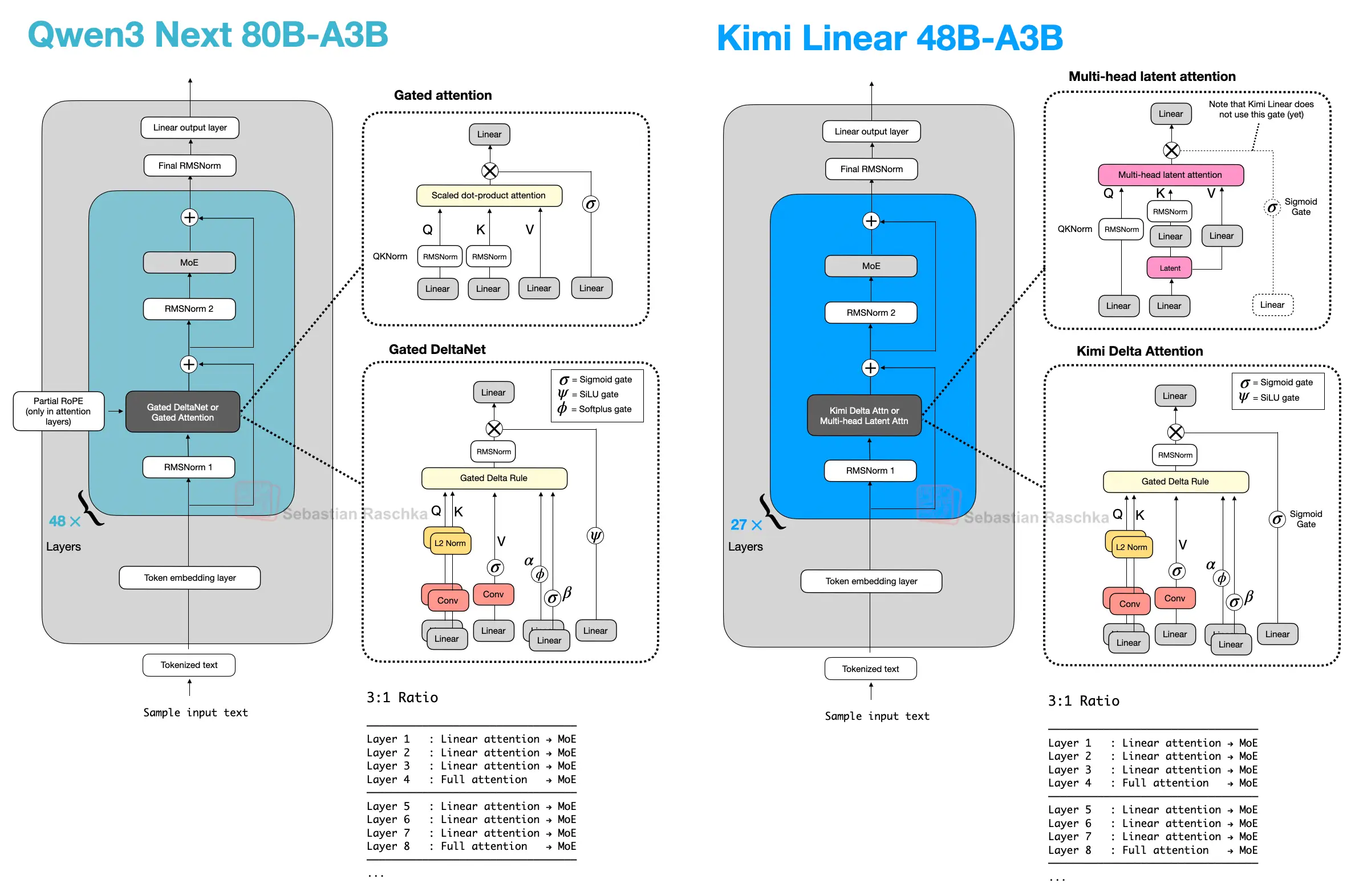
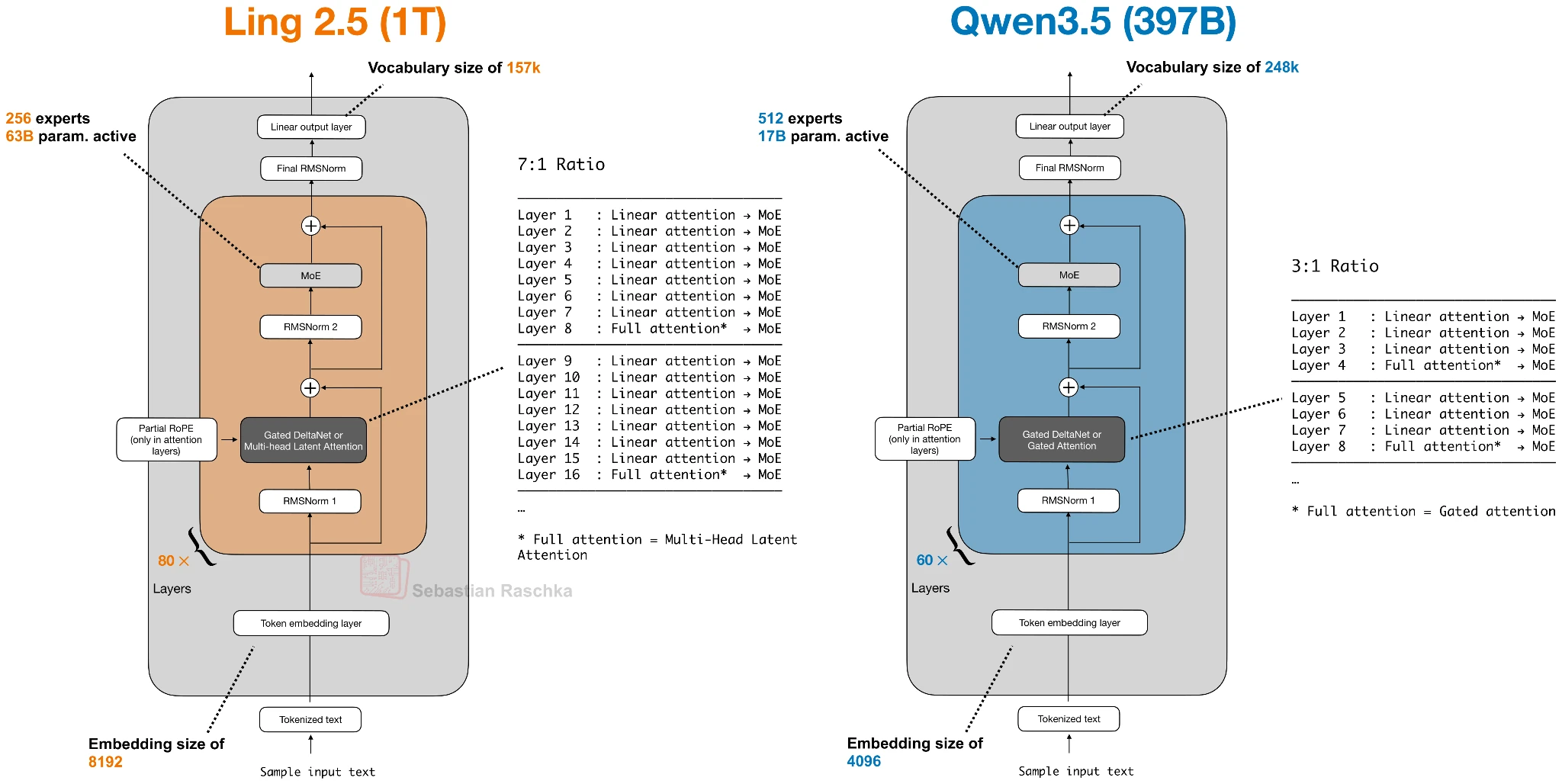
In Qwen3-Next, this pattern appears as a 3:1 mix of Gated DeltaNet and Gated Attention blocks. Gated DeltaNet is also closely related to Mamba-2 (see the Gated Delta Networks: Improving Mamba2 with Delta Rule paper, for instance), and the mechanism can be read as a DeltaNet-style fast-weight update combined with Mamba-style gating. Later architectures keep the same overall idea but swap in other lightweight sequence mixers, such as Kimi Delta Attention, Lightning Attention, or standard Mamba-2.
Summary
Most blocks use a cheaper linear or state-space sequence module, while a smaller number of heavier layers remain for retrieval and stabilization
Why keep a heavy layer
Linear or recurrent blocks scale better with context length, but periodic Gated Attention, MLA, or GQA layers preserve more exact content lookup
Example architectures
Qwen3-Next 80B-A3B, Qwen3.5 397B, and Kimi Linear 48B-A3B, Ling 2.5 1T, Nemotron 3 Nano 30B-A3B, and Nemotron 3 Super 120B-A12B
Gated DeltaNet in Qwen3-Next
To my knowledge, the first prominent example of a close-to-flagship LLM with hybrid attention was Qwen3-Next in 2025, which does not remove attention completely but mixes three Gated DeltaNet blocks with one Gated Attention block.
Here, lightweight Gated DeltaNet blocks do most of the long-context work and keep memory growth much flatter than full attention. The heavier gated-attention layer remains because DeltaNet is less exact at content-based retrieval.
Inside a Gated DeltaNet block, the model computes query, key, and value vectors together with two learned gates (α, β). Rather than forming the usual token-to-token attention matrix, it writes to a small fast-weight memory using a delta-rule update. In rough terms, the memory stores a compressed running summary of past information, while the gates control how much new information is added and how much previous state is retained.
That makes Gated DeltaNet a linear-attention or recurrent-style mechanism rather than just another tweak to MHA. Relative to Mamba-2, the close connection is that both belong to the linear-time gated sequence-model family, but Gated DeltaNet uses a DeltaNet-style fast-weight memory update instead of the Mamba state-space update.
Qwen3.5 moves the former Qwen3-Next hybrid into Qwen’s main flagship series, which is an interesting move. This basically signals that the hybrid strategy is a success and that we may see more models with this architecture in the future.
Kimi Linear Uses A Modified Delta Attention and MLA
Kimi Linear keeps the same broad transformer skeleton and the same 3:1 pattern, but it changes both halves of the recipe.
On the lightweight side, Kimi Delta Attention is a refinement of Gated DeltaNet. Where Qwen3-Next uses a scalar gate per head to control memory decay, Kimi uses channel-wise gating, which gives finer control over the memory update. On the heavier side, Kimi replaces Qwen3-Next’s gated-attention layers with gated MLA layers.
So, it’s still the same broader pattern as in Qwen3-Next and Qwen3.5, but both ingredients (slightly) change. I.e., most layers are still handled by a cheaper linear-style mechanism, and periodic heavier layers still remain for stronger retrieval.
Ling 2.5 Uses Lightning Attention
Ling 2.5 shows another swap on the lightweight side. Instead of Gated DeltaNet, Ling uses a slightly simpler recurrent linear attention variant called Lightning Attention. On the heavier side, it keeps MLA from DeepSeek.
Most sequence mixing happens in the cheaper linear-attention blocks, while a smaller number of heavier layers remain to preserve stronger retrieval. The difference is that the specific lightweight mechanism is now Lightning Attention rather than DeltaNet or Kimi Delta Attention.
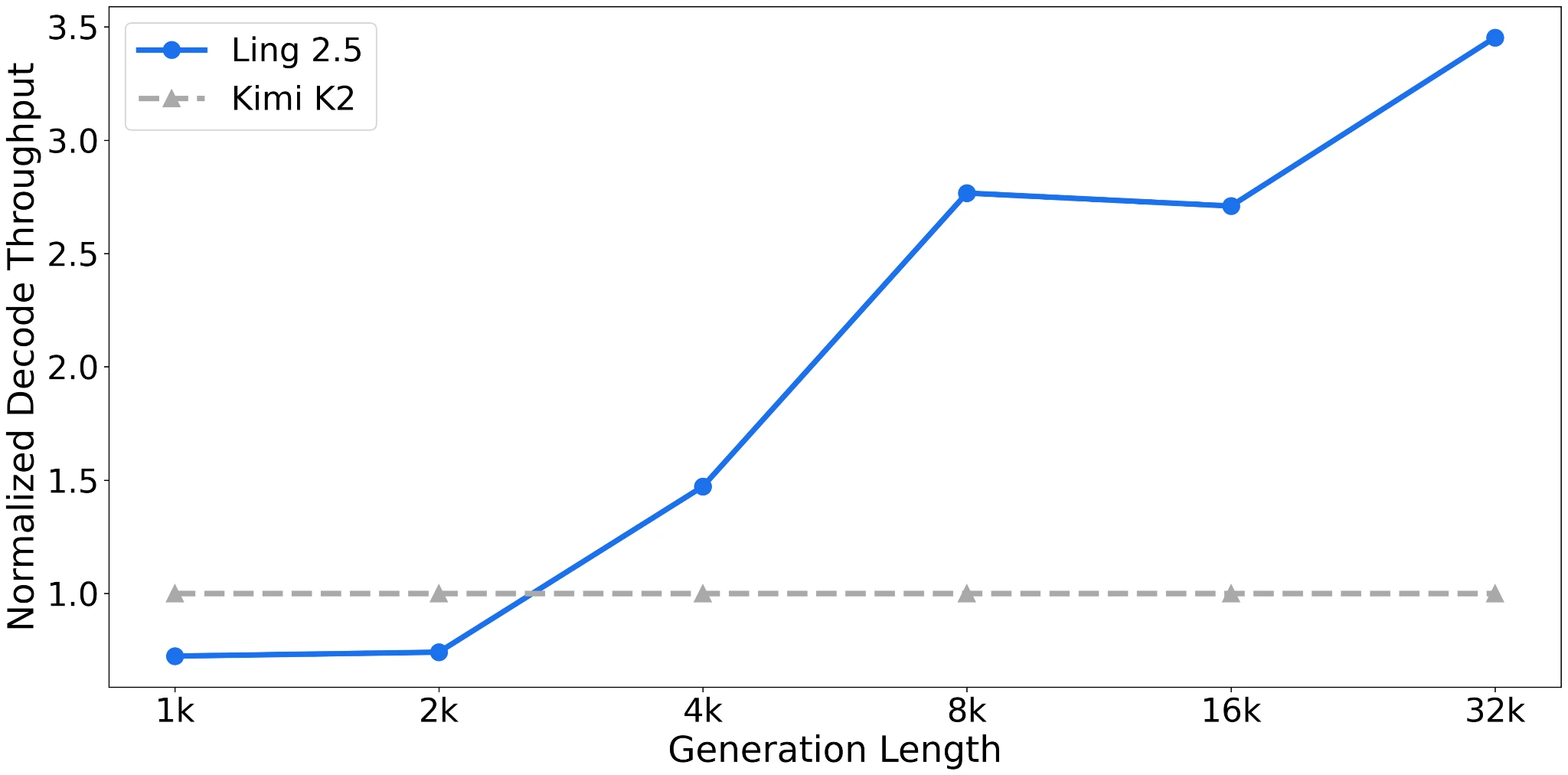
Ling 2.5 is aimed more at long-context efficiency than at absolute benchmark leadership. According to the Ling team, it was reported as substantially faster than Kimi K2 at 32k tokens, which is the practical payoff these hybrids are aiming for.
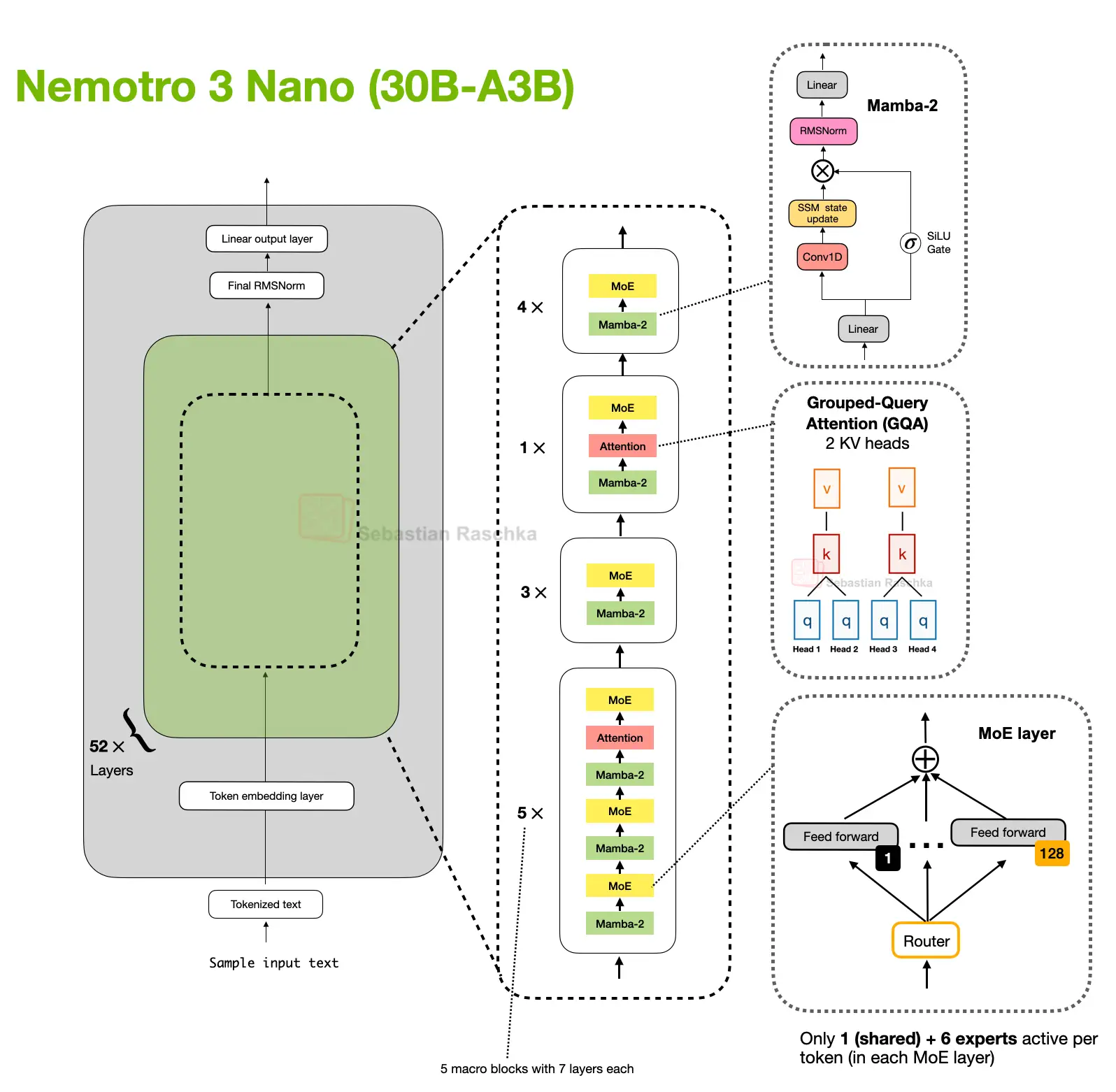
Nemotron Uses Mamba-2 Layers
Nemotron pushes the pattern further away from the transformer baseline. Nemotron 3 Nano is a Mamba-Transformer hybrid that interleaves Mamba-2 sequence-modeling blocks with sparse MoE layers and uses self-attention only in a small subset of layers.
This is a more extreme version of the same basic tradeoff discussed above. Here, the lightweight sequence module is a Mamba-2 state-space block rather than a DeltaNet-style fast-weight update, but the basic tradeoff is similar.
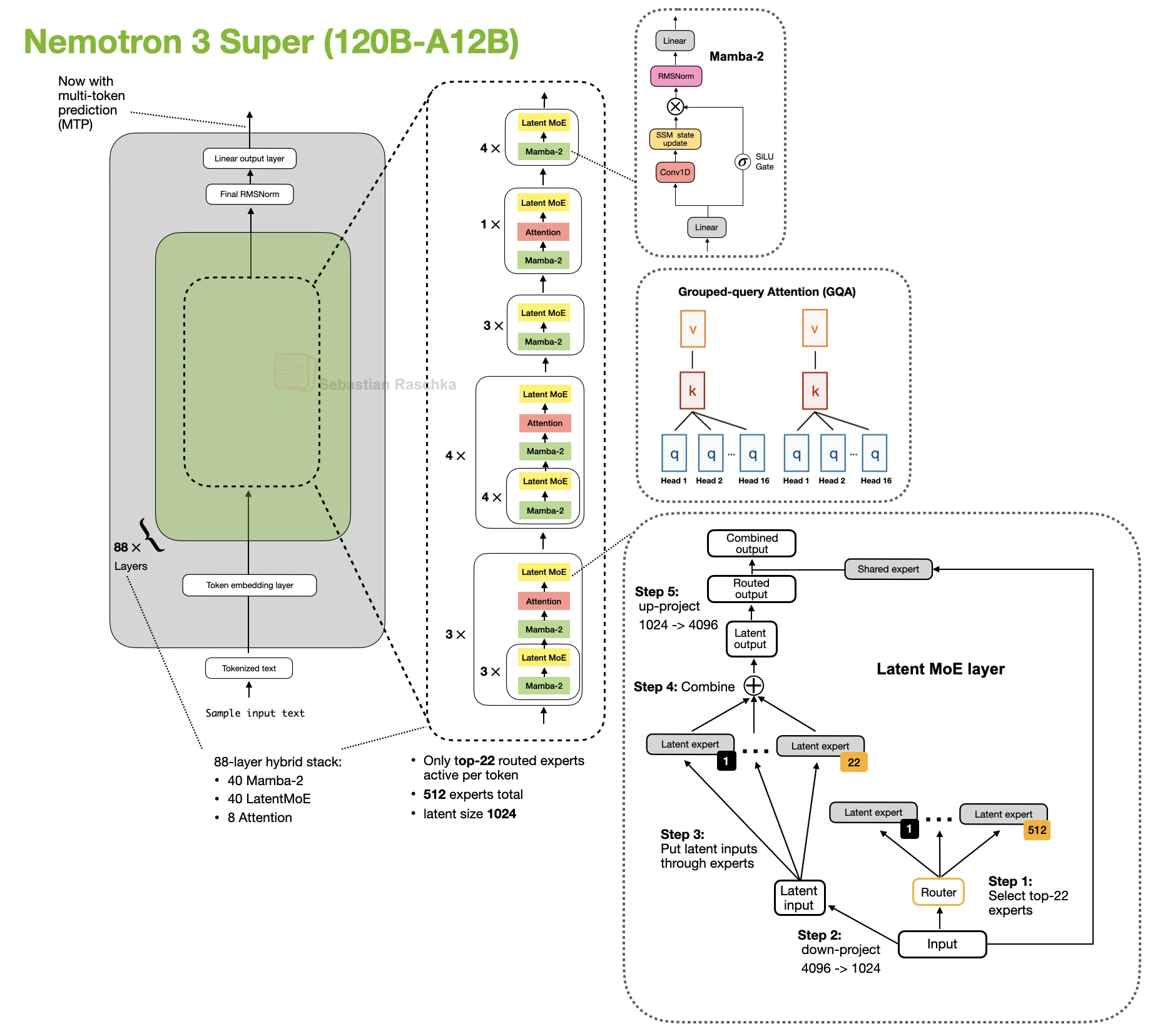
The larger Nemotron 3 Super keeps the Mamba-2 hybrid attention approach and adds other efficiency-oriented changes such as latent MoE and shared-weight multi-token prediction (MTP) for speculative decoding.
Sources