Mixture of Experts (MoE)
Mixture of Experts is one of the main reasons recent open-weight models can have very large total parameter counts without making every inference step equally expensive.
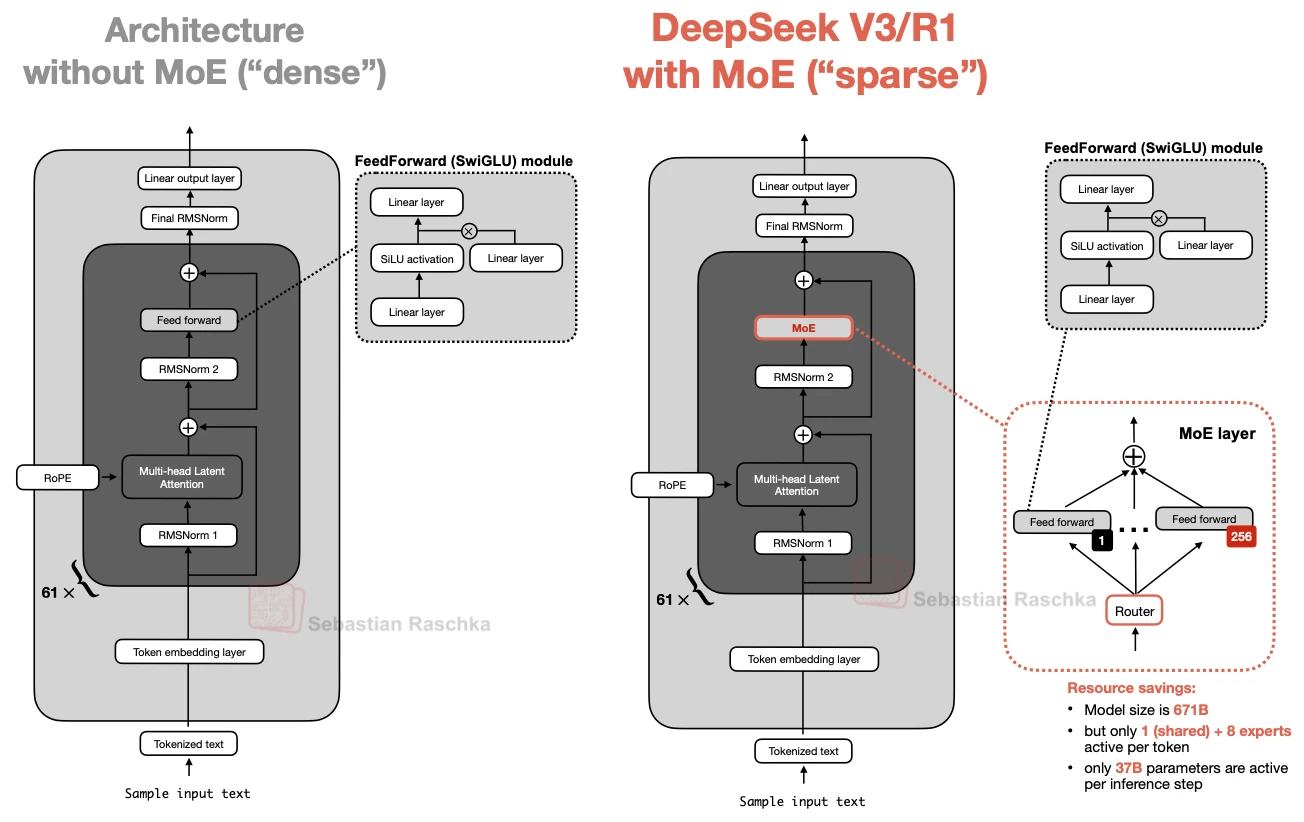
The basic idea is to replace a single dense FeedForward block with multiple expert FeedForward blocks and then use a router so that only a small subset is active for each token.
What changes
One dense feed-forward path becomes several expert feed-forward paths plus a router
Practical benefit
The model can have much higher total capacity while keeping only a smaller active path per token
Example architectures
DeepSeek V3, Qwen3 235B-A22B, GPT-OSS 120B, Mistral Large 3, GLM-5 744B, and MiniMax M2 230B
Why It Matters
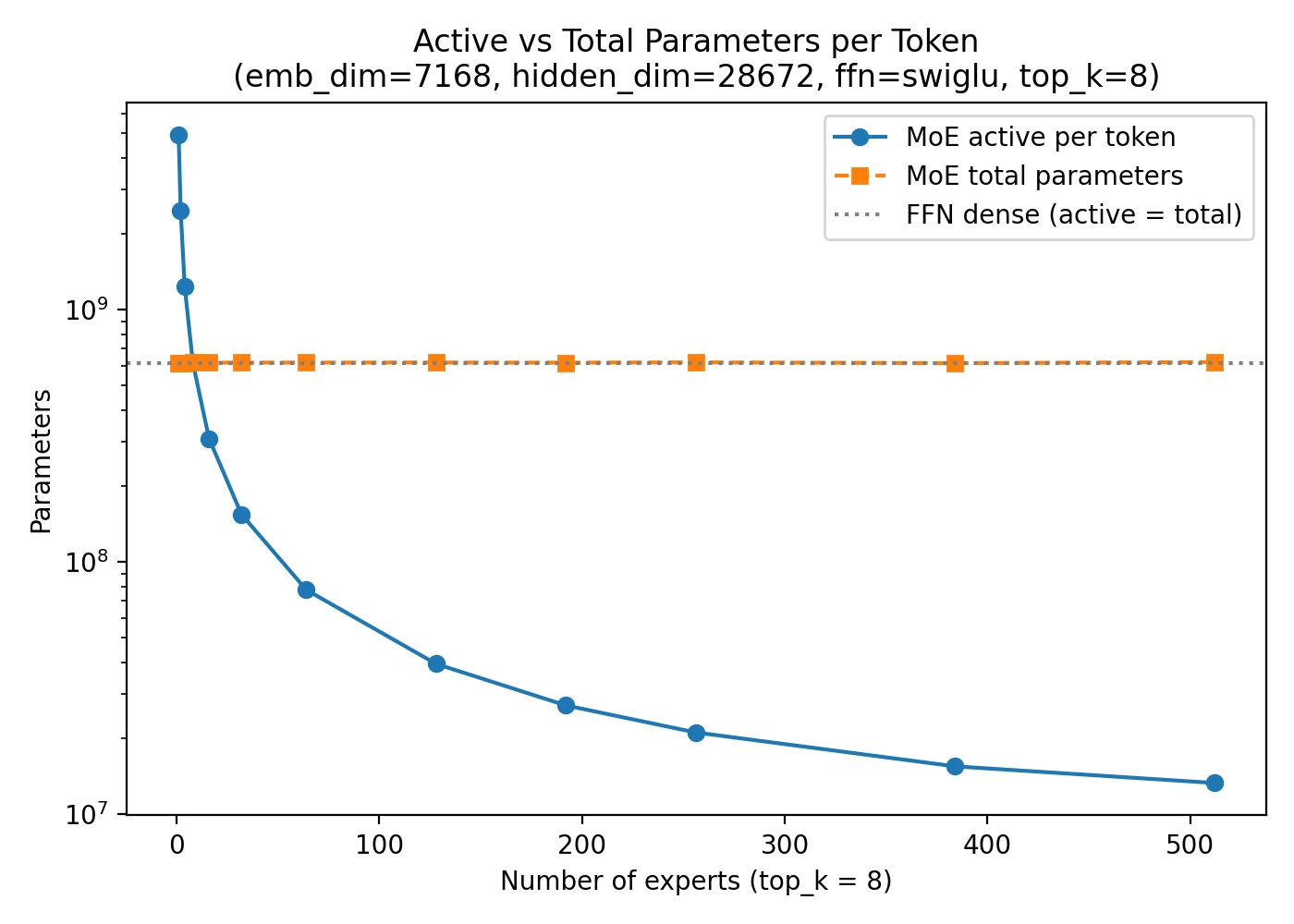
The FeedForward block already accounts for a large share of the parameters inside a transformer layer. So when we replace one FeedForward block with many expert blocks, the model’s total parameter count can increase substantially.
The key point is that the router does not activate all experts for every token. It selects only a small subset. That is why an MoE model can be very large in total capacity while still using a much smaller number of active parameters on each inference step.
What “Sparse” Means Here
MoE layers are often described as sparse because not all experts are used for every token. The model is large, but the computation per token is selective.
This is why MoE model cards often list both total parameters and active parameters. DeepSeek V3 is the standard example: the total size is very large, but only a much smaller subset is active per step.
Shared Experts And Variants
Once the basic MoE idea became common, teams started to vary the details. One example is the shared expert, which is always active in addition to the routed experts. Another is latent MoE, where the expert computation is moved into a smaller latent space, as in Nemotron 3 Super.
So while many models are called MoE, they can still differ quite a bit in expert count, routed experts per token, whether they use shared experts, and how large the expert subnetwork is.
Example Architectures
- DeepSeek V3: the clearest MoE reference point in the gallery
- Qwen3 235B-A22B: a current large-scale open MoE model with GQA
- GPT-OSS 120B: a sparse MoE stack with alternating local and full attention
- Mistral Large 3: another DeepSeek-style MoE architecture
Sources