Multi-Head Latent Attention (MLA)
Multi-Head Latent Attention is DeepSeek’s answer to the same KV-cache bottleneck that made GQA popular, but it attacks the problem more directly by compressing what gets stored.
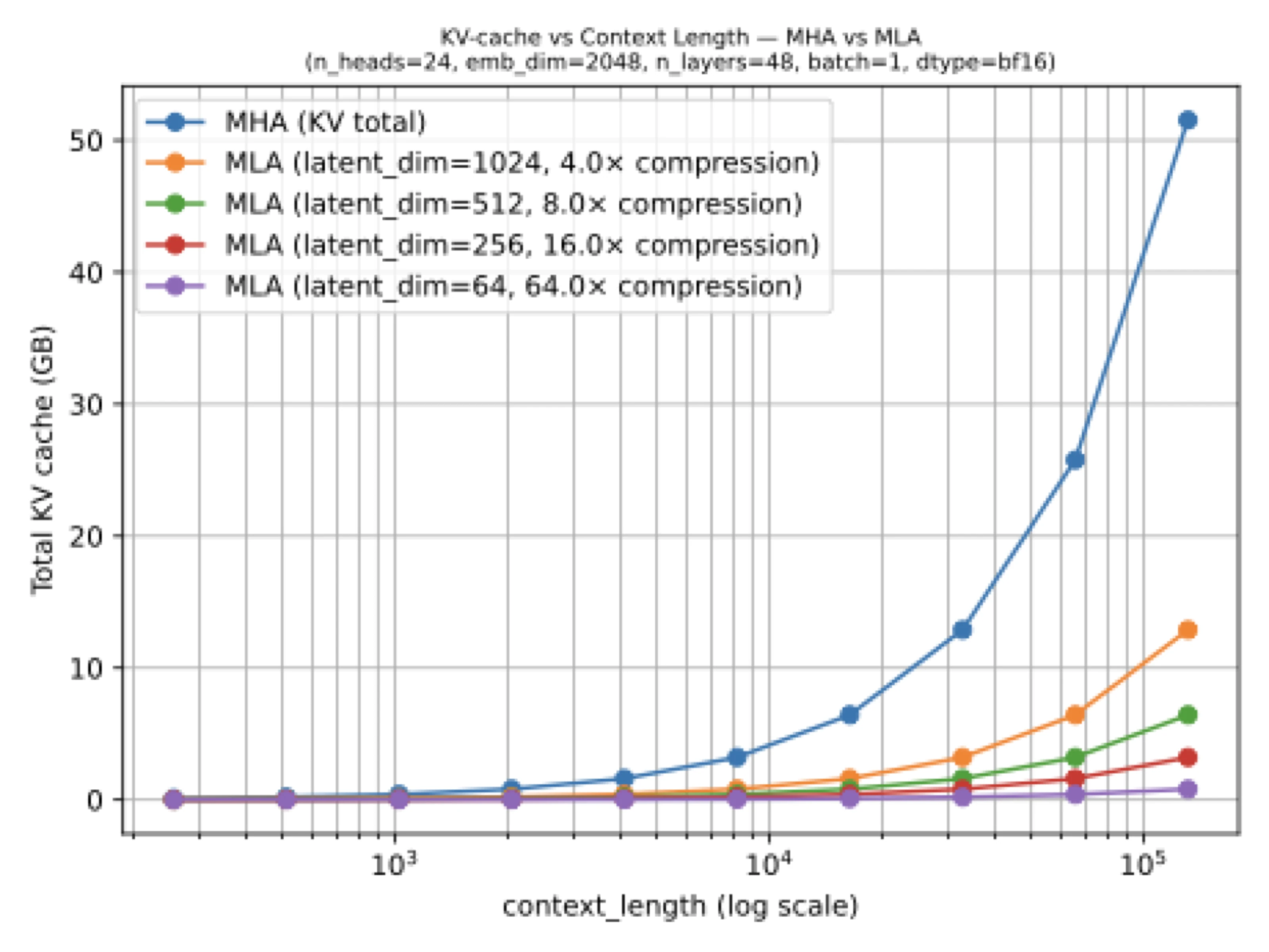
Instead of sharing keys and values across query heads, MLA compresses them into a latent representation for the KV cache and reconstructs them when needed. That makes MLA more invasive than GQA, but potentially more powerful, which is why it became a defining feature of DeepSeek-style architectures.
temp/LLMs-from-scratch/ch04/05_mla/plot_memory_estimates_mla.py.
Why It Exists
In the architecture article, I introduced MLA by first stepping through GQA. That comparison matters because the two ideas are solving the same practical problem: KV caching makes autoregressive decoding expensive at long context lengths. GQA shrinks the cache by reducing the number of key-value heads. MLA shrinks it by storing a compressed latent representation instead of the full-resolution keys and values.
That is the key mental model: MLA is not “shared heads.” It is “compressed cache state.”
What Changes In The Block
The attention mechanism now carries extra projection logic. During inference, the model stores the compressed latent tensors in the cache and reconstructs the usable key-value states from them when it performs attention. So the saving comes from storing less, not from reducing the number of query heads.
This is why MLA feels more architectural than GQA. It changes the shape of the internal attention computation and asks more of the serving stack. But if you are building a very large model where KV memory dominates, that extra complexity can be worth it.
Why DeepSeek Chose It
One of the strongest arguments for MLA came from the DeepSeek-V2 ablations discussed in the article and the local chapter notes. There, GQA looked weaker than full MHA, while MLA held up much better and even slightly exceeded the MHA baseline in some comparisons. That is a strong reason to accept the extra implementation complexity: MLA is not merely a serving trick, it can also be a quality-preserving one.
This is also why MLA became associated with the DeepSeek family and its descendants. Once a model family proves that a more complicated attention mechanism pays off at scale, others start inheriting the same recipe.
How To Read It In The Gallery
On the gallery page, MLA is usually a signal that the model is optimized for frontier-scale inference rather than minimal implementation complexity. DeepSeek V3, Kimi K2, GLM-5, and Mistral 3 Large all use it in different ways. In hybrid models like Kimi Linear, you can also see MLA paired with an even more aggressive linear-attention idea, which shows that these efficiency techniques are not mutually exclusive.