LLM Architecture Gallery Diff Tool
I added several updates to the LLM Architecture Gallery over the last two weeks.
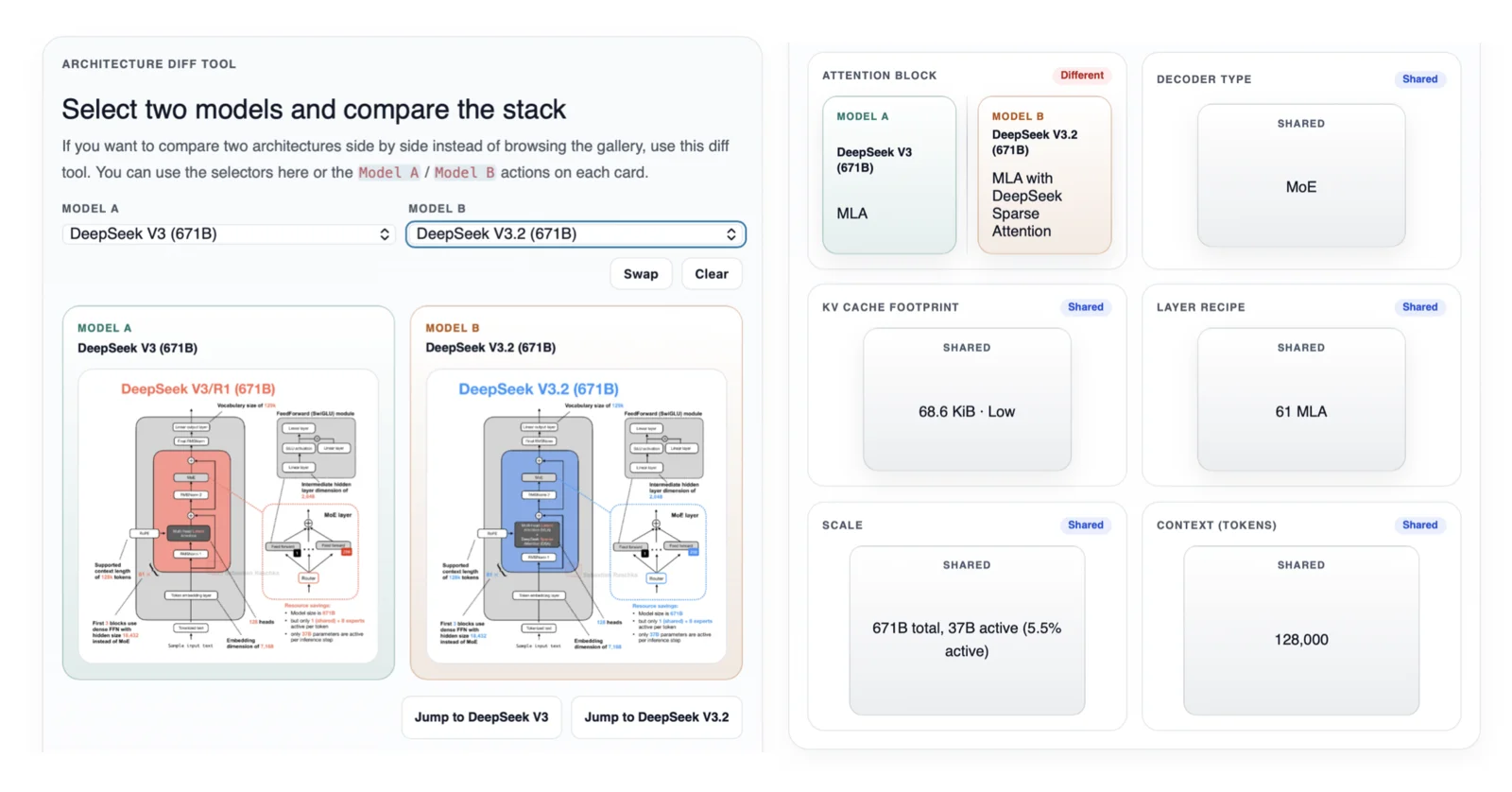
The most useful one is the new architecture diff tool. It lets you select two models and compare their architecture stacks side by side.
The comparison view currently highlights:
- architecture figures
- attention block differences
- decoder type
- KV-cache footprint per token
- layer recipe
- model scale and context length
You can use the selectors in the diff tool directly, or click the Model A and Model B actions on individual gallery cards before jumping to the comparison view.
This is mainly meant for cases where two models look similar at a high level, but differ in one or two important details. DeepSeek V3 versus DeepSeek V3.2 is a good example because the stack is largely shared, but the attention block changes from MLA to MLA with DeepSeek Sparse Attention.
Source: lightly edited website version of my Substack note.


