Sliding Window Attention (SWA)
Sliding Window Attention is the cleanest way to make attention cheaper without replacing the attention mechanism itself.
Instead of letting every token attend to the full prefix in every layer, SWA makes many layers local: each token only sees a recent window. That sounds restrictive, but the recent Gemma and OLMo examples show that if you mix local and global layers carefully, the efficiency win can be large while the quality hit stays small.
temp/LLMs-from-scratch/ch04/06_swa/plot_memory_estimates_swa.py.
Why It Exists
Once context lengths move into the tens or hundreds of thousands of tokens, using global attention everywhere is expensive. Sliding window attention is a straightforward compromise: keep the standard attention mechanism, but stop paying for full visibility in every layer. In the architecture article, I described this as shifting from a global attention mechanism to a more local one.
The nice thing about SWA is that it is easy to reason about. You are not changing the nature of attention. You are changing how much past context each layer is allowed to see.
How Modern Models Use It
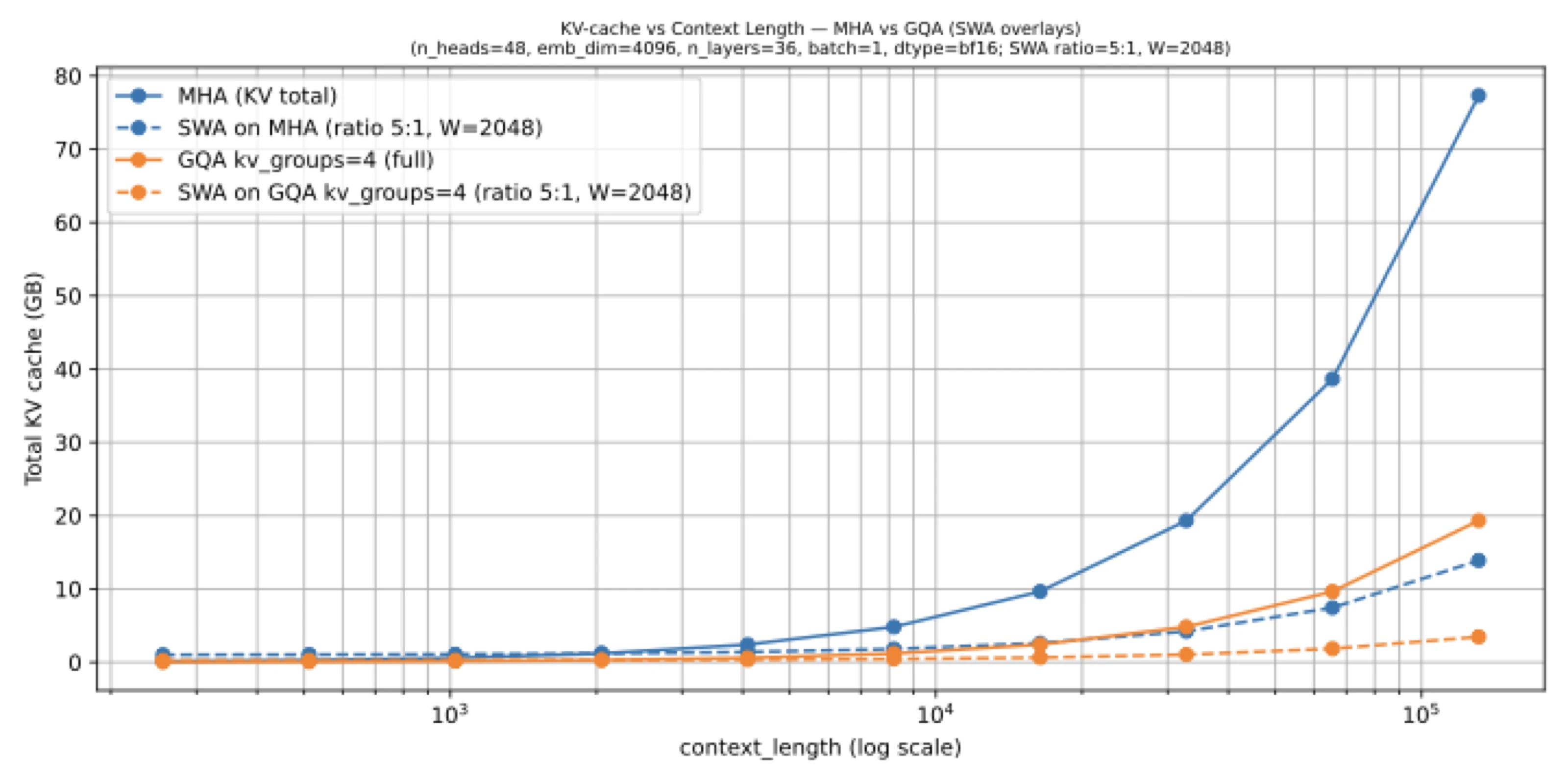
The modern pattern is not “all local, all the time.” Gemma 2 mixed sliding-window and global attention in a 1:1 ratio with a 4k local window. Gemma 3 pushed the idea further toward efficiency: a 5:1 local-to-global ratio and a smaller 1024-token local window. The notable part is that the reported quality drop was small, which is exactly why SWA started feeling practical rather than experimental.
In other words, SWA works best as a distribution of labor across layers. Most layers are cheap and local; a few layers refresh the model’s access to global context.
Why It Pairs Well With GQA
The local chapter notes make an important point here: Gemma 3 uses sliding-window attention together with GQA. That pairing is common because the two ideas hit different parts of the same problem. SWA reduces how much context a local layer has to consider. GQA reduces how much key-value state each token contributes. Used together, they shrink long-context cost from two sides at once.
How To Read It In The Gallery
On the gallery page, SWA often appears as a modifier rather than a whole architectural identity: “GQA with sliding-window layers,” “alternating sliding-window and global layers,” or a model note that only some layers use full attention. That is a good way to interpret it in practice. SWA is usually one efficiency dial inside a broader transformer design, not a replacement for the transformer itself.