Grouped-Query Attention (GQA)
Grouped-Query Attention is one of those architectural changes that looks small on paper but ended up becoming the default attention recipe in a large share of modern decoder LLMs.
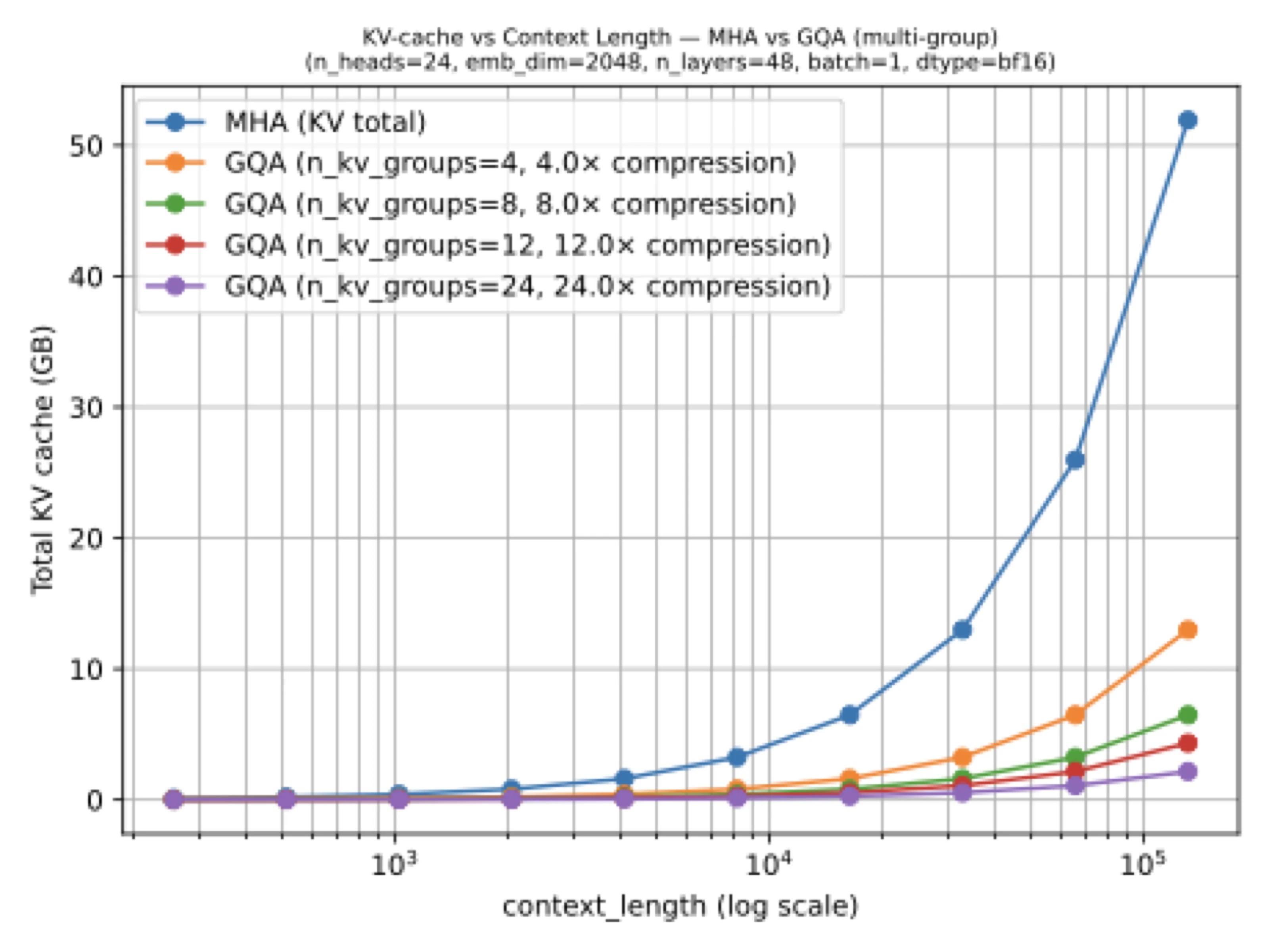
The basic idea is simple: keep the query heads, but let several of them share the same keys and values. That preserves the familiar transformer structure while making KV caching cheaper, which is exactly why GQA displaced classic multi-head attention in models like Llama, Qwen, Gemma, and GPT-OSS.
temp/LLMs-from-scratch/ch04/04_gqa/plot_memory_estimates_gqa.py.
Why It Exists
In the standard multi-head attention setup, every attention head has its own keys and values. That is conceptually clean, but it becomes expensive during inference because the model has to keep those keys and values around in the KV cache for every previously seen token. In The Big LLM Architecture Comparison, I framed GQA as the now-standard replacement for classic multi-head attention precisely because it attacks that bottleneck without changing the rest of the decoder very much.
That practical balance is the reason GQA won. It lowers memory use and bandwidth requirements, while ablation studies in the original GQA and Llama 2 papers suggest that the quality hit is usually small when the grouping is chosen sensibly.
What Changes In The Block
The easiest way to think about GQA is that the number of query heads stays high, but the number of key-value heads is reduced. Multiple queries then read from the same key-value group. So the attention mechanism still behaves like standard dot-product attention, but the expensive cache state is smaller.
This is why GQA feels like an engineering-minded evolution rather than a conceptual break. You still have a normal transformer block, the same general training recipe, and the same mental model of attention. You are just storing less state per token.
Why It Became The Default
Compared with more radical efficiency ideas, GQA is easy to justify. It does not introduce a latent compression scheme like MLA, it does not localize attention like SWA, and it does not replace attention altogether like Gated DeltaNet hybrids. It is simply a cleaner operating point for the same decoder pattern. That is why it shows up everywhere from small dense models to larger MoE systems.
In practice, GQA is also highly composable. Models often stack it with other tricks rather than choosing it instead of them. Gemma combines GQA with sliding-window attention. Many MoE models keep GQA for the attention side while using sparsity only in the feed-forward blocks.
How To Read It In The Gallery
On the gallery page, GQA usually appears in models that otherwise look fairly conventional: Llama, Qwen, Gemma, Mistral Small 3.1, GPT-OSS, and many of the dense comparison baselines. If a card says something like GQA with RoPE or GQA with alternating sliding-window and global layers, that means the model is still using grouped-query attention as its base attention mechanism, but it is layering another efficiency idea on top.