Cross-Layer KV Sharing
Cross-layer KV sharing reduces the size of the KV cache by letting several transformer layers reuse key and value tensors from earlier layers. Each layer still computes its own queries, so it can form its own attention pattern. The memory saving comes from the fact that fewer layers append their own K/V tensors to the cache during decoding.
This is related to grouped-query attention, but it works along a different axis. GQA shares K/V heads within a layer. Cross-layer KV sharing shares K/V tensors across layers.
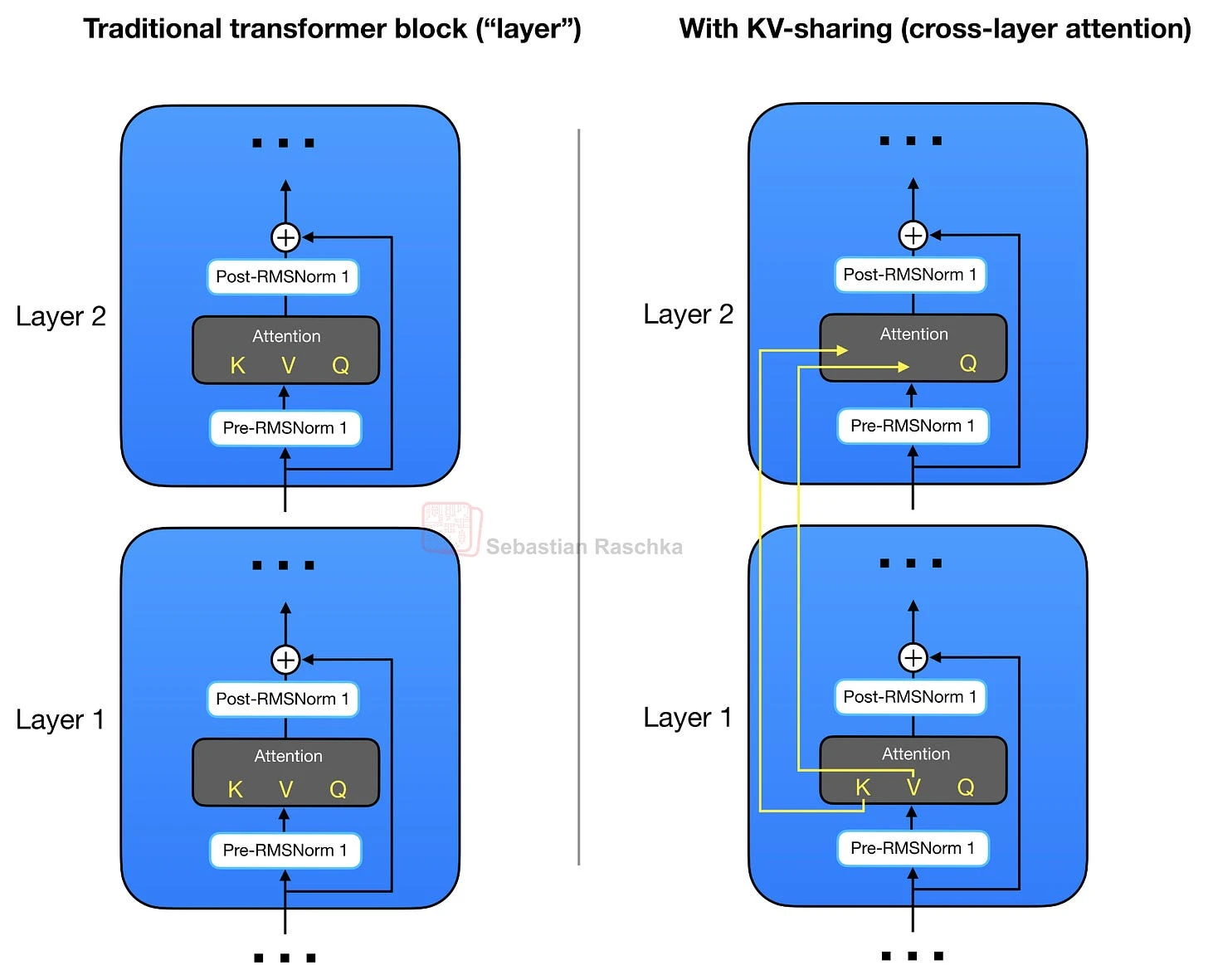
What changes
Only selected layers produce new key and value tensors for the cache
Practical benefit
It compounds with MQA or GQA because it reduces the number of cache-producing layers
Example architectures
How It Reduces Cache Growth
In regular attention with a KV cache, each attention layer stores one key tensor and one value tensor for every generated token. If a model has many layers and a long context window, this cache becomes a major memory cost.
Cross-layer KV sharing changes the layer count in that calculation. Instead of caching K/V tensors for every layer, only the K/V-producing layers add entries to the cache. Later layers reuse the most recent shared K/V tensors while computing their own queries.
For a standard KV cache:
bytes = batch_size x seqlen x head_dim x n_kv_heads x n_layers x 2 x bytes_per_elem
With cross-layer KV sharing:
bytes = batch_size x seqlen x head_dim x n_kv_heads x n_kv_producing_layers x 2 x bytes_per_elem
The rest of the transformer layer is still present. The main change is how many layers contribute growing K/V state during autoregressive decoding.
Gemma 4 E2B And E4B
The Gemma 4 edge models combine several cache-saving choices. E2B uses one KV head, which is effectively MQA. E4B uses two KV heads, which is GQA. Both also use cross-layer KV sharing, so the number of cache-producing layers is smaller than the total layer count.
In the simplified bf16 estimates from the from-scratch materials:
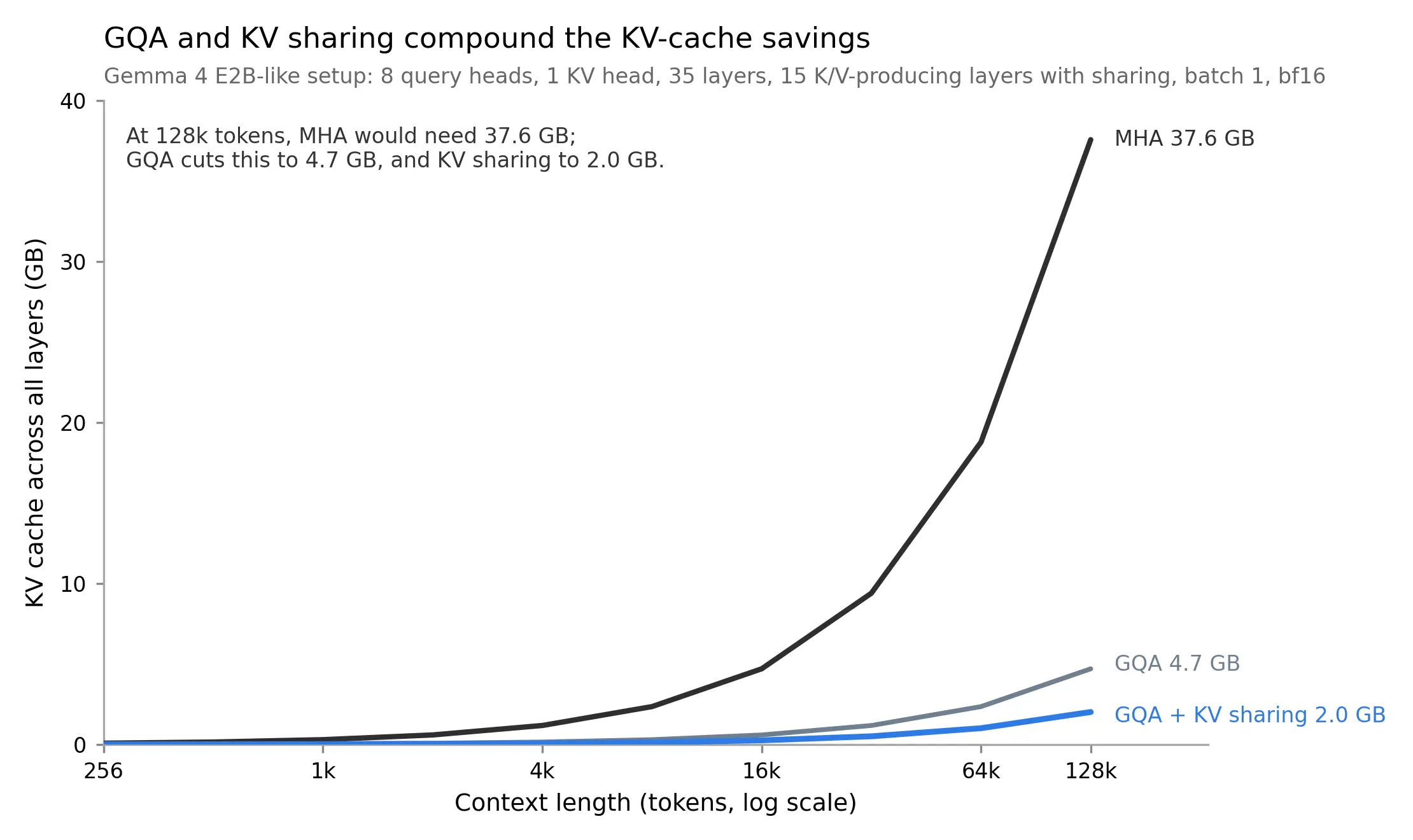
- Gemma 4 E2B-like setup has 35 layers, but only 15 K/V-producing layers.
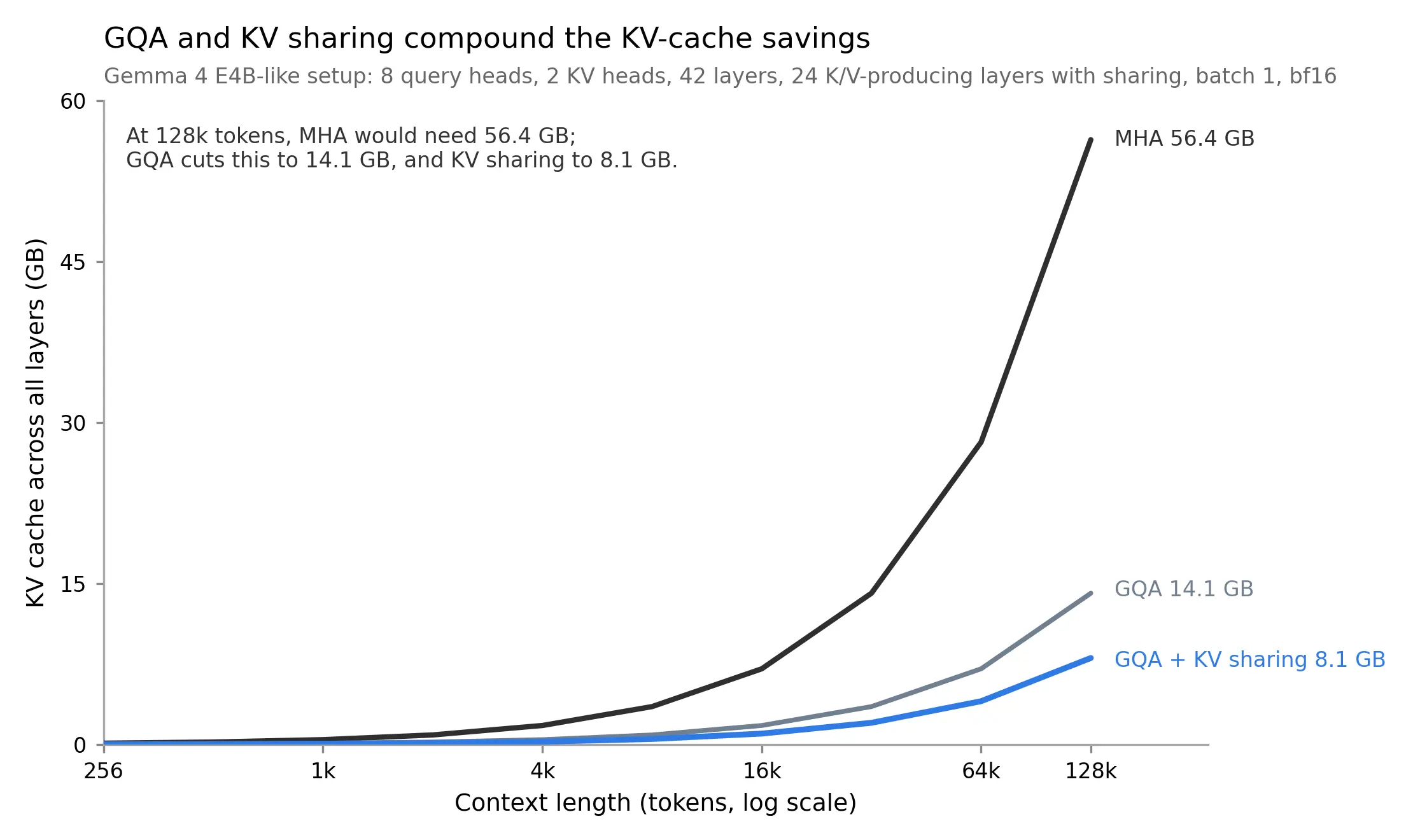
- Gemma 4 E4B-like setup has 42 layers, but only 24 K/V-producing layers.
At a 128k context and batch size 1, the E2B-like setup goes from 37.58 GB for an MHA baseline to 2.01 GB for MQA plus KV sharing. The E4B-like setup goes from 56.37 GB for an MHA baseline to 8.05 GB for GQA plus KV sharing.
These plots isolate MQA/GQA and cross-layer KV sharing. They do not include the additional retained-cache savings from sliding-window attention, which Gemma 4 also uses.
Tradeoff
KV sharing saves memory because fewer layers have independent key and value projections. That is also the tradeoff. Some layers now attend through reused K/V tensors rather than layer-specific ones, which reduces modeling capacity compared with giving every layer its own K/V projections.
This is why it is best understood as one knob in a larger efficiency design. Gemma 4 combines it with MQA or GQA, sliding-window attention, and other attention changes. Each mechanism removes cost from a different part of the inference path.
Sources