Chapter 4 Concept Guides
Chapter 4 is where the main modern decoder variations start to matter: KV-cache compression, local attention, sparse feed-forward layers, and linear-attention hybrids.
These pages turn the local temp/LLMs-from-scratch/ch04 bonus chapters into quick website guides,
with figures and examples pulled from the corresponding chapter scripts, later LLMs-from-scratch notebooks, and
linked architecture articles.
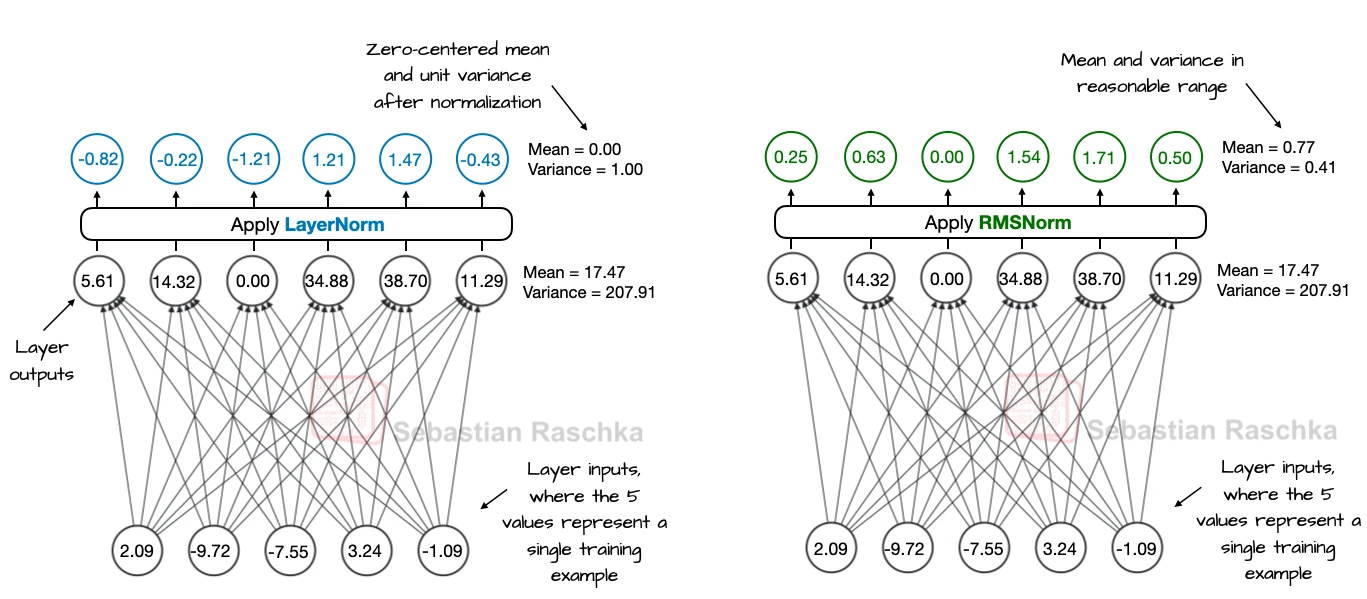
RMSNorm
A cheaper alternative to LayerNorm that keeps activation magnitudes stable without explicitly subtracting the mean.

Rotary Positional Embeddings (RoPE)
Encodes token position by rotating query and key vectors, which is why it replaced learned absolute position embeddings in most LLMs.
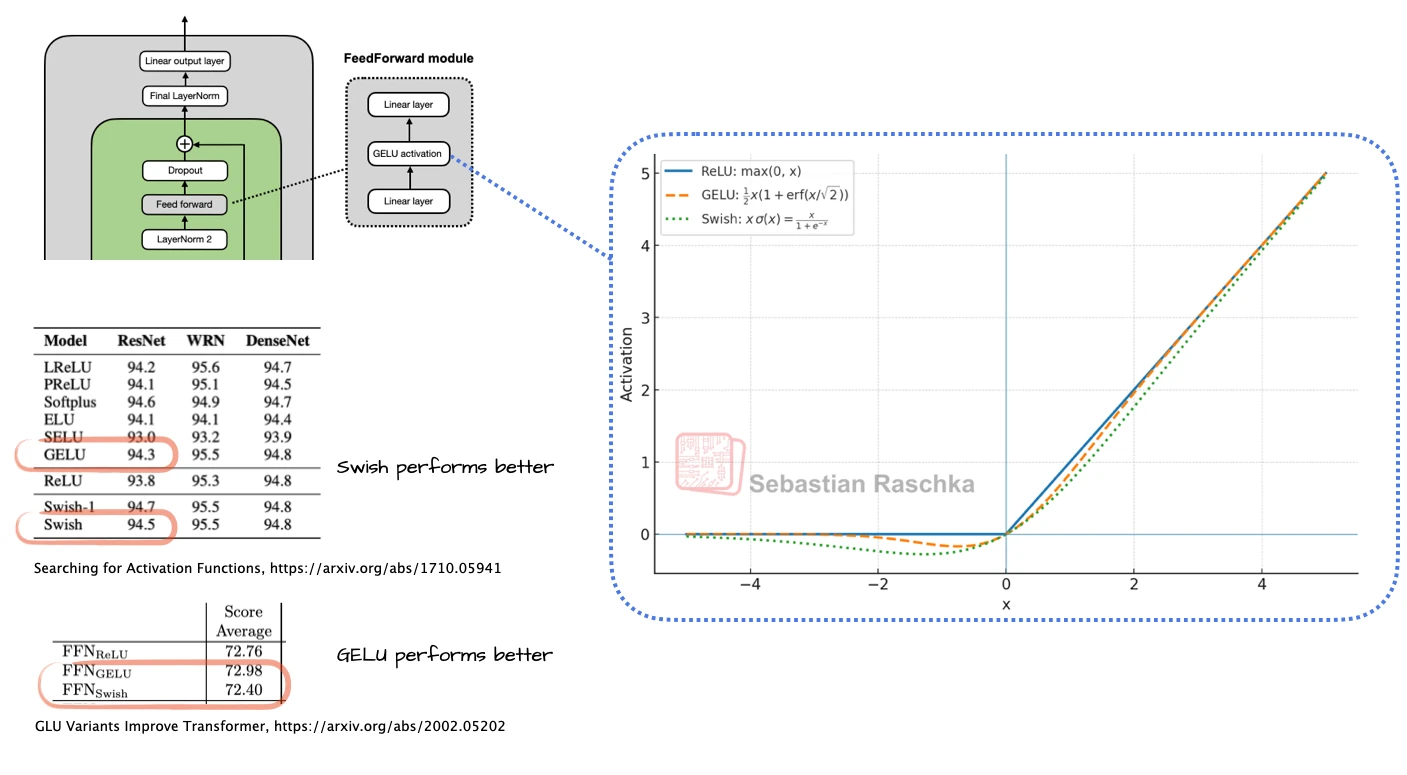
SiLU / Swish
The smooth activation behind modern SwiGLU feed-forward blocks, favored largely for efficiency and optimization stability.
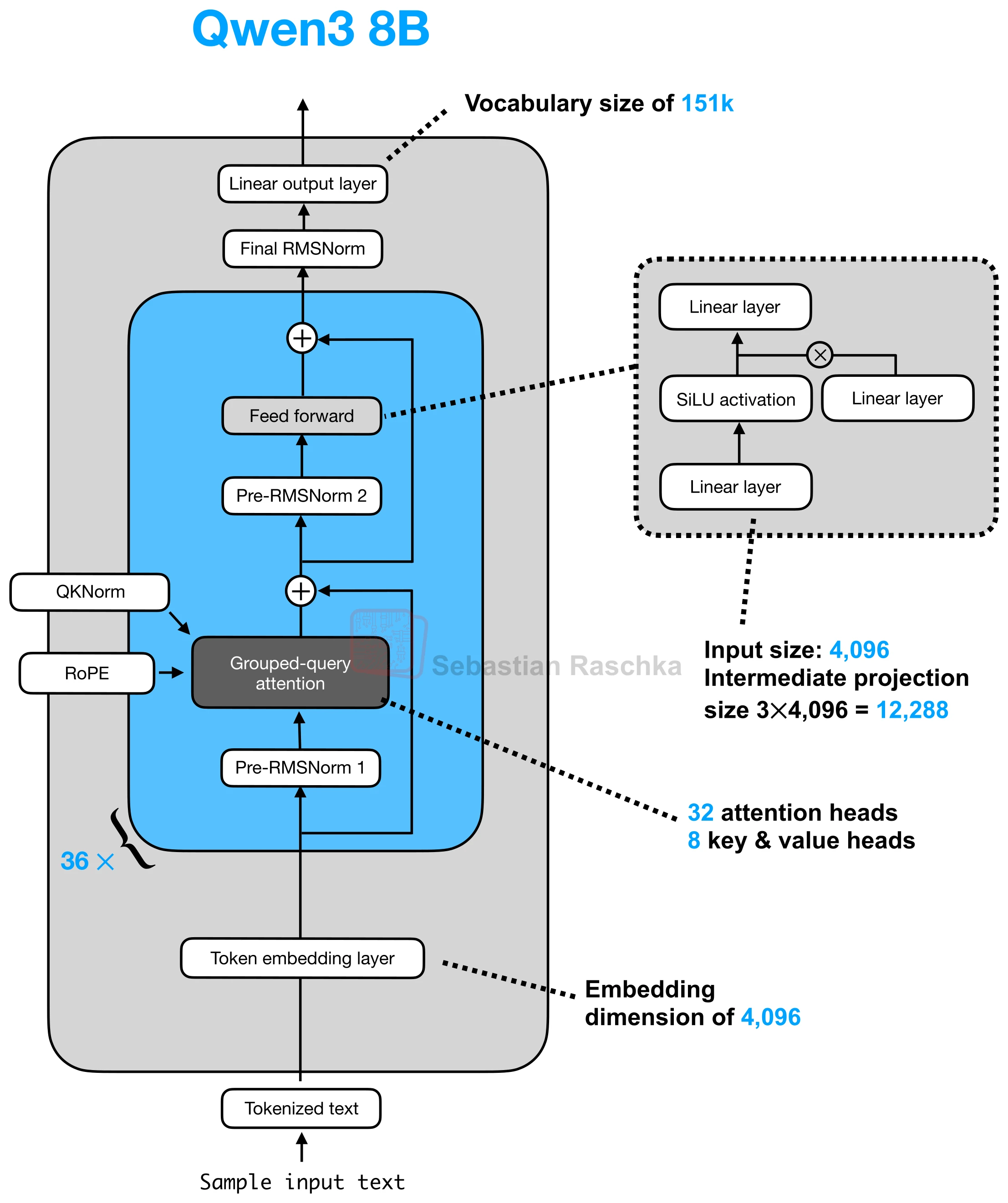
QK-Norm
Applies RMSNorm to queries and keys inside attention before RoPE, helping stabilize large-model training.
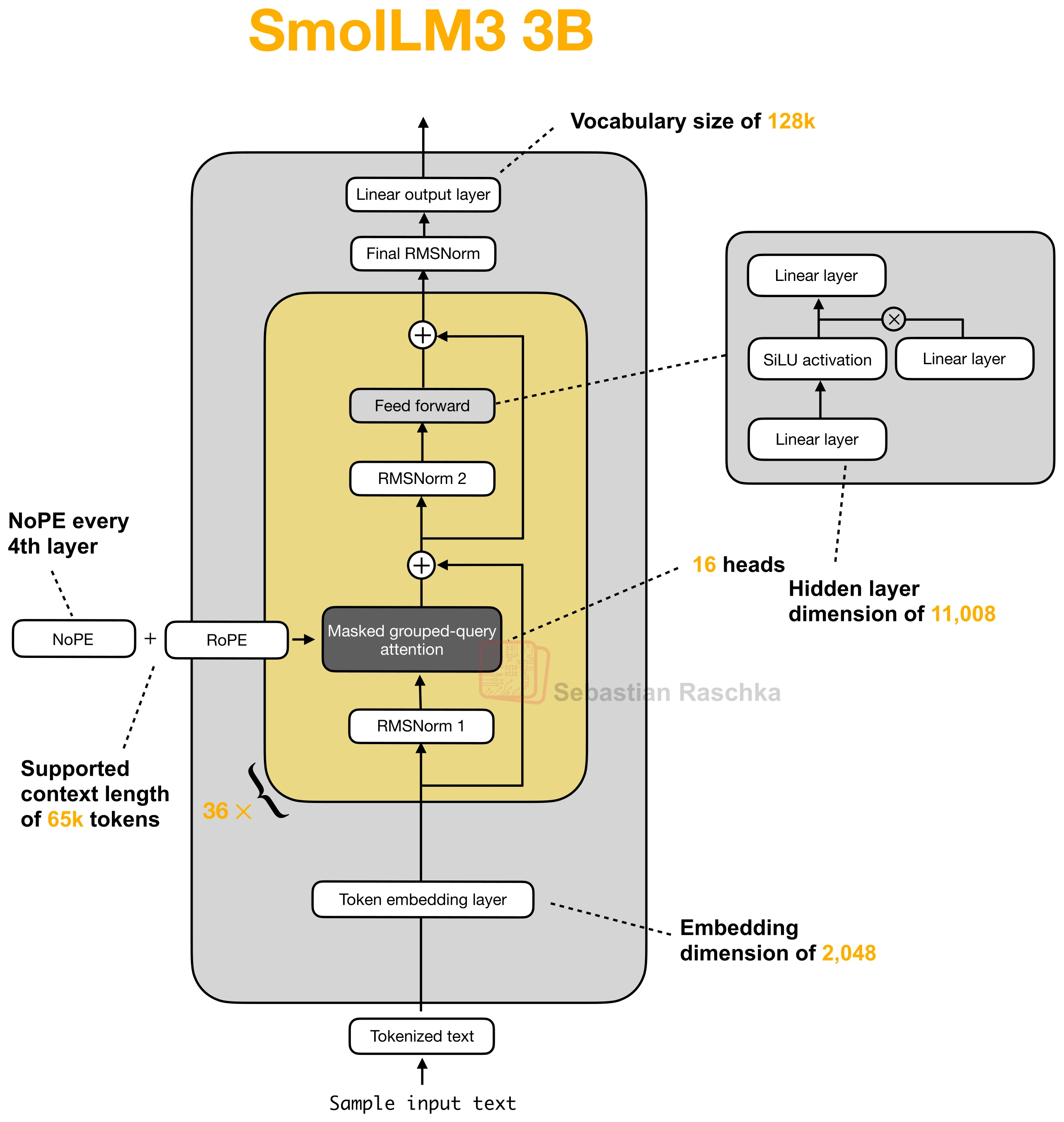
No Positional Embeddings (NoPE)
Drops explicit positional encodings in selected layers and relies on causal order plus learned behavior instead.
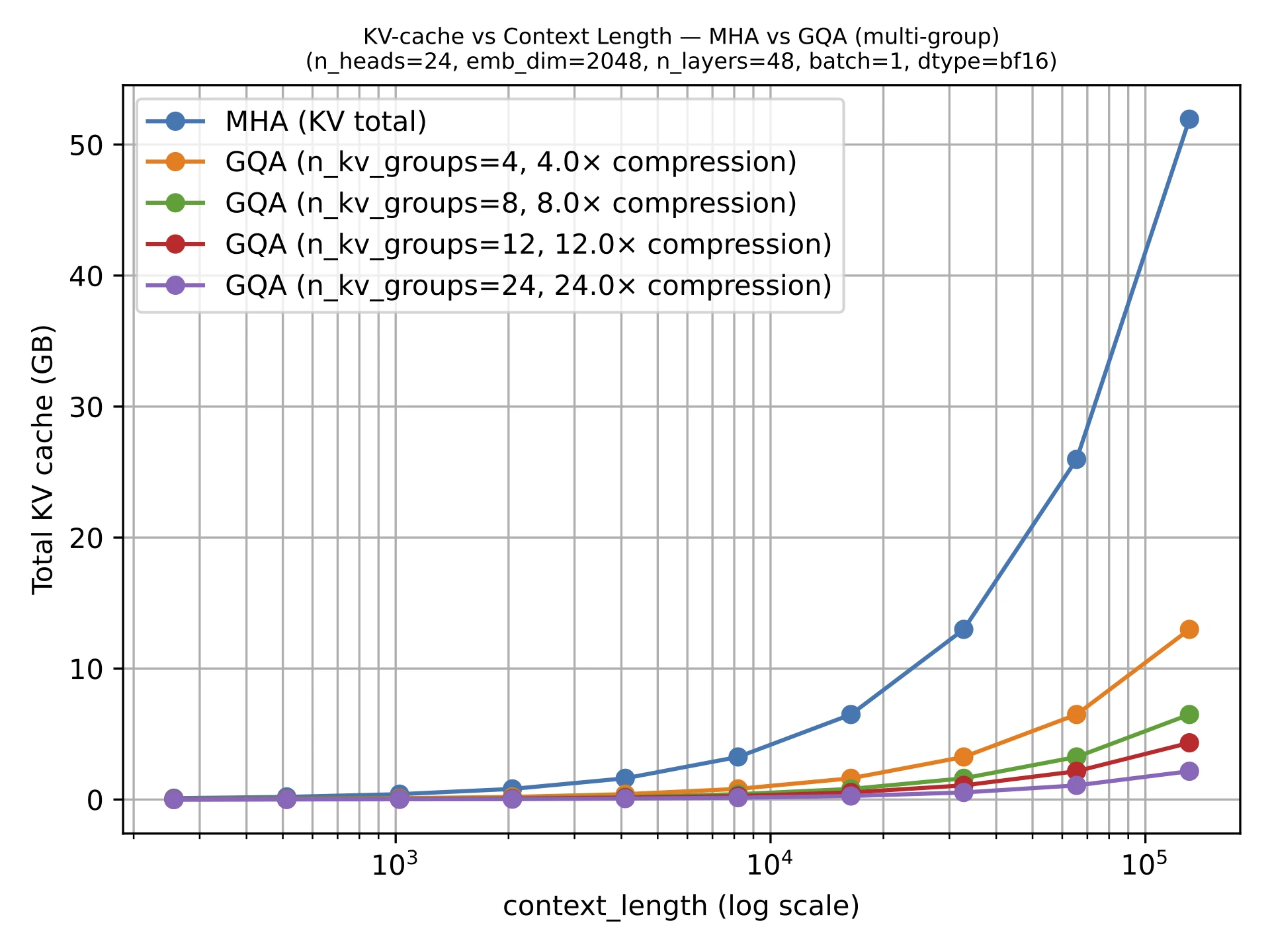
Grouped-Query Attention (GQA)
Multiple query heads share the same key-value projections, reducing KV-cache size without changing the overall decoder pattern.
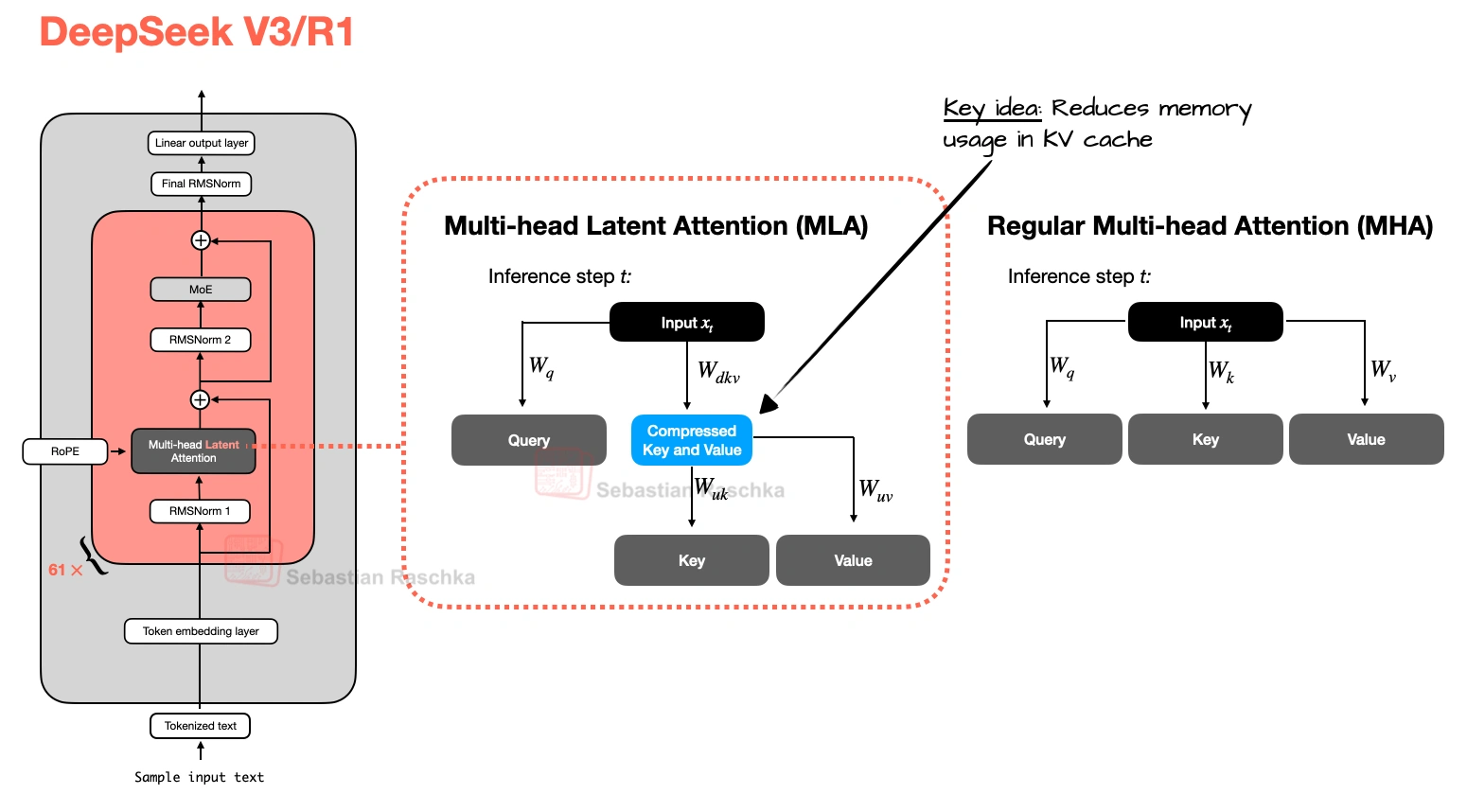
Multi-Head Latent Attention (MLA)
Compresses key-value state before it goes into the KV cache, which is why DeepSeek-style models use it.
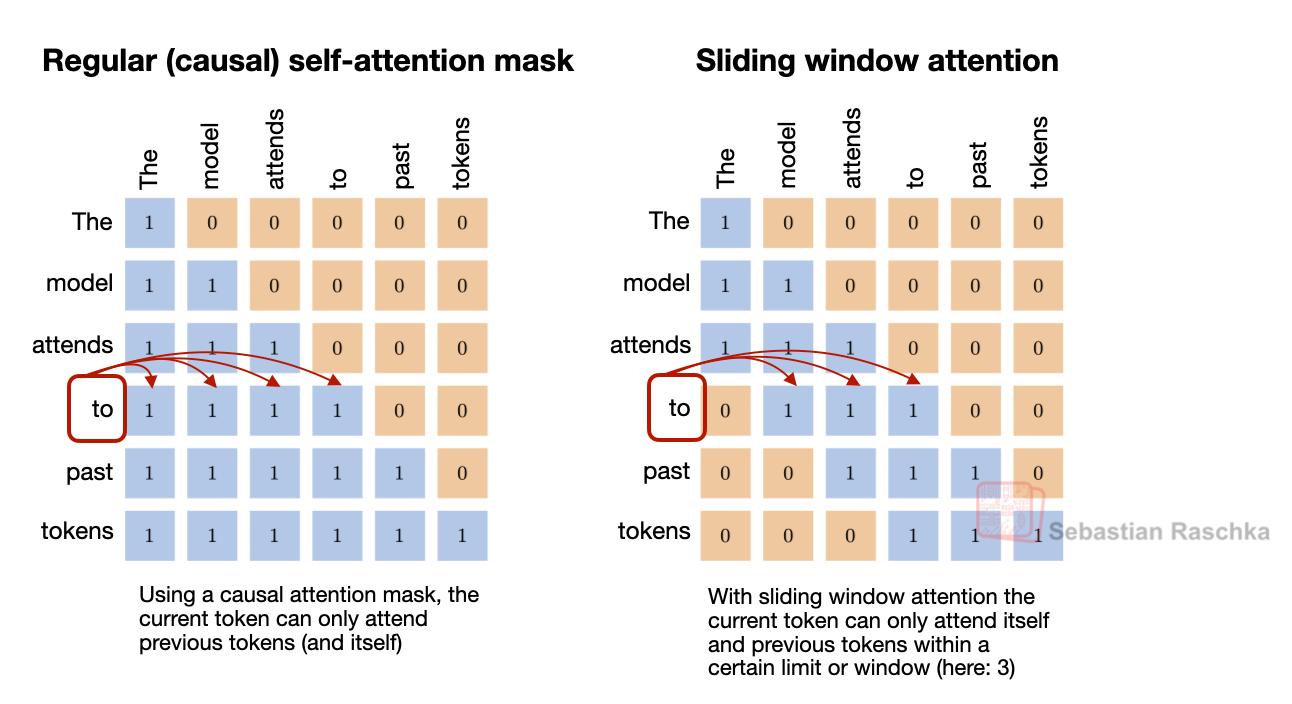
Sliding Window Attention (SWA)
Makes selected attention layers local by letting tokens see only a recent window instead of the full prefix.
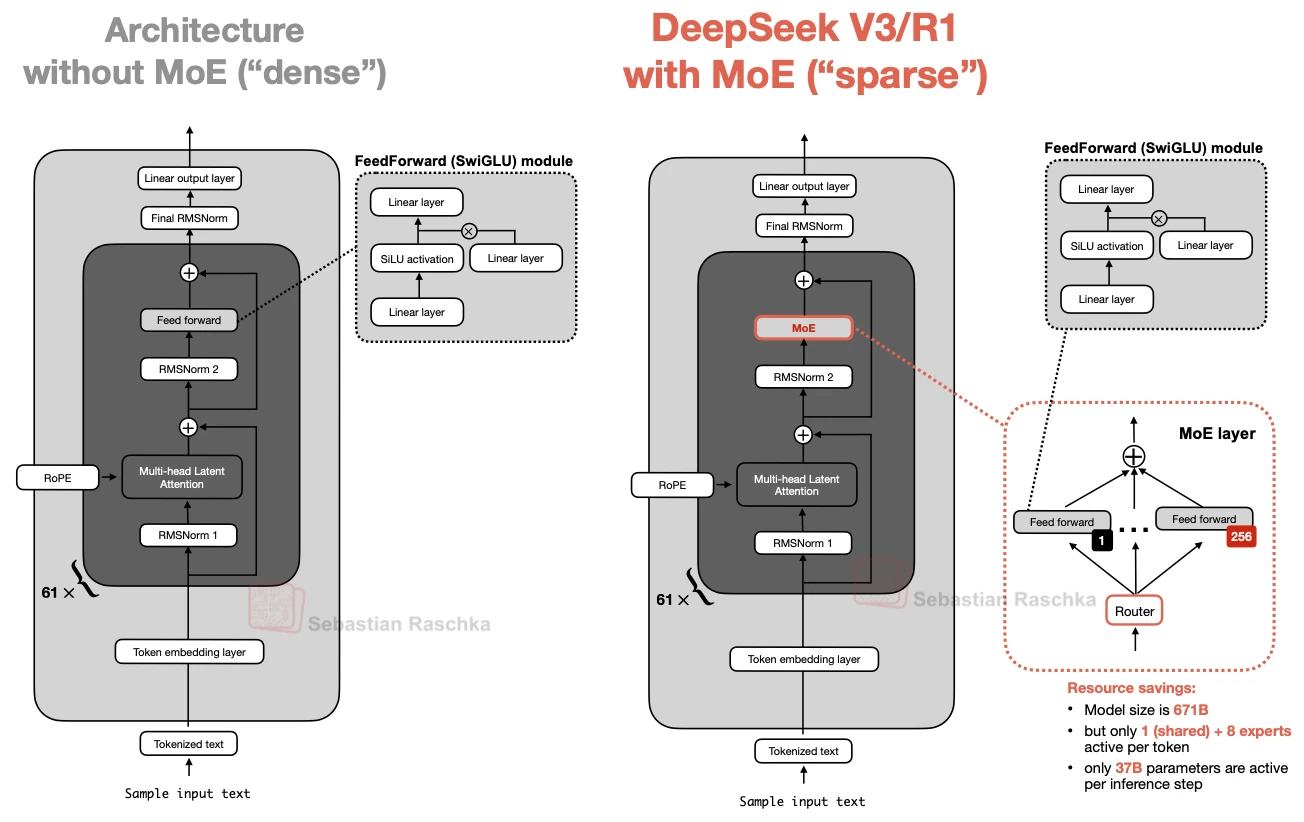
Mixture of Experts (MoE)
A sparse feed-forward setup where only a few experts are active per token, even though total model capacity is much larger.
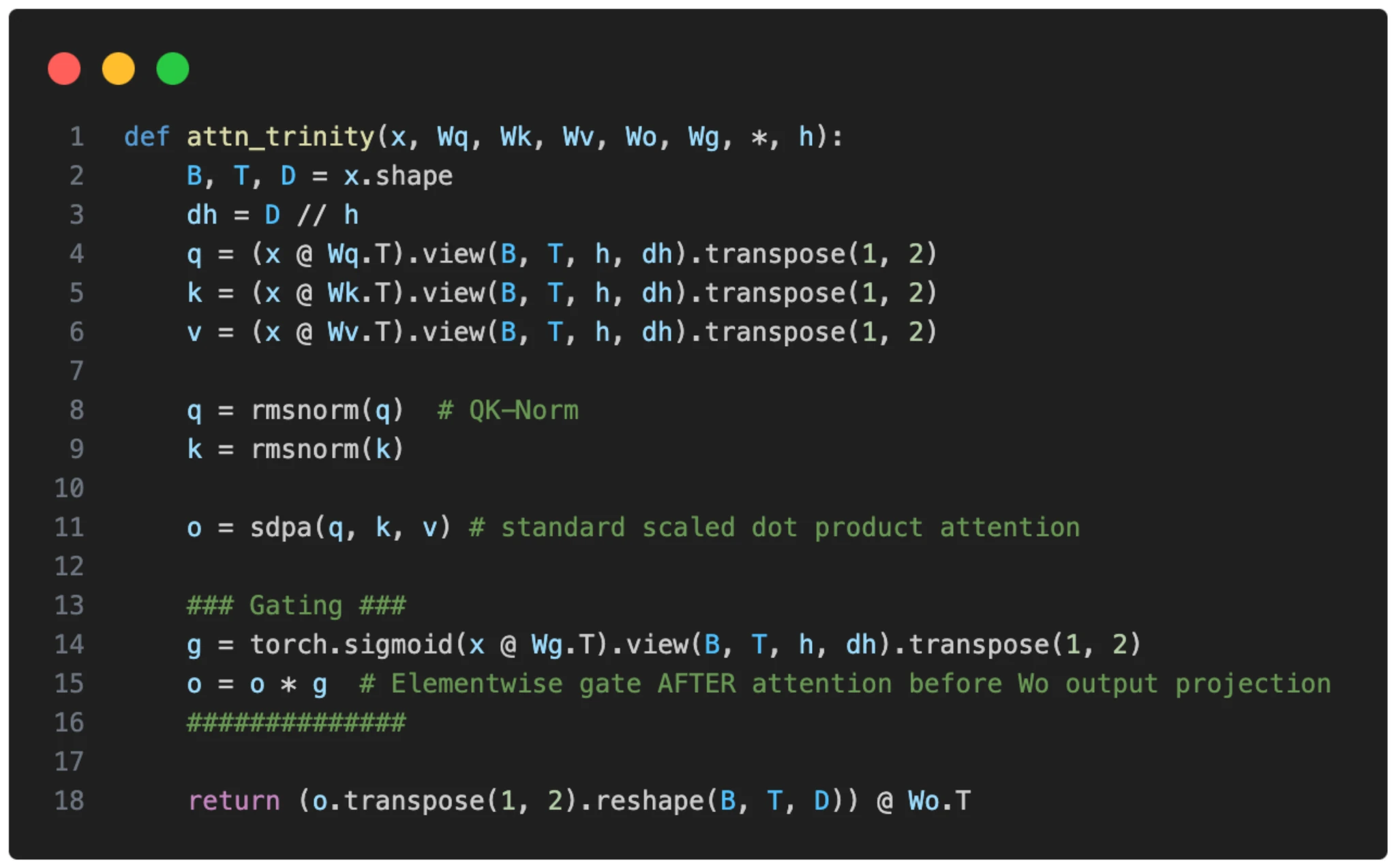
Gated Attention
A tuned attention block that keeps content-based attention but adds an output gate and a few stabilizing tweaks.
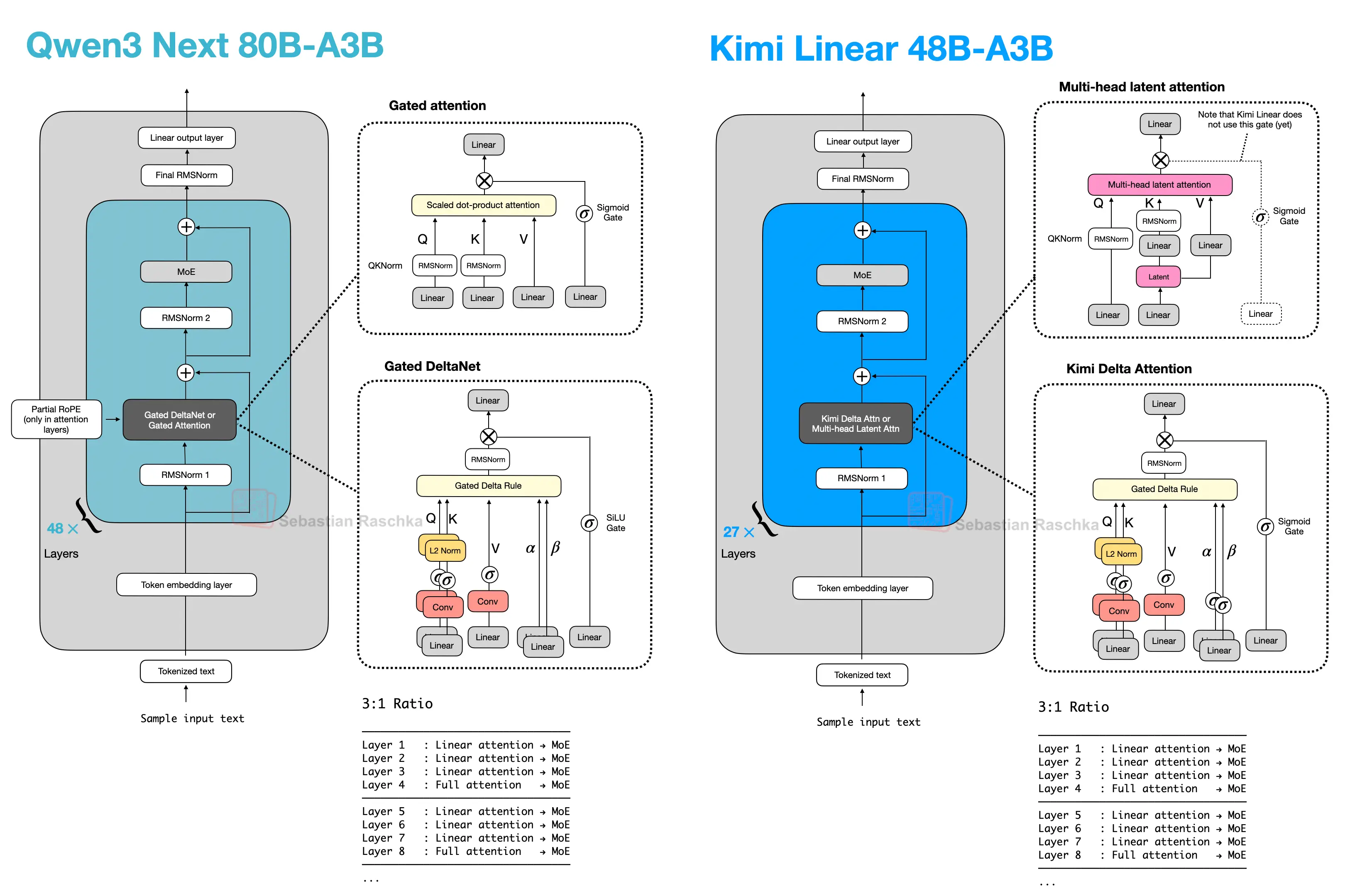
Hybrid Attention
A broader family of architectures that replaces most full-attention layers with cheaper linear or state-space sequence modules while keeping a smaller number of heavier retrieval layers.
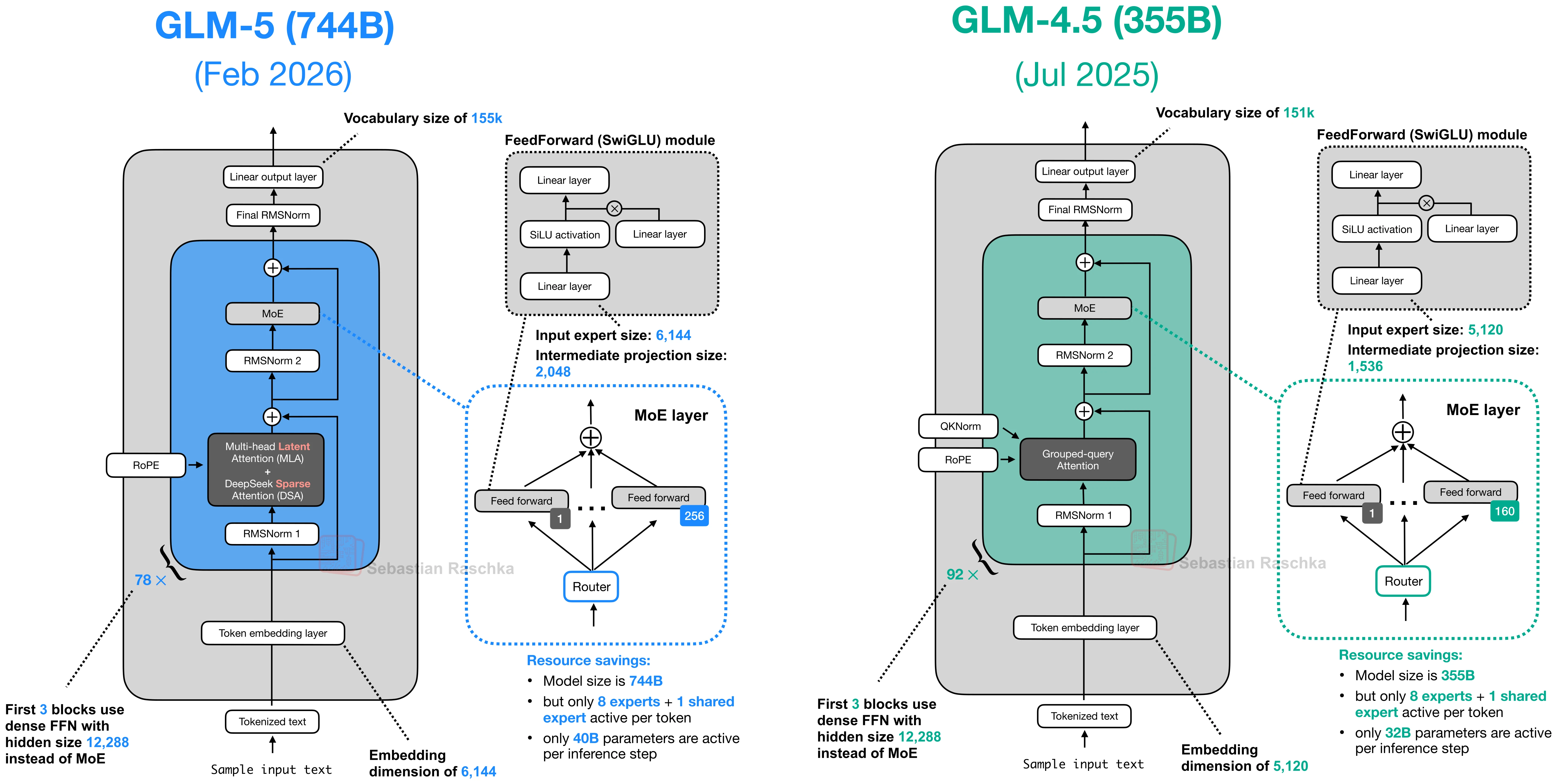
DeepSeek Sparse Attention
A learned sparse attention mask used to reduce long-context costs in DeepSeek V3.2- and GLM-5-style models.