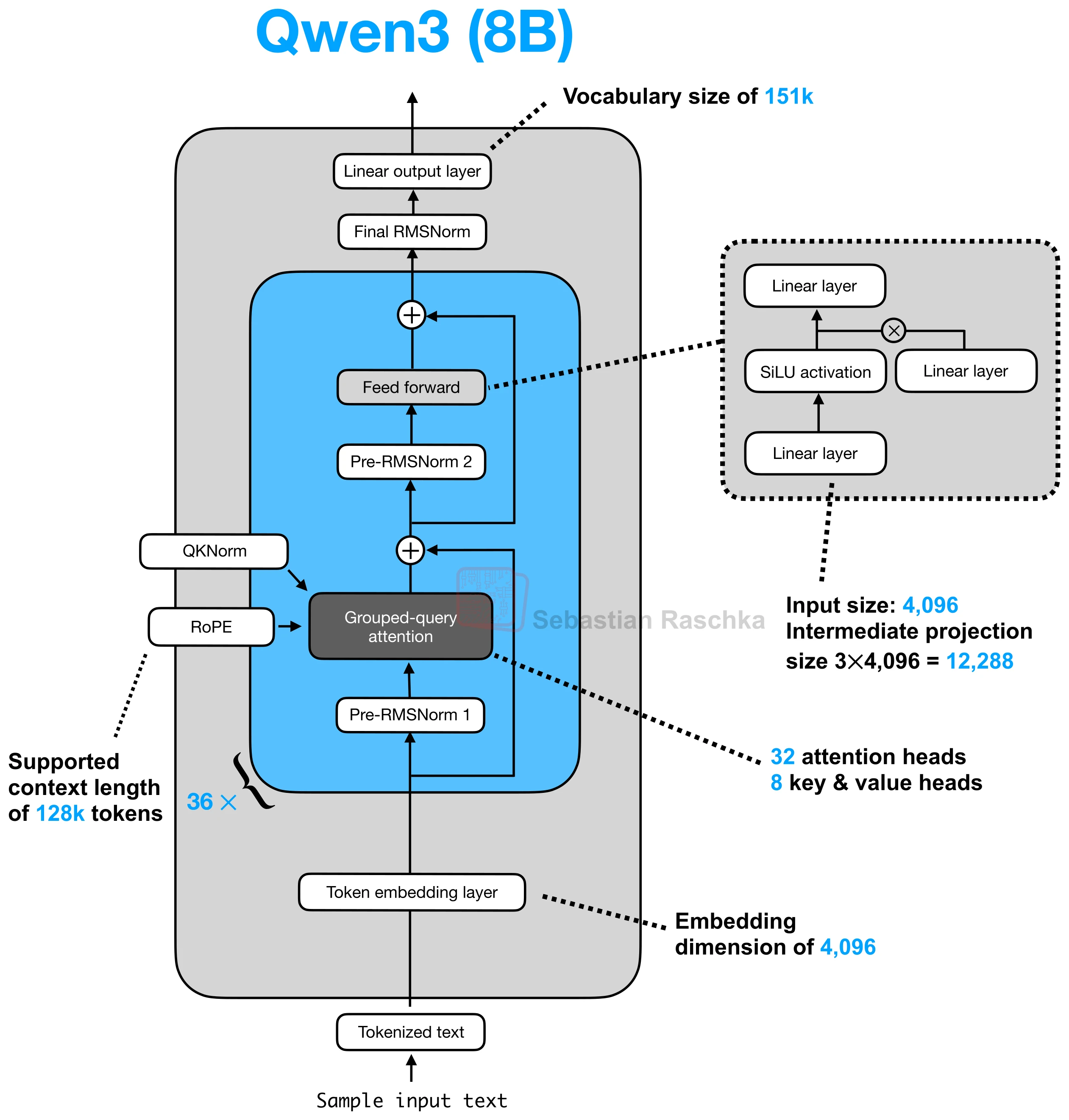
QK-Norm
QK-Norm is one of the small internal attention stabilizers that keeps showing up in newer architectures.
The idea is straightforward: apply RMSNorm to the queries and keys inside the attention block before RoPE and before computing attention scores. It is a modest change, but it became common because it helps reduce training instability without forcing a more radical architecture rewrite.
Why It Exists
When the attention scores become too sharp or poorly scaled, optimization can become noisy. QK-Norm targets that problem at the source by normalizing the query and key projections before they interact. In the architecture article, OLMo 2 was the clearest example because the model combined QK-Norm with a post-norm-style block layout to improve training stability.
So, unlike GQA or MLA, QK-Norm is not about changing how much context the model can represent. It is about making a familiar attention block behave better during training.
Where It Sits In The Block
QK-Norm lives inside attention, not around the whole transformer block. The model first projects tokens into q, k, and v, then applies the normalization to q and k, then applies RoPE, and only after that computes the attention scores. That ordering matters because the goal is to stabilize the vectors that actually define the dot products.
This is why QK-Norm is often described as “just another RMSNorm layer,” but that undersells it a bit. The placement inside attention is what makes it a separate concept from ordinary pre-norm or post-norm blocks.
Why It Often Shows Up With RoPE
RoPE and QK-Norm are natural companions because both operate directly on q and k. In many current architectures, QK-Norm happens first, then RoPE rotates the normalized vectors, then the attention scores are computed. That is why the gallery cards often mention them together.
Some newer variants go further. The Qwen3-Next family, for instance, uses a zero-centered RMSNorm variant in its gated attention blocks instead of the more standard formulation.
How To Read It In The Gallery
On the gallery page, QK-Norm is usually a hint that the model is trying to keep training stable while still using otherwise conventional attention. You see it in OLMo, Gemma 3, Qwen3, MiniMax, GLM-4.5, and Sarvam 30B. When a card says QK-Norm, it is usually signaling a stability refinement rather than a change in the model’s long-context asymptotics.