RMSNorm
RMSNorm is one of the least flashy changes in modern LLMs, but it is also one of the most widespread.
In practice, it largely displaced LayerNorm in current decoder stacks because it solves the same optimization problem with a slightly cheaper computation. That is why you now see RMSNorm everywhere from Llama and Qwen to DeepSeek, GPT-OSS, and even newer architectures that otherwise experiment aggressively with attention and MoE.
Why It Exists
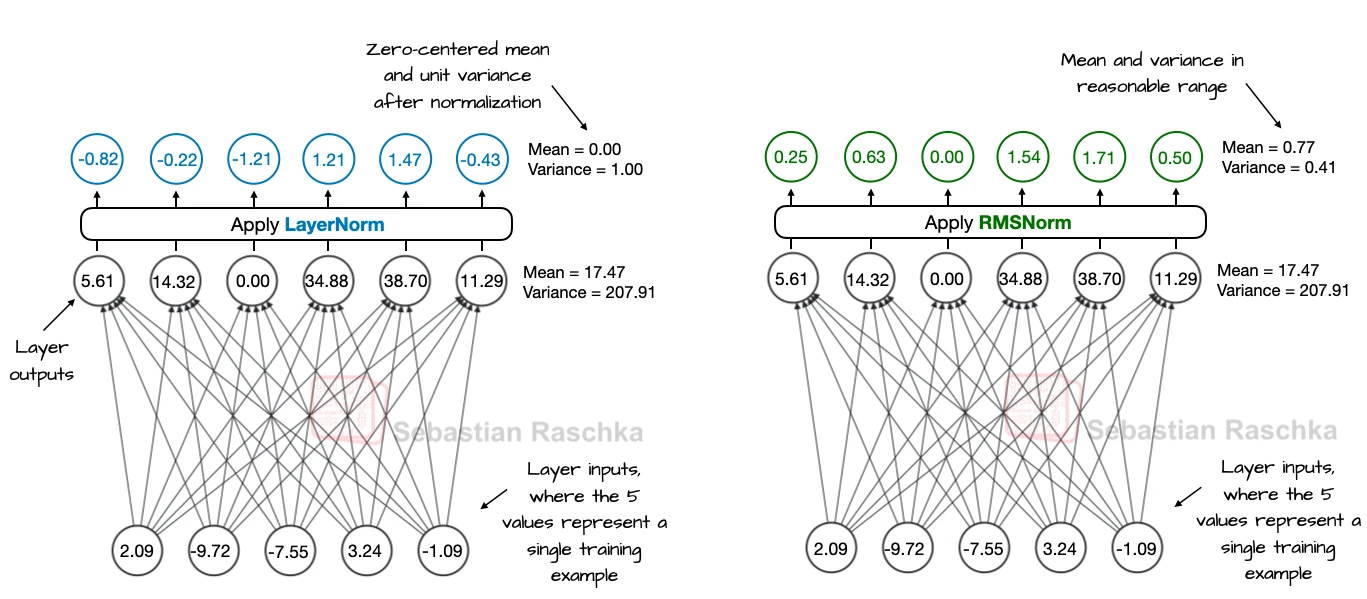
Normalization layers keep activation magnitudes in a workable range so optimization does not drift into unstable territory. RMSNorm does that without computing both a mean and a variance. Instead, it divides by the root-mean-square of the activations, which is enough to stabilize scale while making the computation a bit lighter.
That sounds minor, but on very large models these small savings add up. Modern LLM engineering is full of these choices: not dramatic architectural reinventions, just cleaner operating points that preserve quality while shaving off some compute or communication overhead.
What Changes Relative To LayerNorm
LayerNorm enforces zero mean and unit variance. RMSNorm only rescales by the root-mean-square, so it controls the magnitude of the activations but does not force them to be centered around zero. In large decoder models, that is usually good enough.
The benefit is that the implementation becomes simpler. This is one reason RMSNorm became a common default in decoder-only LLMs once those models started scaling aggressively.
Why Placement Still Matters
RMSNorm itself is only one part of the story. The other part is where it sits in the block. The architecture article spends time on OLMo 2 and Gemma 3 because both models deviate from the plain pre-norm recipe. OLMo 2 moves RMSNorm into a post-norm-like position inside the residual path, while Gemma 3 uses it both before and after sublayers.
That is why RMSNorm and normalization placement should be thought of separately. One is the normalization operator; the other is the architectural decision about where to apply it.
How To Read It In The Gallery
On the gallery page, RMSNorm is often invisible because it has become standard. The interesting cases are the ones where the cards mention QK-Norm, post-norm, or unusual pre/post placements. Those are usually signals that a model is using RMSNorm in a more deliberate way than the plain baseline decoder stack.