CSA and HCA
Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA) are the long-context attention mechanisms used in DeepSeek V4. Both reduce the length of the KV cache by compressing groups of previous tokens into fewer KV entries.
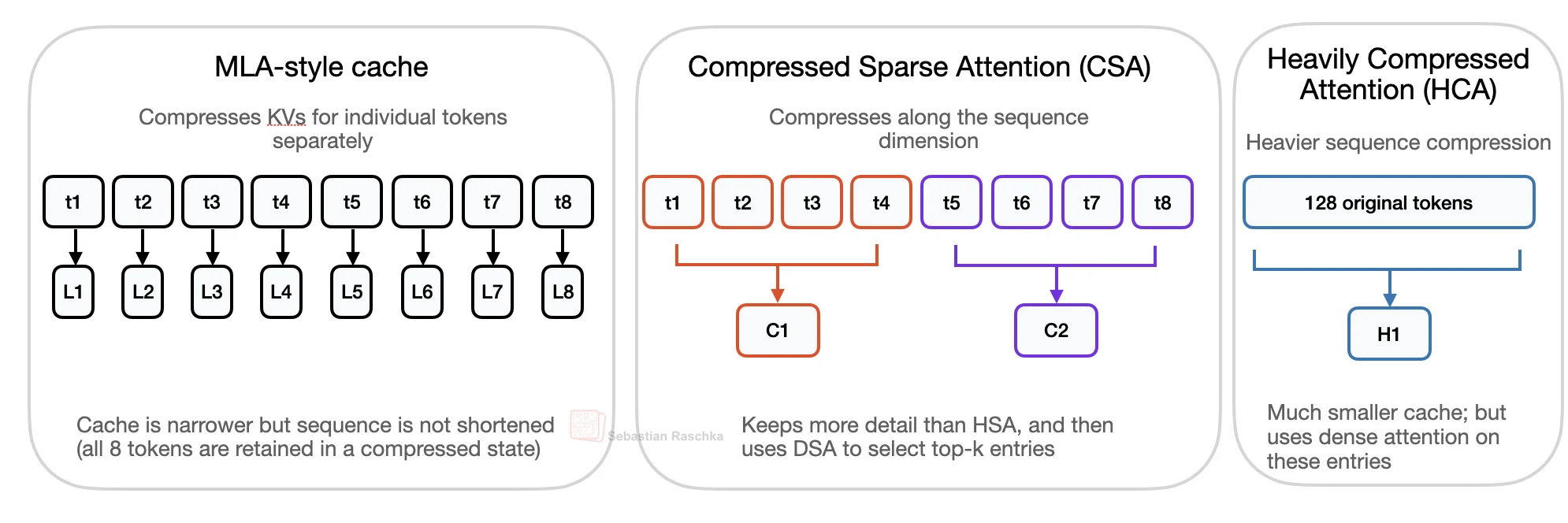
This is different from MLA-style per-token latent caching. MLA keeps one compressed latent entry per token. CSA and HCA shorten the sequence of cached entries, so the model has fewer past entries to store and attend over at million-token context lengths.
What changes
Past tokens are summarized into fewer compressed KV entries
Practical benefit
The long-context cache becomes shorter, reducing memory and attention cost
Example architectures
Sequence Compression
The main distinction is the compression axis. MLA mainly compresses the per-token KV representation. It still keeps one latent KV entry for each previous token.
CSA and HCA compress along the sequence dimension. Instead of keeping one entry per previous token, they summarize groups of tokens into fewer entries. This makes the stored history shorter.
In DeepSeek V4, CSA uses a milder compression rate. The figure example shows groups of 4 tokens being compressed into one entry, followed by sparse top-k selection. HCA is more aggressive. It compresses 128 tokens into one compressed KV entry and then attends densely over that shorter cache.
Why DeepSeek Uses Both
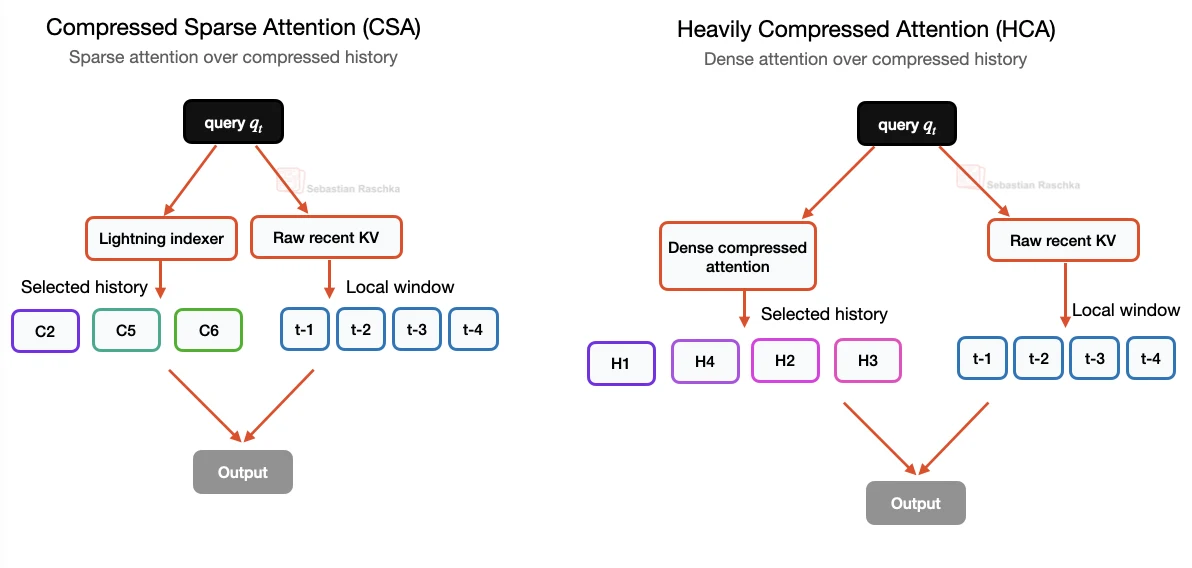
CSA and HCA make different tradeoffs. CSA keeps more compressed context detail, then uses sparse selection to choose which compressed entries to attend to. HCA keeps far fewer entries and can afford dense attention over those entries.
DeepSeek V4 alternates these mechanisms instead of relying on one compression pattern throughout the stack. The CSA layers provide a less aggressive path through compressed history. The HCA layers provide cheaper global coverage over a much shorter cache.
Both paths also retain a local sliding-window branch for recent uncompressed tokens. This keeps detailed access to the newest context while the older context is compressed.
How Its Used in DeepSeek V4
DeepSeek V4 combines CSA/HCA with MLA-style compact entries and shared-KV attention. The public gallery summarizes this as MLA-style CSA/HCA because the model still uses compact compressed entries, while the new part is the sequence-length compression.
This attention-side change is separate from mHC. CSA/HCA changes how the model stores and attends over long histories. mHC changes how the residual path carries information around the attention and MoE sublayers.
Tradeoff
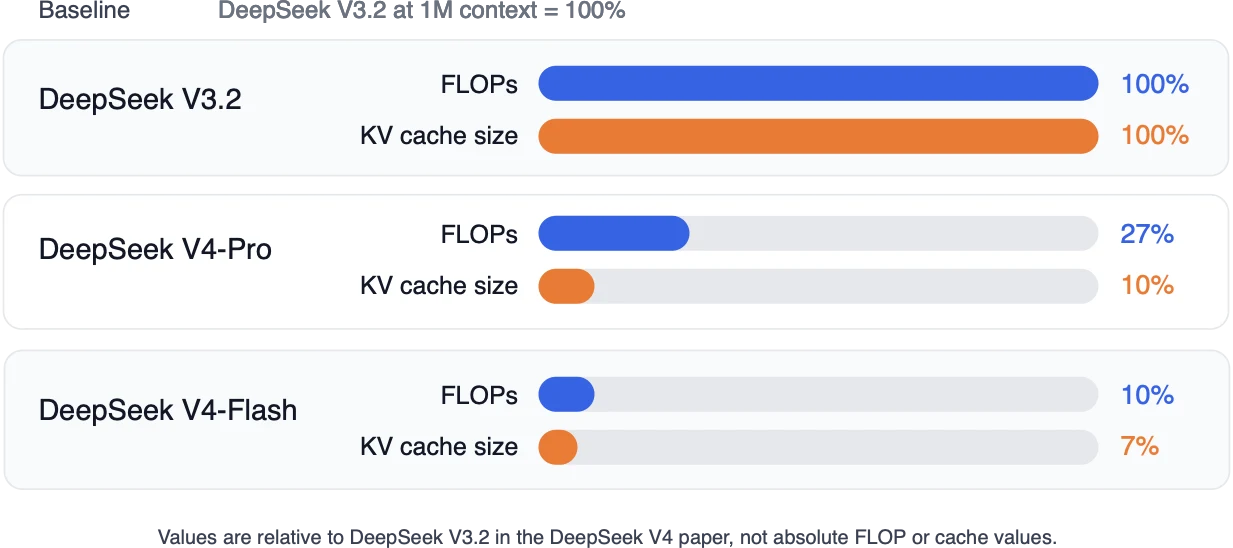
CSA/HCA reduces long-context cost by giving up some token-level detail in older history. This is a stronger compression tradeoff than MLA-style per-token latent caching because the cache becomes shorter in addition to narrower.
The DeepSeek V4 paper reports strong overall results, but those results come from the full DeepSeek V4 recipe, including data, optimization, mHC, precision choices, and system-level implementation. I would treat CSA/HCA as a long-context efficiency design rather than a general replacement for MLA.
Sources