Gated DeltaNet
Gated DeltaNet is part of the recent return of linear-attention hybrids: models that keep a transformer backbone but replace most full-attention layers with something cheaper.
In the recent Qwen3-Next and Kimi Linear family, the pattern is not to throw away attention completely. Instead, most layers use a Gated DeltaNet-style state update, and every few layers fall back to a heavier full-attention layer. That hybrid structure is the important idea to keep in mind.
temp/LLMs-from-scratch/ch04/08_deltanet/plot_memory_estimates_gated_deltanet.py.
Why It Exists
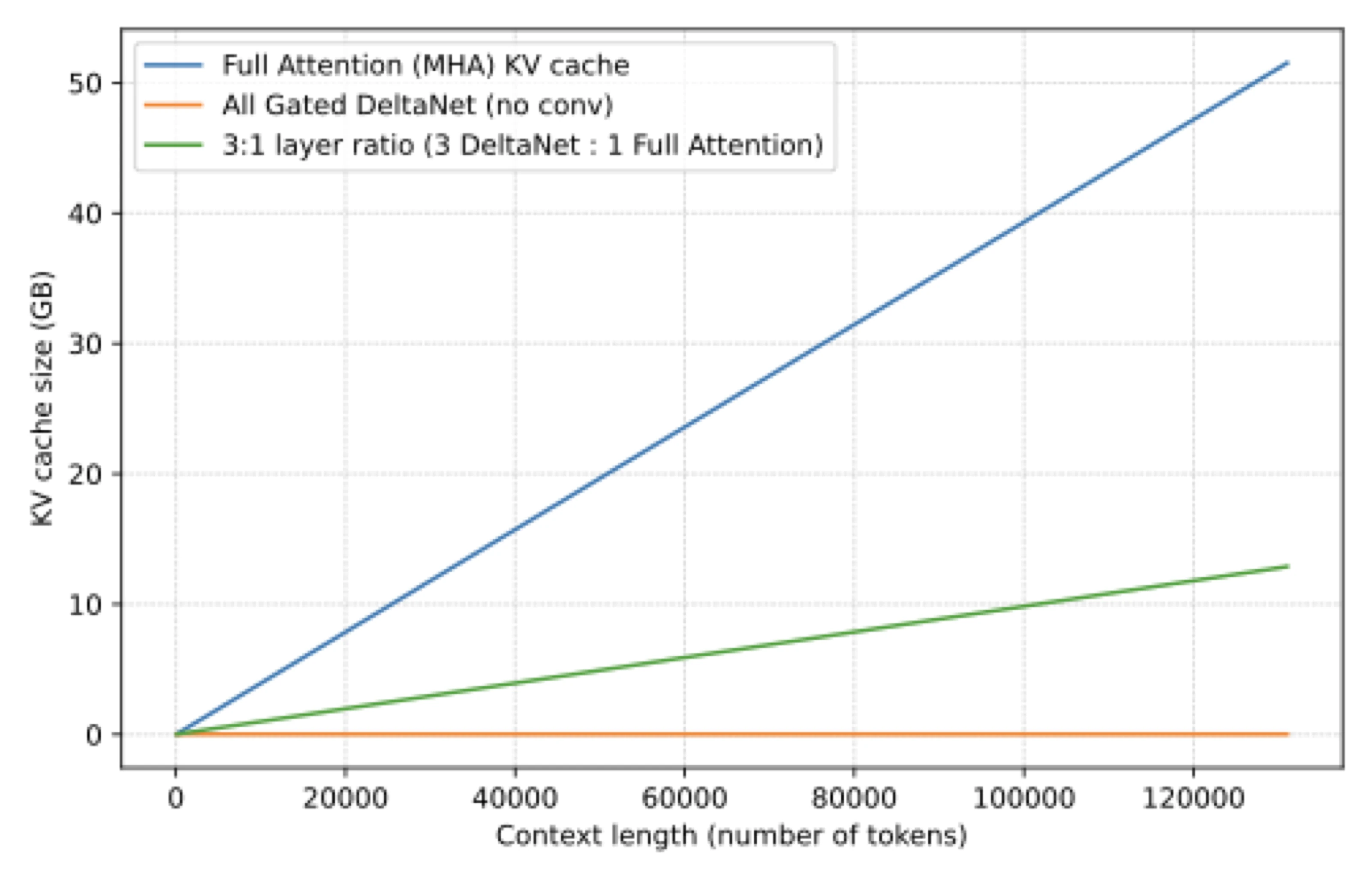
Standard attention scales quadratically with context length, which is why long-context models keep searching for alternatives. In Beyond Standard LLMs, I used Qwen3-Next and Kimi Linear to illustrate the recent revival of linear attention. Gated DeltaNet is one of the clearest examples because it shows a practical compromise: replace most full-attention layers with a recurrent memory update, but keep some full-attention layers in the stack so the model still has periodic global mixing.
That is why these models often use a 3:1 ratio: three linear-attention style layers, one full-attention layer, then repeat.
What It Actually Does
Gated DeltaNet does not build the usual token-by-token attention matrix. Instead, it processes tokens sequentially and maintains a running state that gets updated over time. In that sense it has a recurrent flavor, which is also why it is often discussed alongside state-space ideas and RNN-inspired mechanisms.
The “gated” part matters too. As the local chapter notes explain, the mechanism uses gates both to control the output and to regulate how the memory state decays and updates. Kimi Linear then pushes the idea further with a channel-wise refinement called Kimi Delta Attention.
Why Hybrid Beats Full Replacement
The figure above shows the attraction clearly: memory growth is dramatically flatter than in full attention. But there is a catch. Full attention can access prior tokens directly. Gated DeltaNet has to compress the past into a fixed-size memory state. That is efficient, but it is also a bottleneck. This is exactly why the recent models do not use it everywhere. They mix it with full attention instead of betting the whole model on one mechanism.
That hybrid interpretation is more useful than thinking of Gated DeltaNet as a drop-in replacement for standard attention. In current practice, it is an efficiency-biased layer inside a larger transformer recipe.
How To Read It In The Gallery
On the gallery page, Gated DeltaNet mainly shows up in Qwen3-Next, Qwen3.5, and the coding-specialized Qwen3-Coder-Next variant. Those cards typically mention a 3:1 hybrid of Gated DeltaNet and gated attention. Kimi Linear belongs to the same family of ideas, but it swaps the full-attention layers toward MLA instead.