DeepSeek Sparse Attention
DeepSeek Sparse Attention is a learned sparse mask that tries to keep the efficiency benefits of local attention without hard-coding a fixed window.
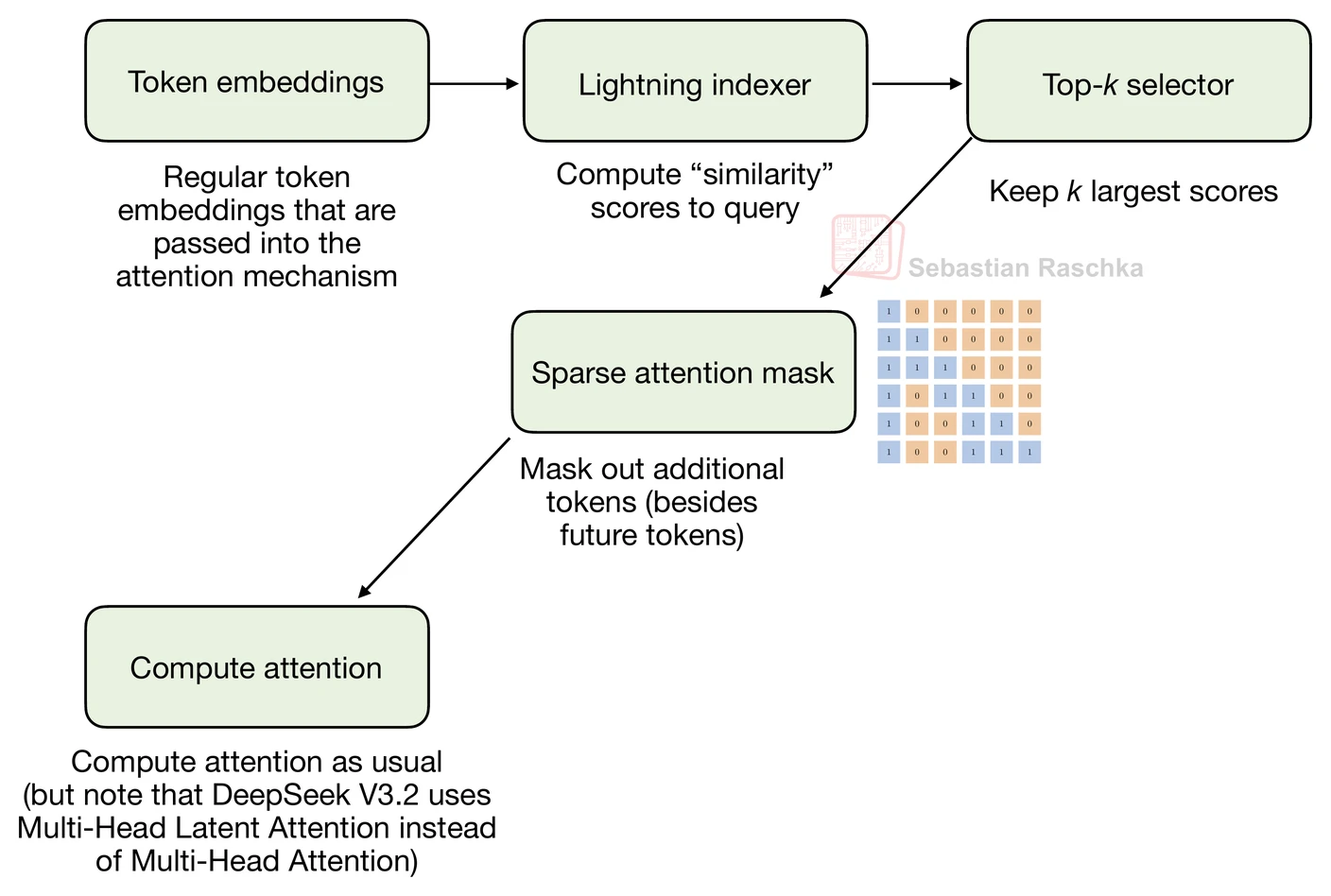
Instead of deciding in advance that every token can only look back a fixed number of positions, DeepSeek Sparse Attention uses a lightweight indexer and token selector to pick which earlier tokens are worth attending to. That makes it more flexible than sliding-window attention, but also more specialized and more implementation-heavy.
Why It Exists
The core problem is familiar: full attention gets expensive at long sequence lengths. Sliding-window attention fixes that by enforcing a local receptive field, but it is rigid because the same geometric rule applies everywhere. DeepSeek Sparse Attention takes a more adaptive route and tries to learn which previous tokens matter for each new query token.
That makes it a more ambitious form of sparse attention. It is not “attend locally”; it is “attend selectively.”
How The Indexer And Selector Work
In the DeepSeek V3.2 write-up, the mechanism is described as two parts: a lightning indexer and a token selector. The indexer scores previous tokens, and the selector then keeps only the top-scoring subset to build the sparse mask. In other words, the sparsity pattern is learned rather than hand-designed.
This is also why the mechanism is tightly coupled to the rest of the DeepSeek serving stack. It is not a generic sparse mask bolted onto any decoder without extra engineering.
How It Differs From SWA
Sliding-window attention chooses a fixed recent window. DeepSeek Sparse Attention chooses a variable set of previous tokens that can come from anywhere in the past sequence if they score highly enough. That makes it more flexible than SWA, but also less transparent and more involved to implement.
The easiest shorthand is: SWA is geometric sparsity, DeepSeek Sparse Attention is learned sparsity.
How To Read It In The Gallery
On the gallery page, this concept appears explicitly in the cards for DeepSeek V3.2 and GLM-5. If a fact sheet says MLA with DeepSeek Sparse Attention, that means the model is compressing KV cache state with MLA and then further reducing long-context attention cost through the learned sparse mask.