Mixture of Experts (MoE)
Mixture of Experts is arguably the architectural trick that defined the recent open-weight frontier wave.
MoE lets a model be huge in total capacity while keeping only a small fraction of that capacity active for any given token. That is why models like DeepSeek V3, GPT-OSS, GLM-5, and Mistral 3 Large can look enormous on paper without making every inference step pay for the full dense parameter count.
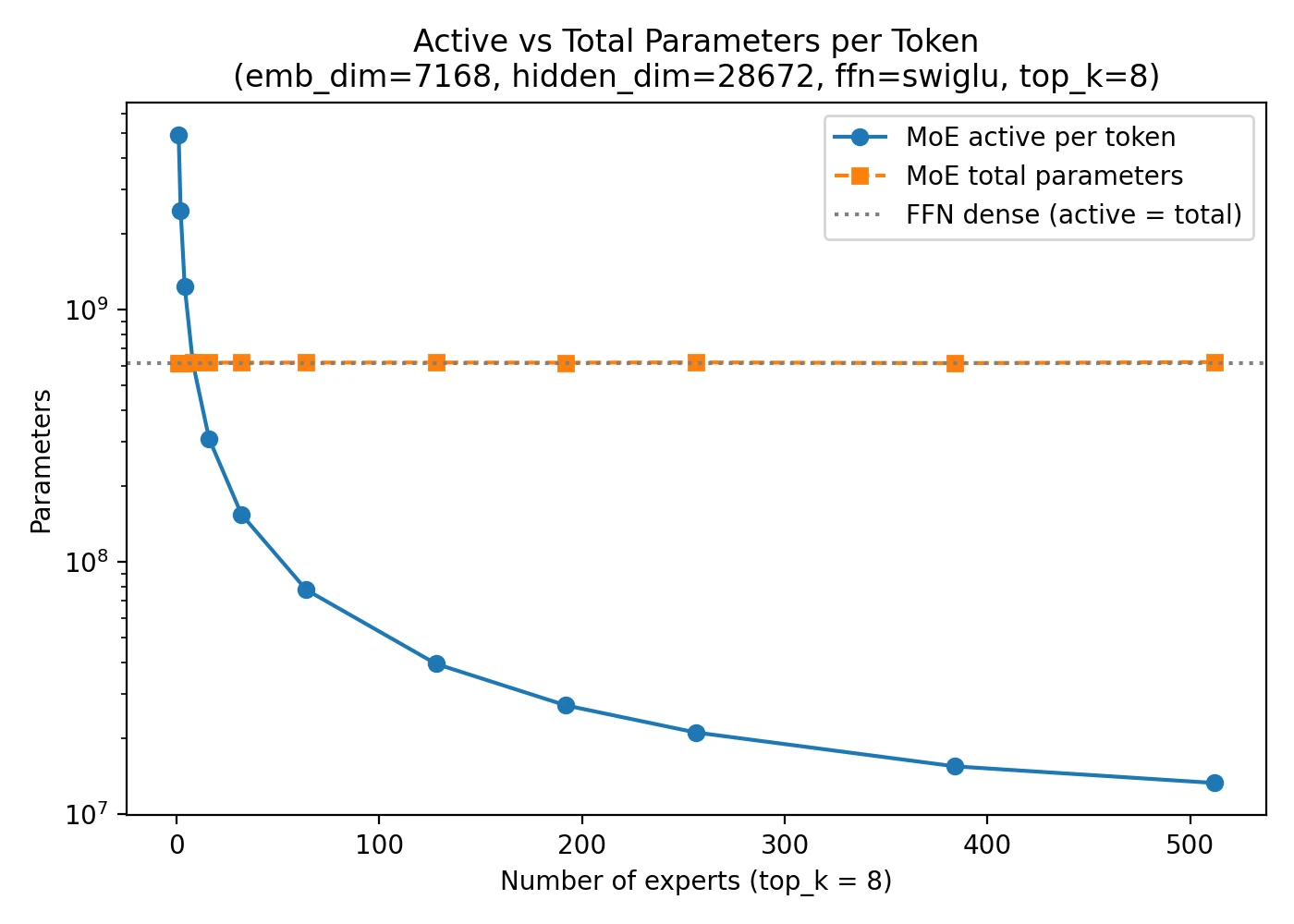
temp/LLMs-from-scratch/ch04/07_moe/plot_memory_estimates_moe.py.
Why It Exists
The feed-forward block already holds a large share of the parameters in a transformer layer. MoE takes advantage of that by replacing one feed-forward block with many expert feed-forward blocks and then using a router to activate only a few of them per token. In the article, I described this as the key trick: total capacity goes up dramatically, but the active path stays much smaller.
That is why MoE changes the economics of scaling. You can train a much larger model than a dense decoder with the same active footprint, while still keeping inference practical enough to matter.
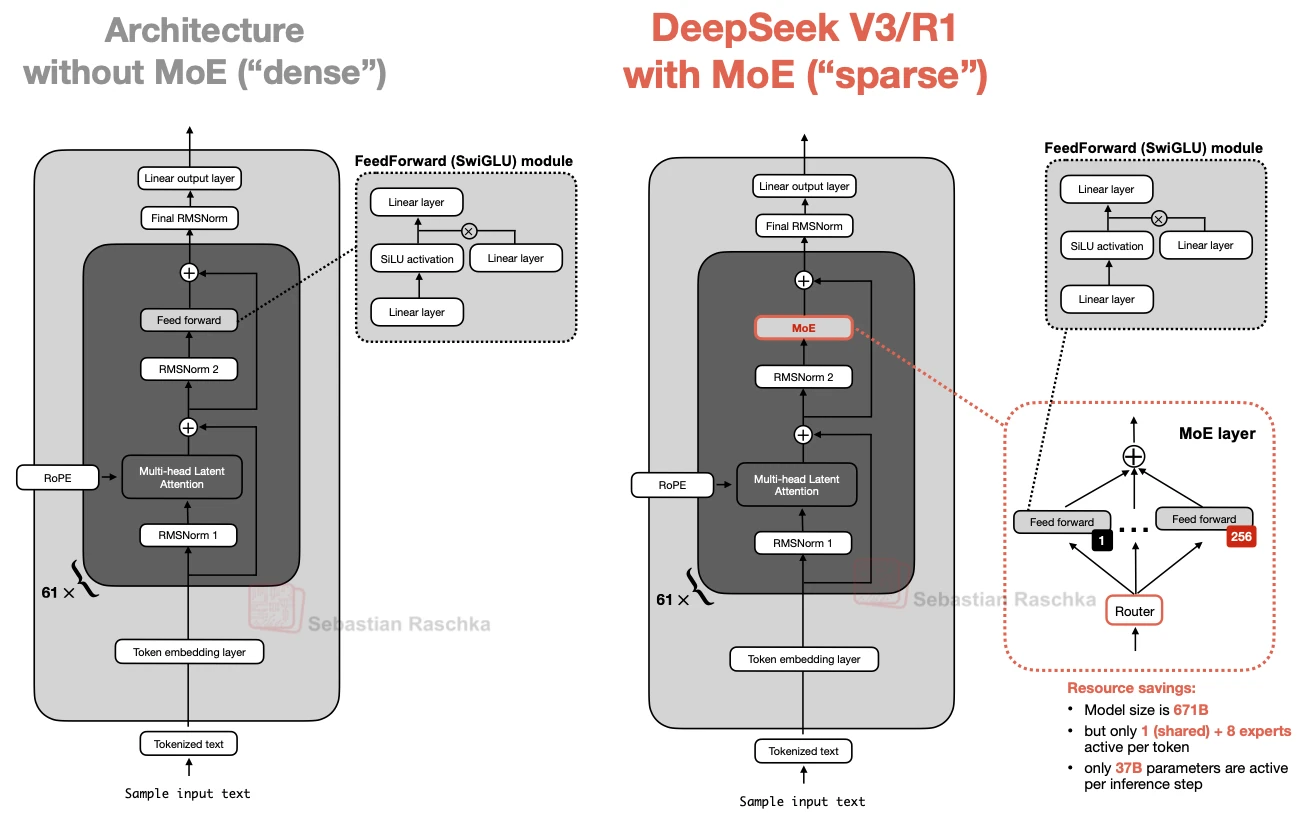
What “Sparse” Really Means
A sparse MoE layer is not sparse because the model is tiny. It is sparse because not all experts run for every token. DeepSeek V3 is the canonical example: a huge total parameter count, but only a relatively small active subset per step. That is also why MoE model cards often list two numbers: total parameters and active parameters.
The plot above makes the intuition visible. As expert count increases, the total parameter count rises quickly, while the active count per token grows much more slowly. That gap is the whole point of MoE.
Why Shared Experts Matter
One of the more interesting ideas that came back into the spotlight with DeepSeek-style models is the shared expert: an expert that is always active, no matter what the router does. The rationale, as noted in both the article and the local chapter notes, is that common patterns do not need to be relearned redundantly across many routed experts. That leaves the routed experts with more room to specialize.
This detail matters because not all MoEs are the same. Two models may both be called MoE while making very different choices about expert count, expert size, routed experts per token, and whether there is a shared expert.
How To Read It In The Gallery
On the gallery page, MoE is the dividing line between the dense and sparse camps. DeepSeek V3, Qwen MoE models, GPT-OSS, GLM-5, and many late-2025 frontier systems all use it. When a fact sheet says something like 671B total, 37B active, that is the MoE story in one line: huge total capacity, much smaller per-token cost.