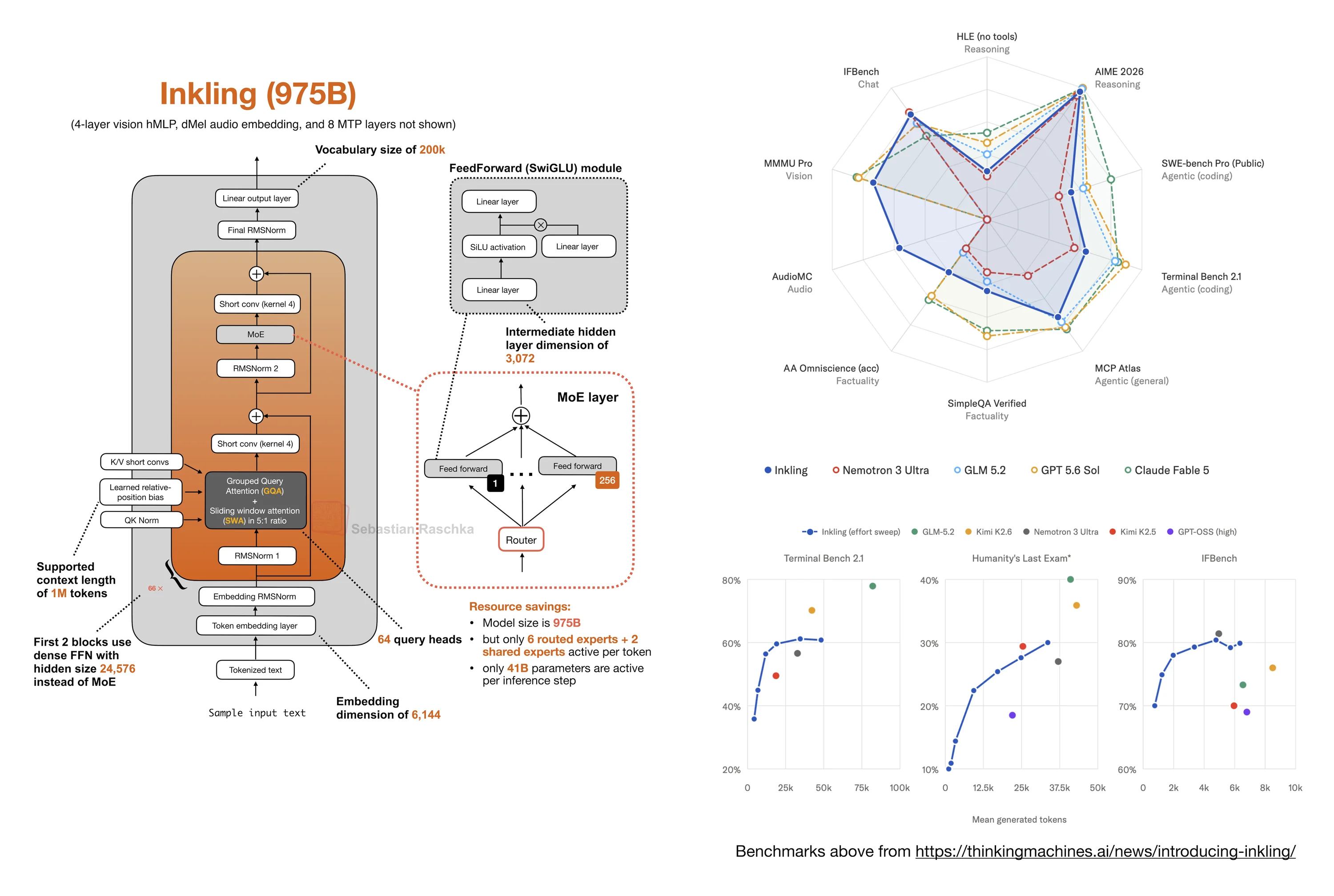
GLM-5.2 and IndexShare for Long-Context Sparse Attention
GLM-5.2 is a recent open-weight model release from Z.ai. My first impression is that it is the best open-weight model today. As usual for fresh releases, I would treat the release-time leaderboard position as date-sensitive.
Architecture-wise, it builds on the earlier GLM-5 and GLM-5.1 architecture. In particular, it reuses Multi-head Latent Attention and DeepSeek Sparse Attention, the DSA mechanism from DeepSeek V3.2 that I covered in the DeepSeek V3 to V3.2 article.
What’s new is IndexShare. This is a cross-layer reuse trick for DSA. Instead of recomputing the sparse-attention top-k indexer in every layer, GLM-5.2 runs the full indexer only once every four layers. The following layers then reuse the selected token indices.
This keeps the same DSA idea but makes 1M-token inference cheaper. The attention pattern is still adaptive, but the model spends less work repeatedly deciding which earlier tokens to attend to.
The local GLM-5.2 architecture card has the current summary, config links, and benchmark references.
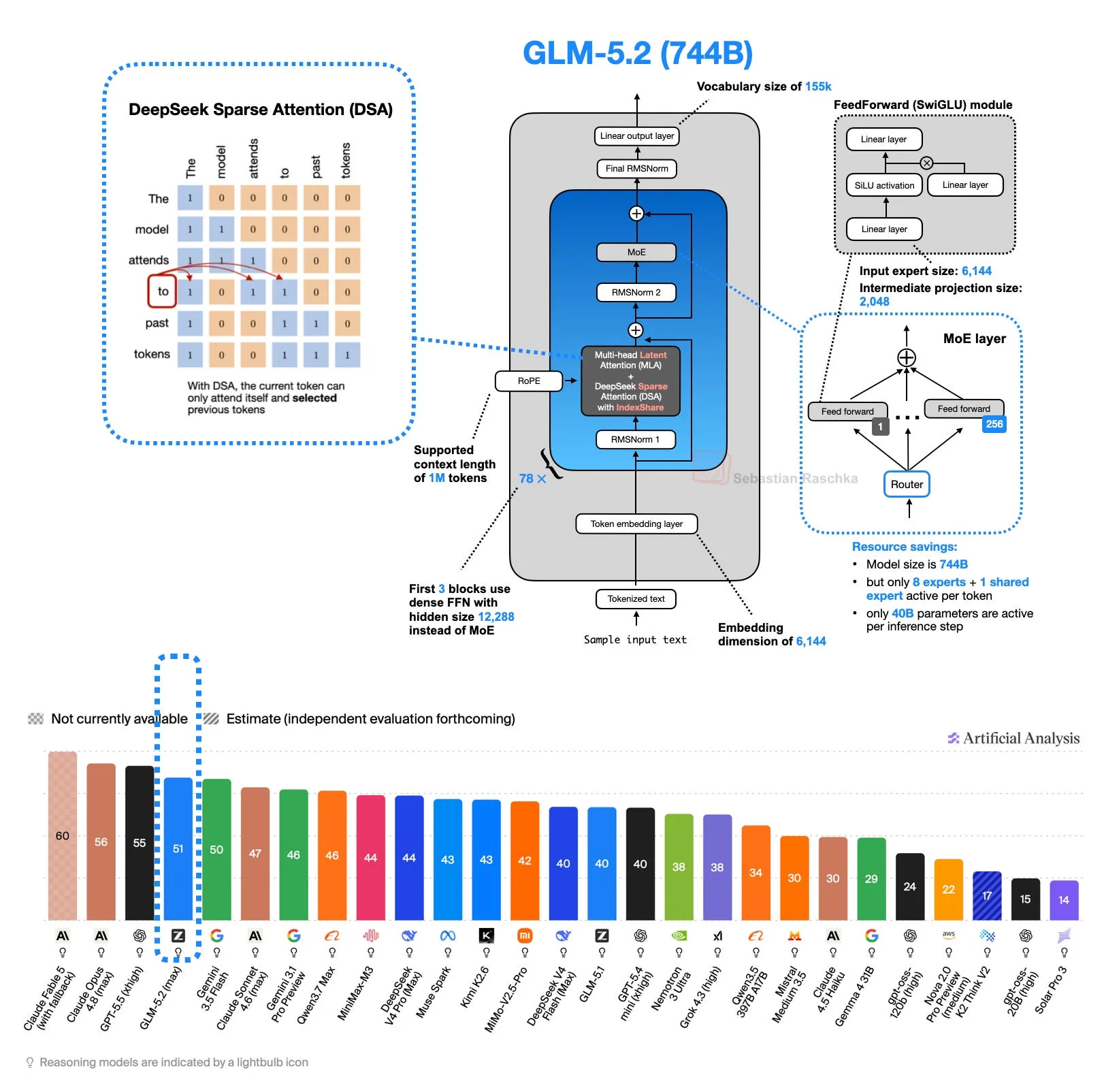
By the way, in the Artificial Analysis Coding Index snapshot below, GLM-5.2 scores 68.8 versus 56.7 for Claude Opus 4.8 (max), more than 10 points higher on coding benchmarks. That’s super impressive for a fresh open-weight model.
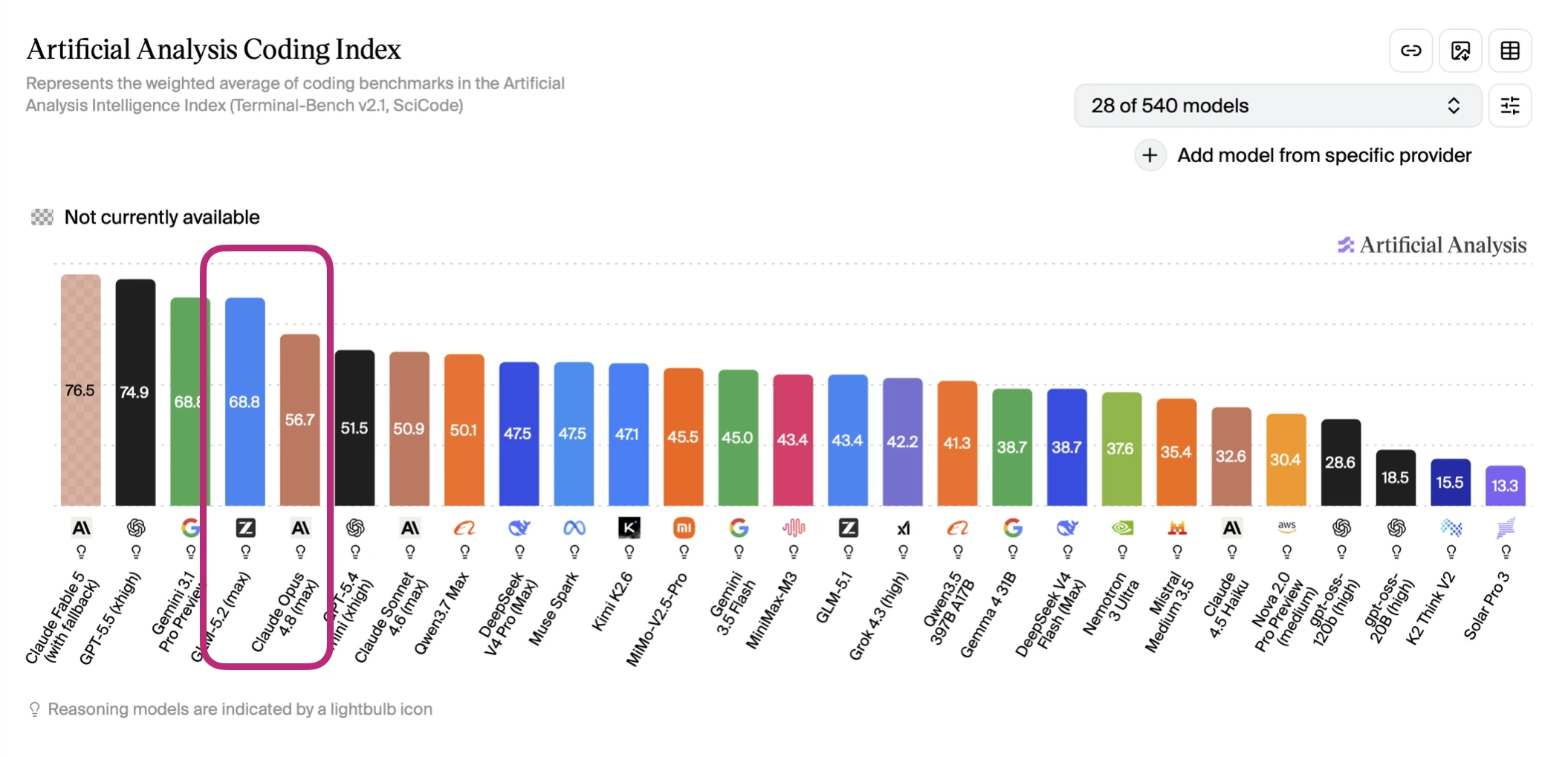
Source: lightly edited website version of my Substack note.