DeepSeek Sparse Attention From Scratch
I added a DeepSeek Sparse Attention from-scratch implementation to the LLMs-from-scratch repository, thanks to an excellent reader contribution.
The folder includes a README, a standalone GPT-style reference implementation, and tests:
The main idea behind DeepSeek Sparse Attention is to replace a fixed sparse pattern with a learned sparse pattern. Instead of using only a local window, the mechanism uses a lightweight indexer and selector to decide which prior tokens are worth attending to.
For more background, I also have a local DeepSeek Sparse Attention concept page and a gallery explainer that compare it with regular causal attention and sliding-window attention.

Source: lightly edited website version of my Substack note.
Read Next
 DeepSeek Sparse Attention Explainer
Review the visual comparison with causal and sliding-window attention.
DeepSeek Sparse Attention Explainer
Review the visual comparison with causal and sliding-window attention.
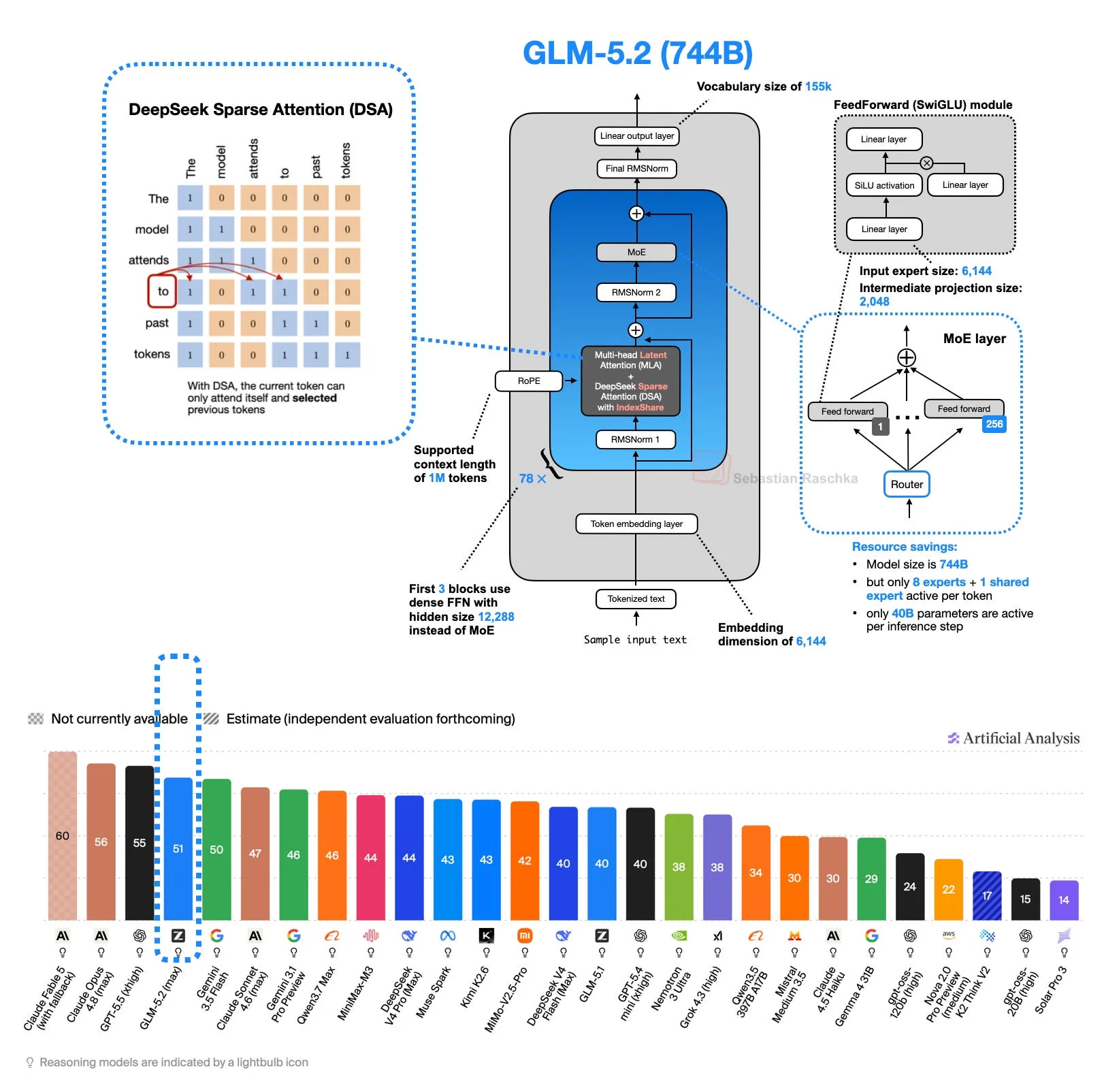 GLM-5.2 and IndexShare for Long-Context Sparse Attention
See how IndexShare reuses sparse-attention indexer work across layers.
GLM-5.2 and IndexShare for Long-Context Sparse Attention
See how IndexShare reuses sparse-attention indexer work across layers.
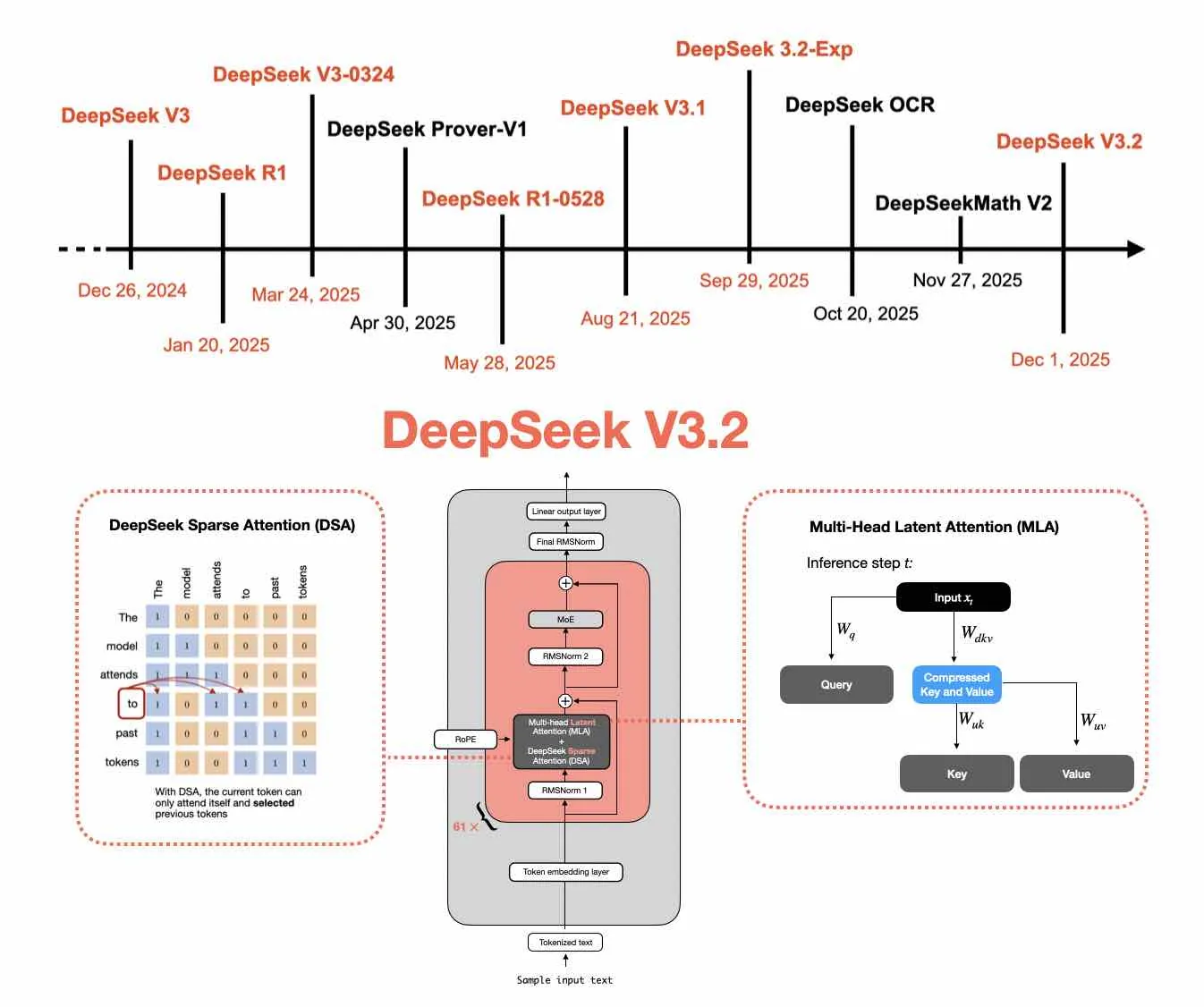 From DeepSeek V3 to V3.2
Read the longer article on DeepSeek architecture and sparse attention.
From DeepSeek V3 to V3.2
Read the longer article on DeepSeek architecture and sparse attention.