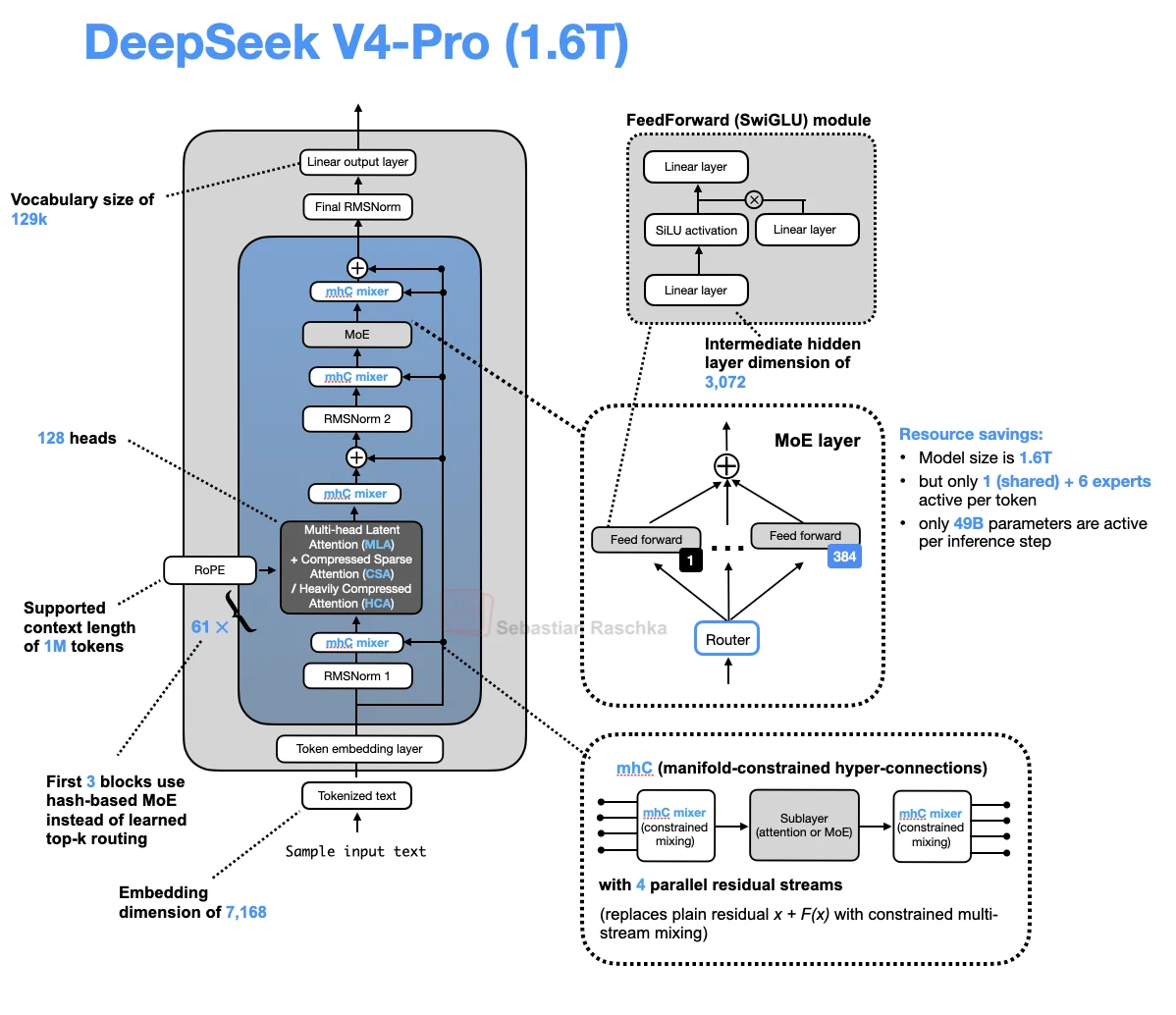
Manifold-Constrained Hyper-Connections
Manifold-constrained hyper-connections (mHC) are a residual-path change used in DeepSeek V4. A regular transformer block carries one residual stream through attention and feed-forward updates. mHC keeps several parallel residual streams and uses constrained mixing layers to move information between them.
In DeepSeek V4, the mHC mixers sit around the attention and MoE sublayers. The attention and MoE layers still operate at the normal hidden size. The wider part is the residual state that carries information between these sublayers.
What changes
The single residual stream becomes several interacting residual streams
Practical benefit
The residual path gets more capacity without widening the attention or MoE sublayers
Example architectures
From Residual Connections To Hyper-Connections
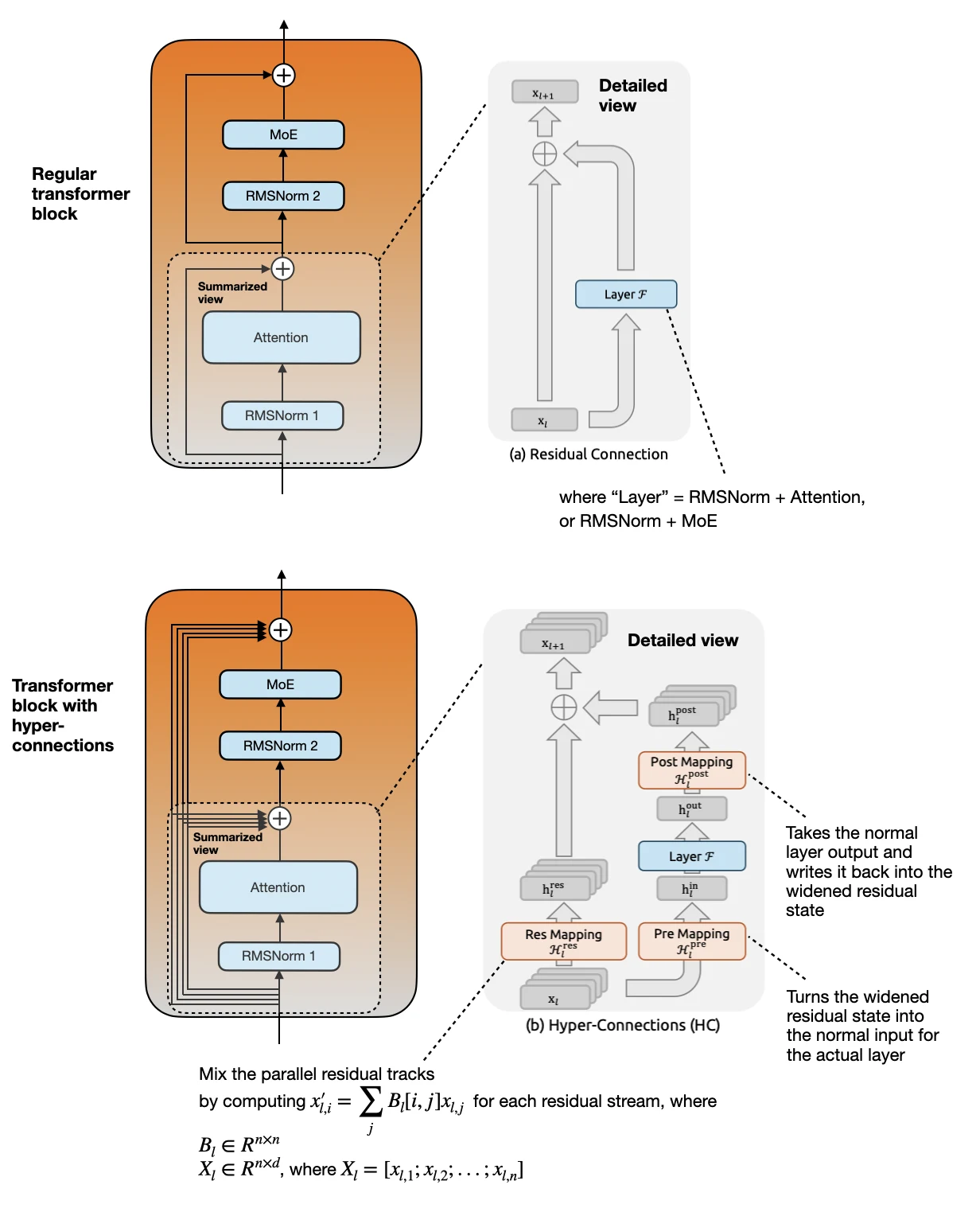
A standard residual block adds a layer output back to the same stream:
X_next = X + F(X)
A schematic widened version looks like this, where X contains n parallel residual streams:
X = [x_1, x_2, ..., x_n]
X_mixed = ResMap(X)
h_in = PreMap(X_mixed)
h_out = F(h_in)
X_next = X_mixed + PostMap(h_out)
Hyper-connections widen this residual path. Instead of one stream, the block carries multiple residual streams. Before an attention or MoE sublayer runs, a Pre Mapping combines those streams into one normal hidden vector. After the sublayer runs, a Post Mapping writes the result back into the widened residual state. A Res Mapping also mixes information between the parallel residual streams across layers.
The useful detail is that the actual attention or MoE sublayer does not need to become wider. The extra capacity is in the state around the sublayer.
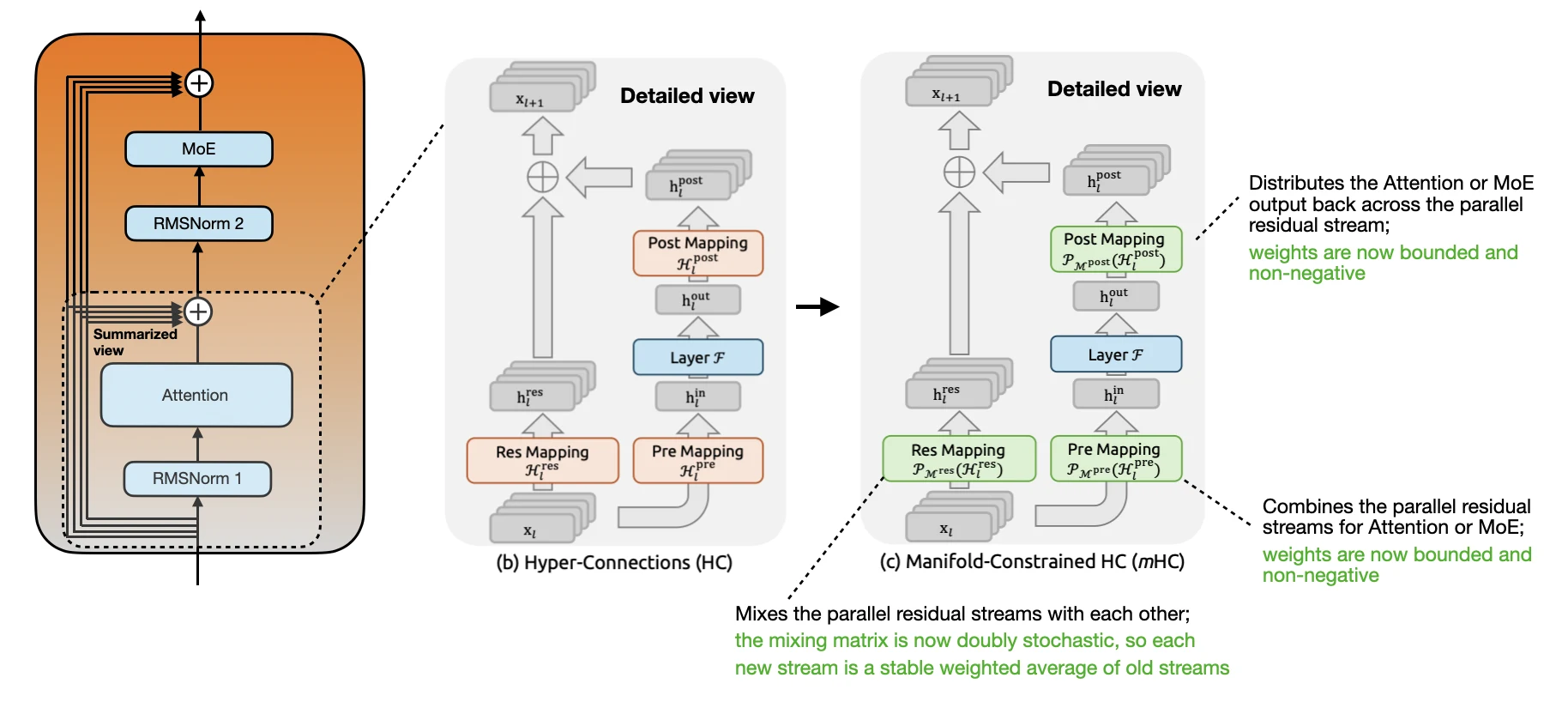
What The Manifold Constraint Adds
Regular hyper-connections use learned mappings between residual streams. Stacking many such mappings can amplify, shrink, or cancel signals in hard-to-control ways.
mHC constrains the mappings. The residual mixing matrix is projected onto the manifold of doubly stochastic matrices, meaning entries are non-negative and each row and column sums to 1. That makes the residual mixing behave more like a stable redistribution across streams.
The Pre Mapping and Post Mapping are constrained as well. Their weights are non-negative and bounded, which limits cancellation when reading from and writing back into the widened residual state.
How Its Used in DeepSeek V4
DeepSeek V4 has two major architecture changes in this part of the gallery. The attention path uses CSA/HCA compressed attention for long contexts. The residual path uses mHC to carry information through the block with 4 parallel residual streams.
This means that mHC is not an attention mechanism. It changes how information is routed around attention and MoE sublayers. In the architecture drawing, the mHC mixers appear before and after the attention and MoE updates.
The mHC paper reports that an optimized implementation with 4 residual streams adds 6.7% training-time overhead in a 27B model experiment. That number is not a full DeepSeek V4 ablation, but it gives a useful sense of the intended cost scale.
Tradeoff
mHC adds state and implementation complexity. The model has to store and move several residual streams, and the mappings around each sublayer require specialized kernels to keep overhead low.
The benefit is that the residual pathway becomes more expressive without directly widening the expensive attention and MoE computations. In DeepSeek V4, that makes mHC a residual-stream counterpart to the model’s attention-side compression changes.
Sources