Multi-Head Attention (MHA)
Self-attention lets each token look at the other visible tokens in the sequence, assign them weights, and use those weights to build a new context-aware representation. Multi-head attention (MHA) is the standard transformer version of that idea. It runs several self-attention heads in parallel with different learned projections, then combines their outputs into one richer representation.
The section below are a whirlwind tour explaining self-attention to explain MHA. It’s more meant as a quick overview to set the stage for related attention concepts like grouped-query attention, sliding window attention, and so on. If you are interested in a longer, more detailed self-attention coverage, you might like my longer Understanding and Coding Self-Attention, Multi-Head Attention, Causal-Attention, and Cross-Attention in LLMs article.
Self-attention motivation
Attention was introduced to remove the fixed-summary bottleneck in encoder-decoder RNN translation models
From self-attention to MHA
MHA runs several self-attention heads with different learned projections and combines their outputs into one representation
Example architectures
GPT-2 XL 1.5B, OLMo 2 7B, and OLMo 3 7B
Why Attention Was Introduced
Attention predates transformers and MHA. Its immediate background is encoder-decoder RNNs for translation.
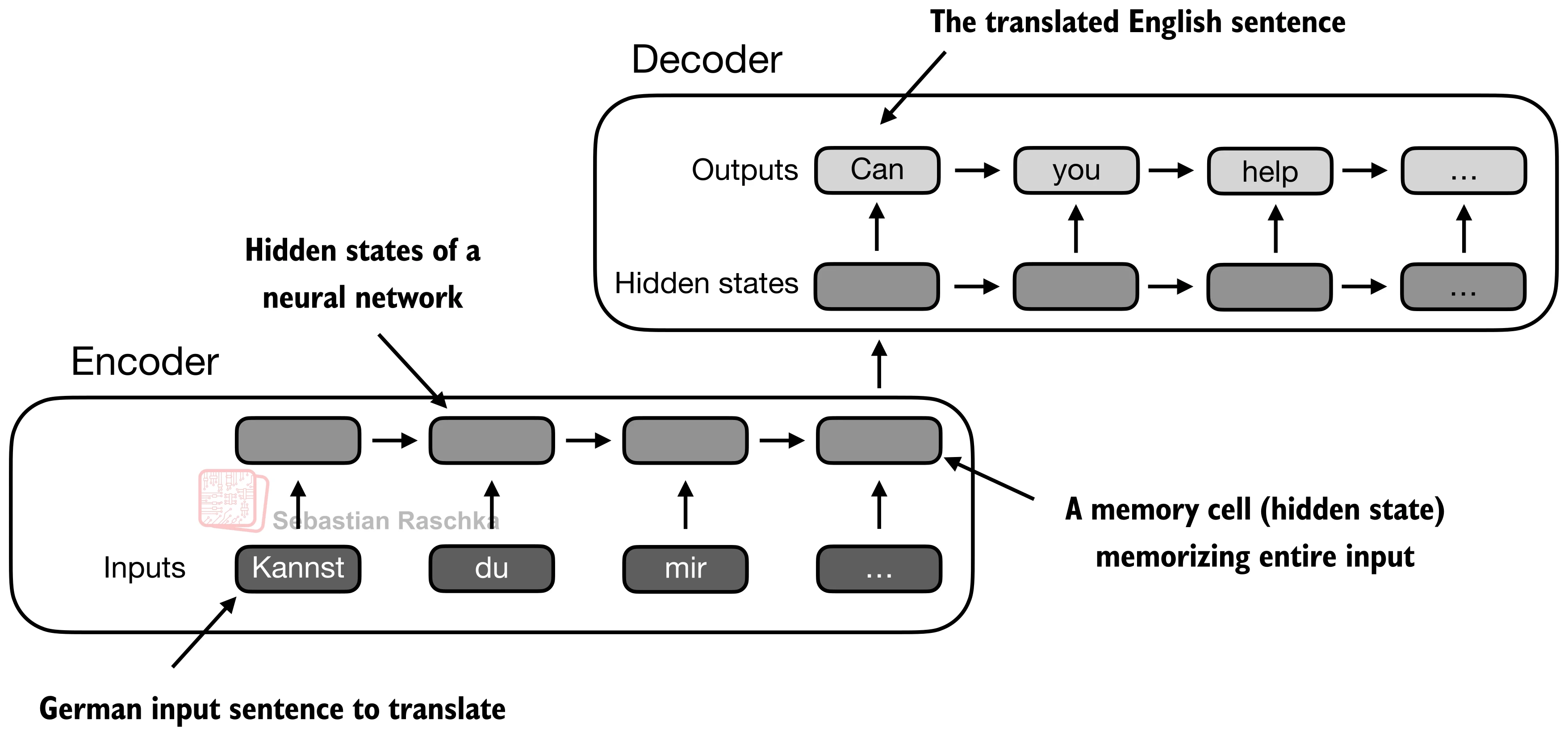
In those older systems, an encoder RNN would read the source sentence token by token and compress it into a sequence of hidden states, or in the simplest version into one final state. Then the decoder RNN had to generate the target sentence from that limited summary. This worked for short and simple cases, but it created an obvious bottleneck once the relevant information for the next output word lived somewhere else in the input sentence.
In short, the limitation is that the hidden state can’t store infinitely much information or context, and sometimes it would be useful to just refer back to the full input sequence.
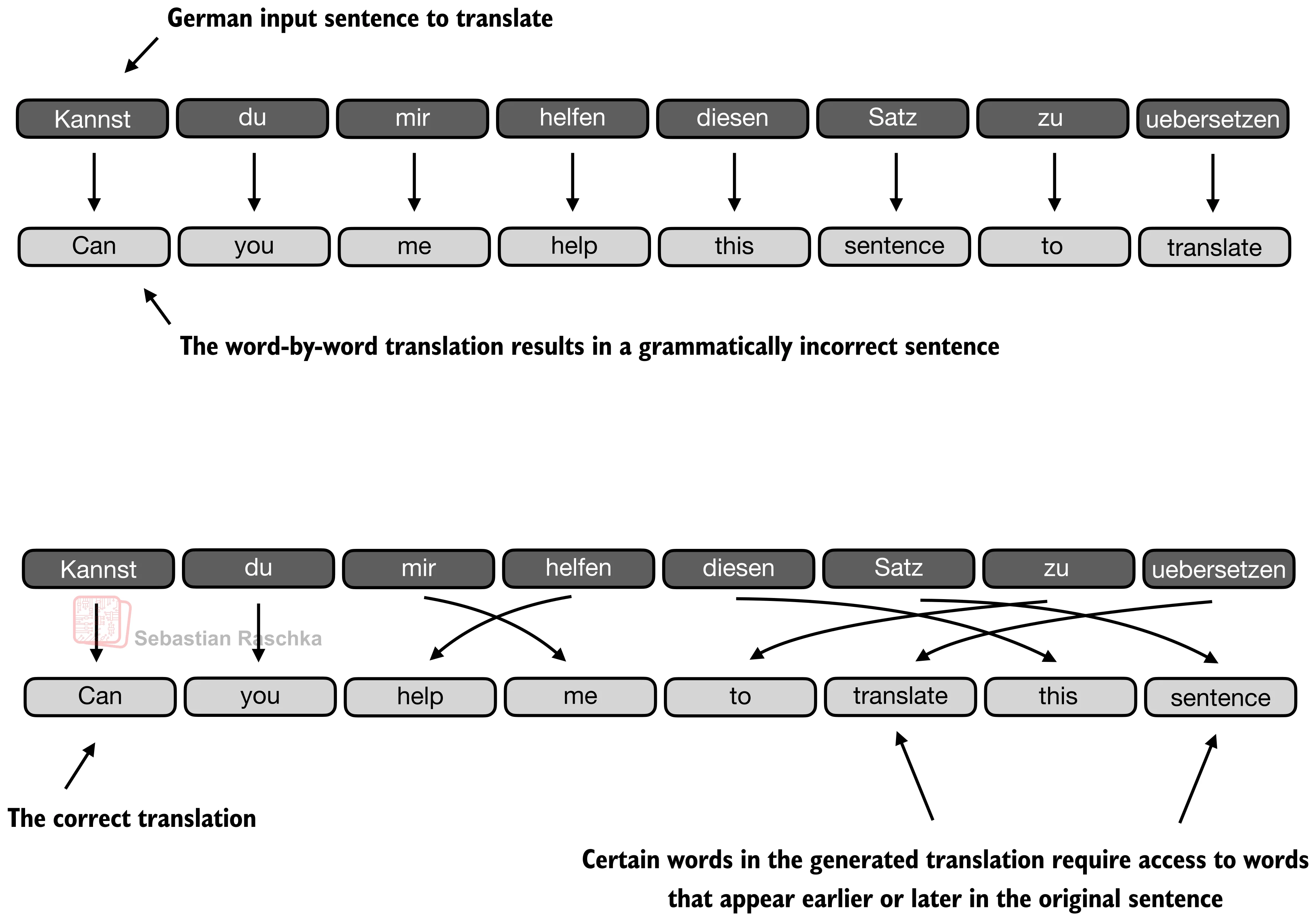
The translation example below shows one of the limitations of this idea. For instance, a sentence can preserve many locally reasonable word choices and still fail as a translation when the model treats the problem too much like a word-by-word mapping. (The top panel shows an exaggerated example where we translate the sentence word by word; obviously, the grammar in the resulting sentence is wrong.) In reality, the correct next word depends on sentence-level structure and on which earlier source words matter at that step. Of course, this could still be translated fine with an RNN, but it would struggle with longer sequences or knowledge retrieval tasks because the hidden state can only store so much information as mentioned earlier.
So, to overcome the limitation of standard RNNs, that everything gets stored in a hidden state, and that the model can’t access the original inputs when needed, researchers added an attention mechanism via Neural Machine Translation by Jointly Learning to Align and Translate. The point was to remove that fixed-summary bottleneck of the hidden state and instead of forcing the decoder to rely on one compressed summary of the whole input, attention lets it build a step-specific context vector at each output step by revisiting the more relevant encoder states.
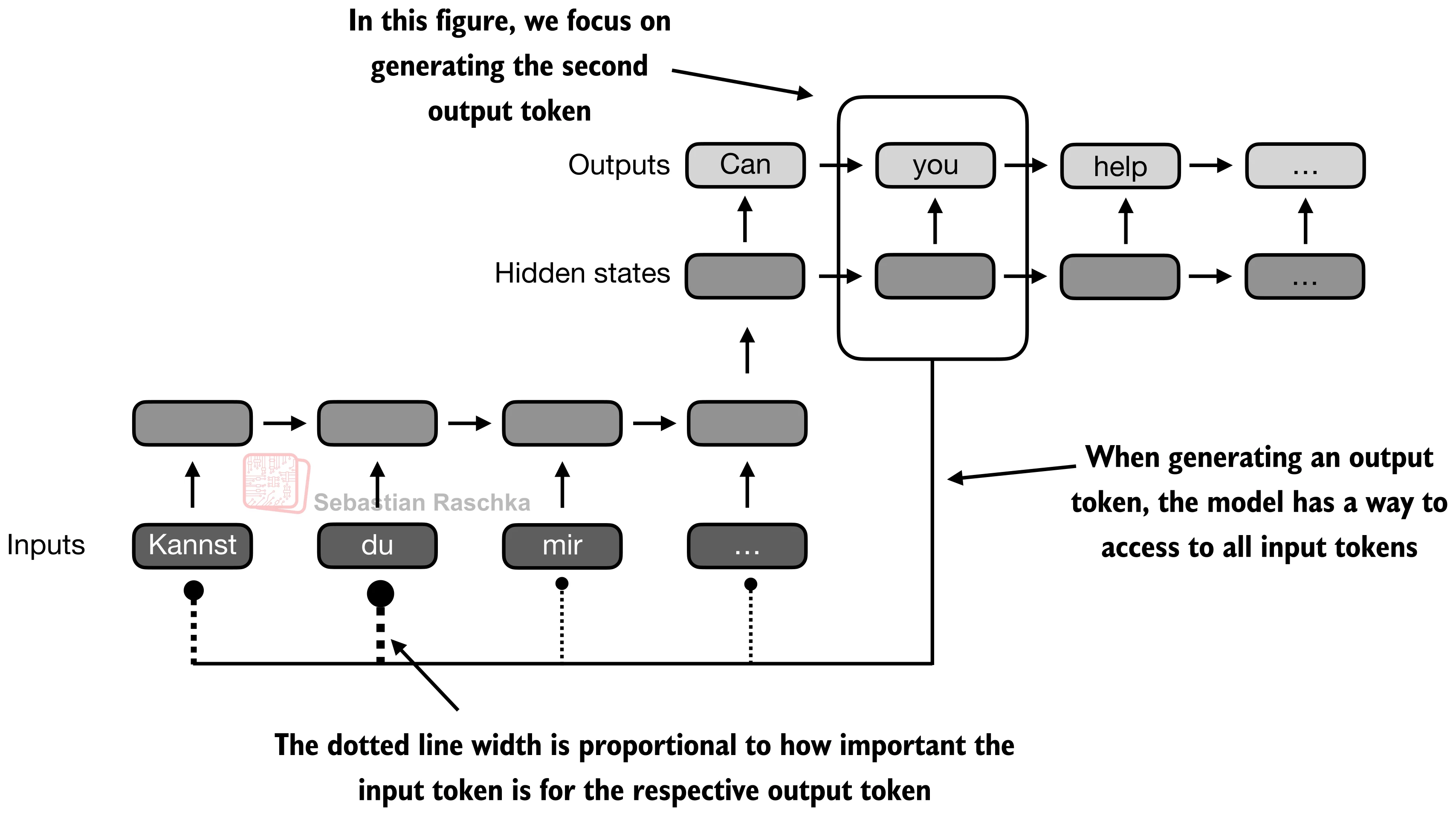
In language, this matters because the word we want next often depends on content that appeared much earlier or later in the source sentence, not just on the immediately previous token.
The next figure shows that change more directly. When the decoder is producing an output token, it should not be limited to one compressed memory path. It should be able to reach back to the more relevant input tokens directly.
Transformers keep that core idea from the aforementioned attention-modified RNN but remove the recurrence. In the classic Attention Is All You Need paper, attention becomes the main sequence-processing mechanism itself (instead of being just part of an RNN encoder-decoder.)
In transformers, that mechanism is called self-attention, where each token in the sequence computes weights over all other tokens and uses them to mix information from those tokens into a new representation. Multi-head attention is the same mechanism run several times in parallel.
The Masked Attention Matrix
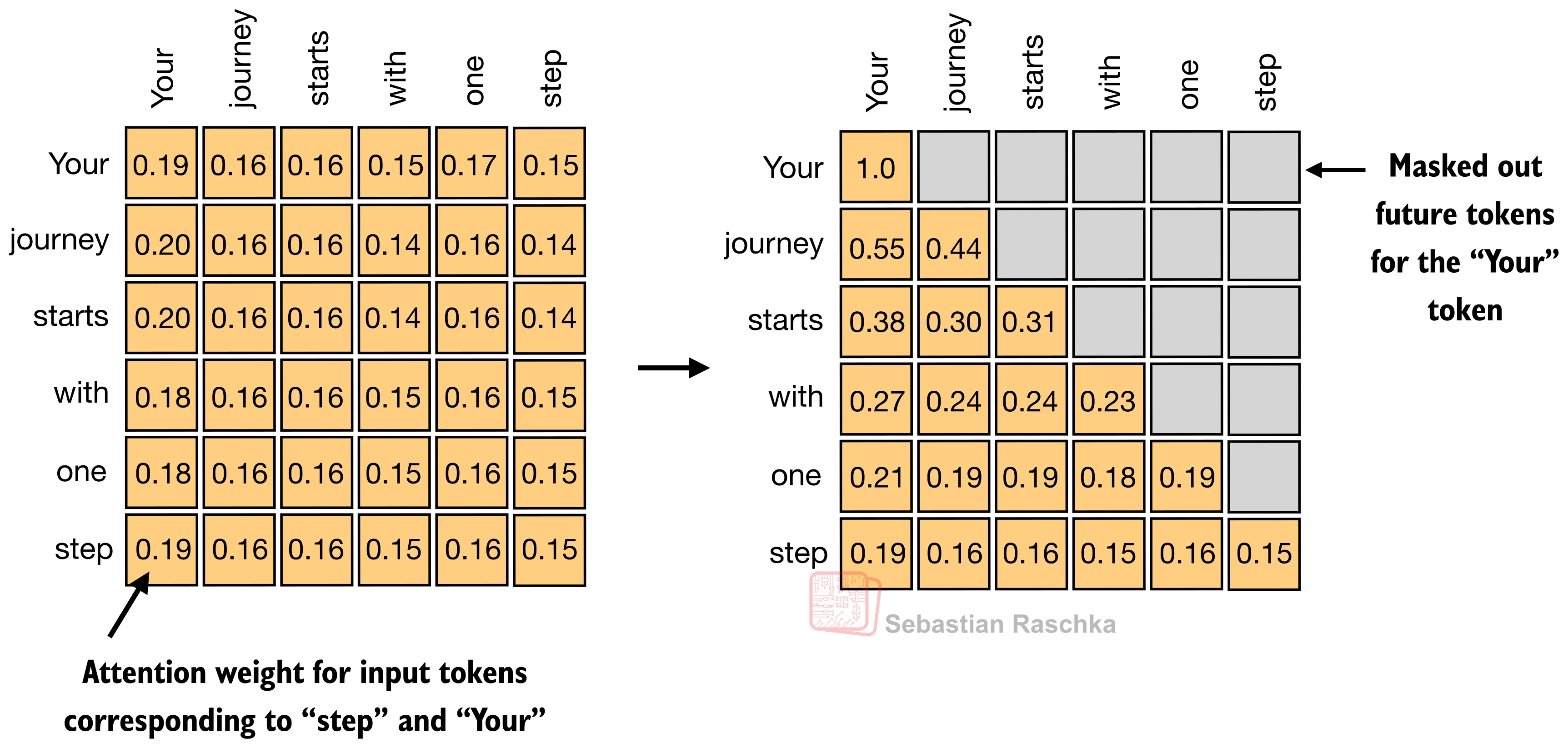
For a sequence of
T tokens, attention needs one row of weights per token, so overall we get a T x T matrix.
Each row answers a simple question. When updating this token, how much should each visible token matter? In a decoder-only LLM, future positions are masked out, which is why the upper-right part of the matrix is grayed out in the figure below.
Self-attention is fundamentally about learning these token-to-token weight patterns, under a causal mask, and then using them to build context-aware token representations.
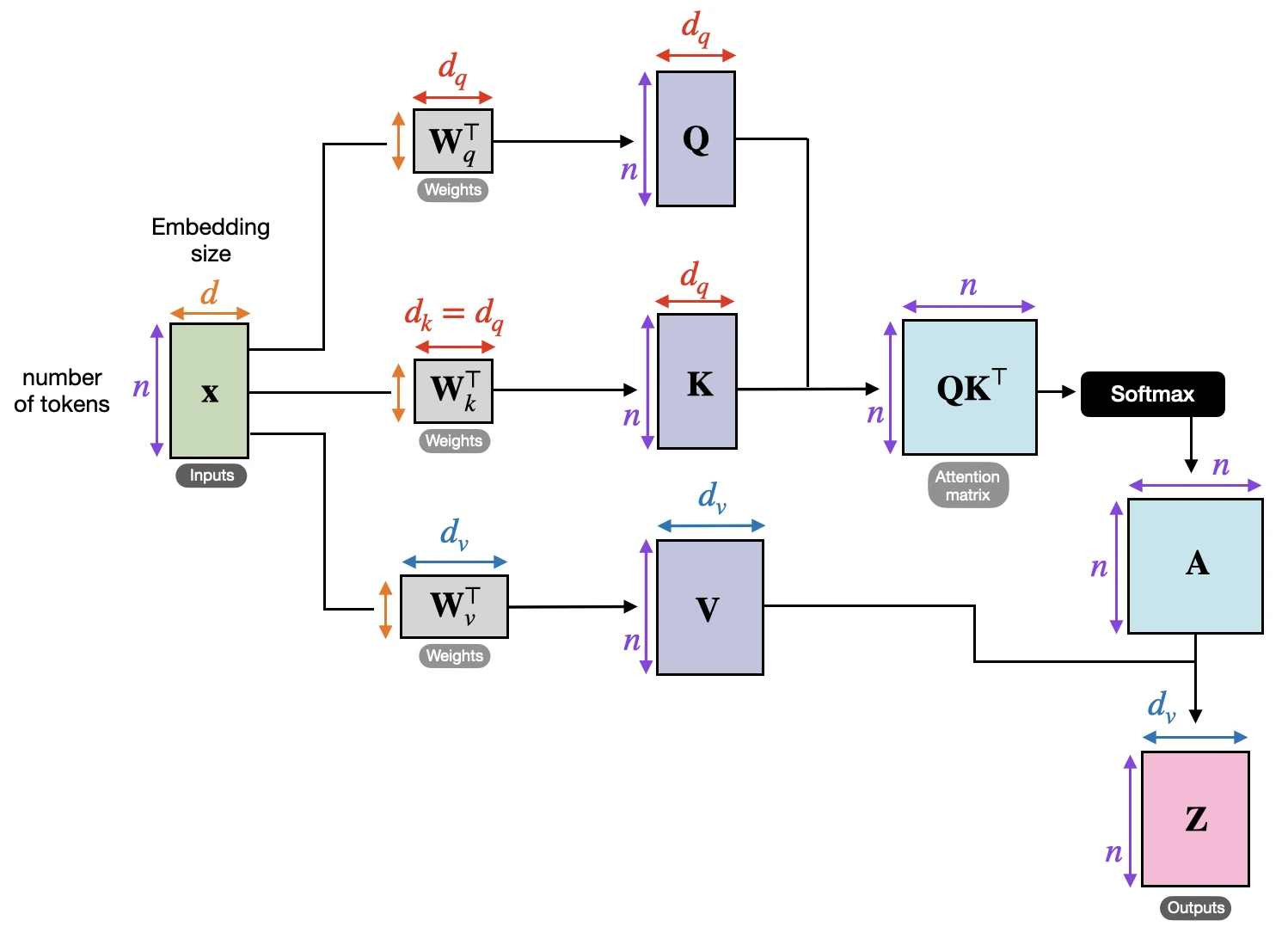
Self-Attention Internals
The next figure shows how the transformer computes the attention matrix (A) from
the input embeddings X, which is then used to produce the transformed inputs (Z).
Here Q, K, and V stand for queries, keys, and values. The query for a token represents what that token is
looking for, the key represents what each token makes available for matching, and the value represents the information
that gets mixed into the output once the attention weights have been computed.
The steps are as follows:
-
Wq,Wk, andWvare weight matrices that project the input embeddings intoQ,K, andV -
QK^Tproduces the raw token-to-token relevance scores - softmax converts those scores into the normalized attention matrix
Athat we discussed in the previous section -
Ais applied toVto produce the output matrixZ
Note that the attention matrix is not a separate hand-written object. It emerges from Q, K, and softmax.
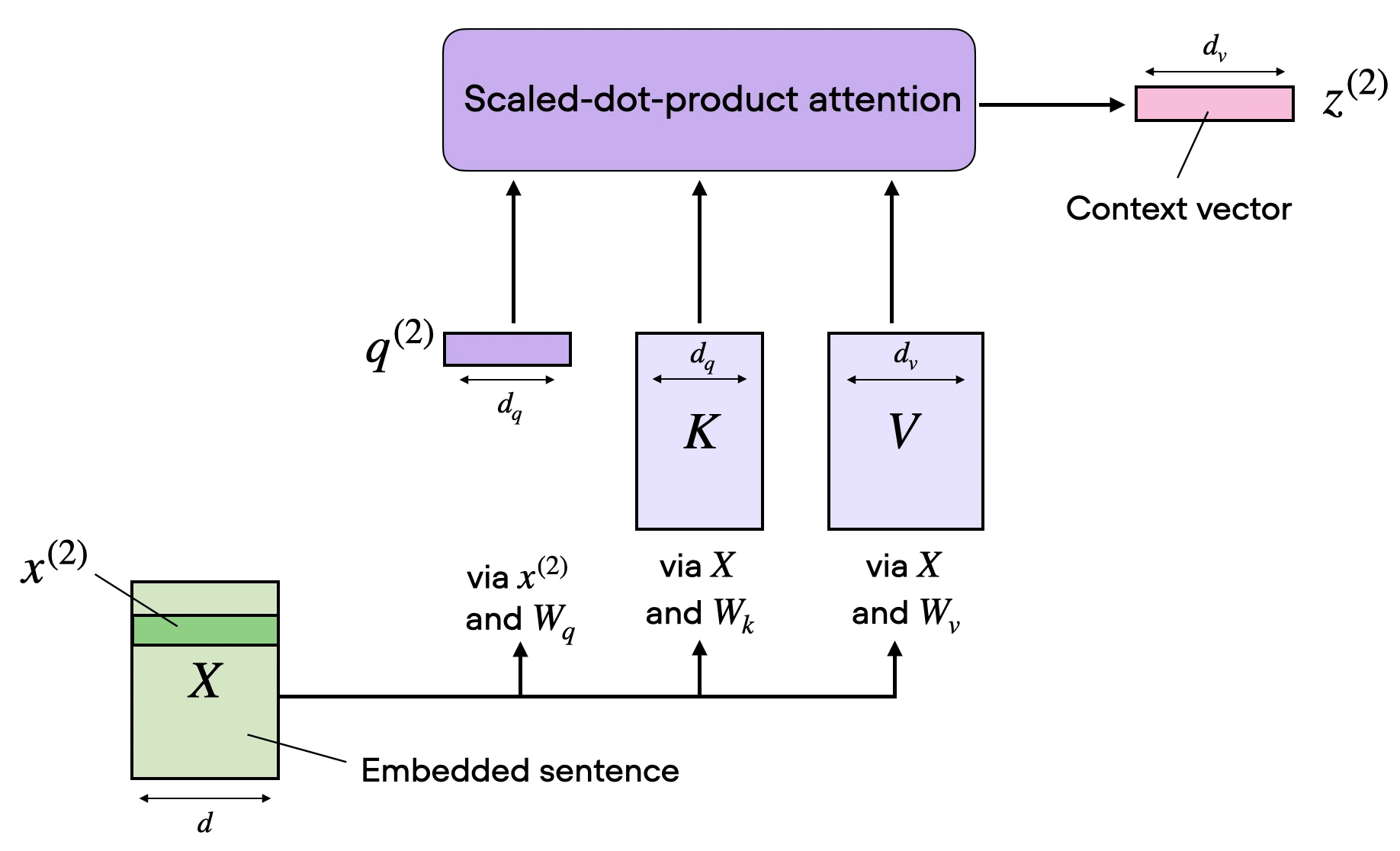
The next figure shows the same concept as the previous figure but the attention matrix computation is hidden inside the “scaled-dot-product attention” box, and we perform the computation only for one input token instead of all input tokens. This is to show a compact form of self-attention with a single head before extending this to multi-head attention in the next section.
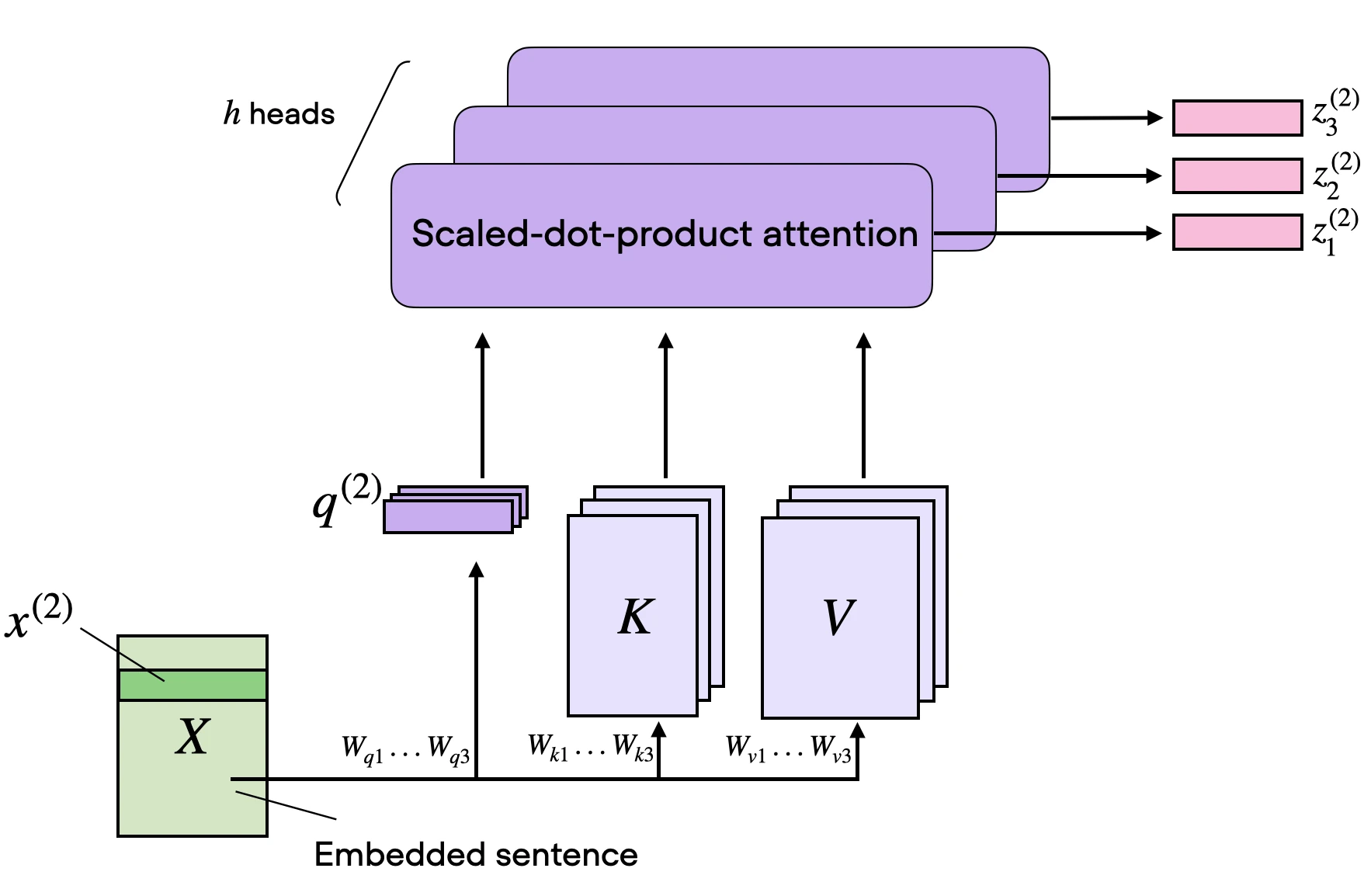
From One Head To Multi-Head Attention
One set of Wq/Wk/Wv matrices gives us one attention head, which means
one attention matrix and one output matrix Z. (This concept was illustrated in the previous section.)
Multi-head attention simply runs several of these heads in parallel with different learned projection matrices.
This is useful because different heads can specialize in different token relationships. One head might focus on short local dependencies, another on broader semantic links, and another on positional or syntactic structure.
Sources