Open Source Highlights 2022 for Machine Learning & AI
Recently, I shared the top 10 papers that I read in 2022. As a follow-up, I am compiling a list of my favorite 10 open-source releases that I discovered, used, or contributed to in 2022.
(Note that the numbering of the sections does not imply any ranking or preference. Some libraries are connected in a certain way, and I sorted the sections by recommended reading order.)
1) PyTorch 2.0 with Graph Compilation Announced
Let me start with a deep learning that I use every single day: PyTorch!
The PyTorch team has announced PyTorch 2.0 last month at the PyTorch Conference 2022. And the great news is that the core API will not be changing and the focus will be on making PyTorch more efficient.
Additionally, the PyTorch team is moving some code from C++ into Python to make it more developer-friendly. Overall, these updates aim to make PyTorch even more user-friendly.
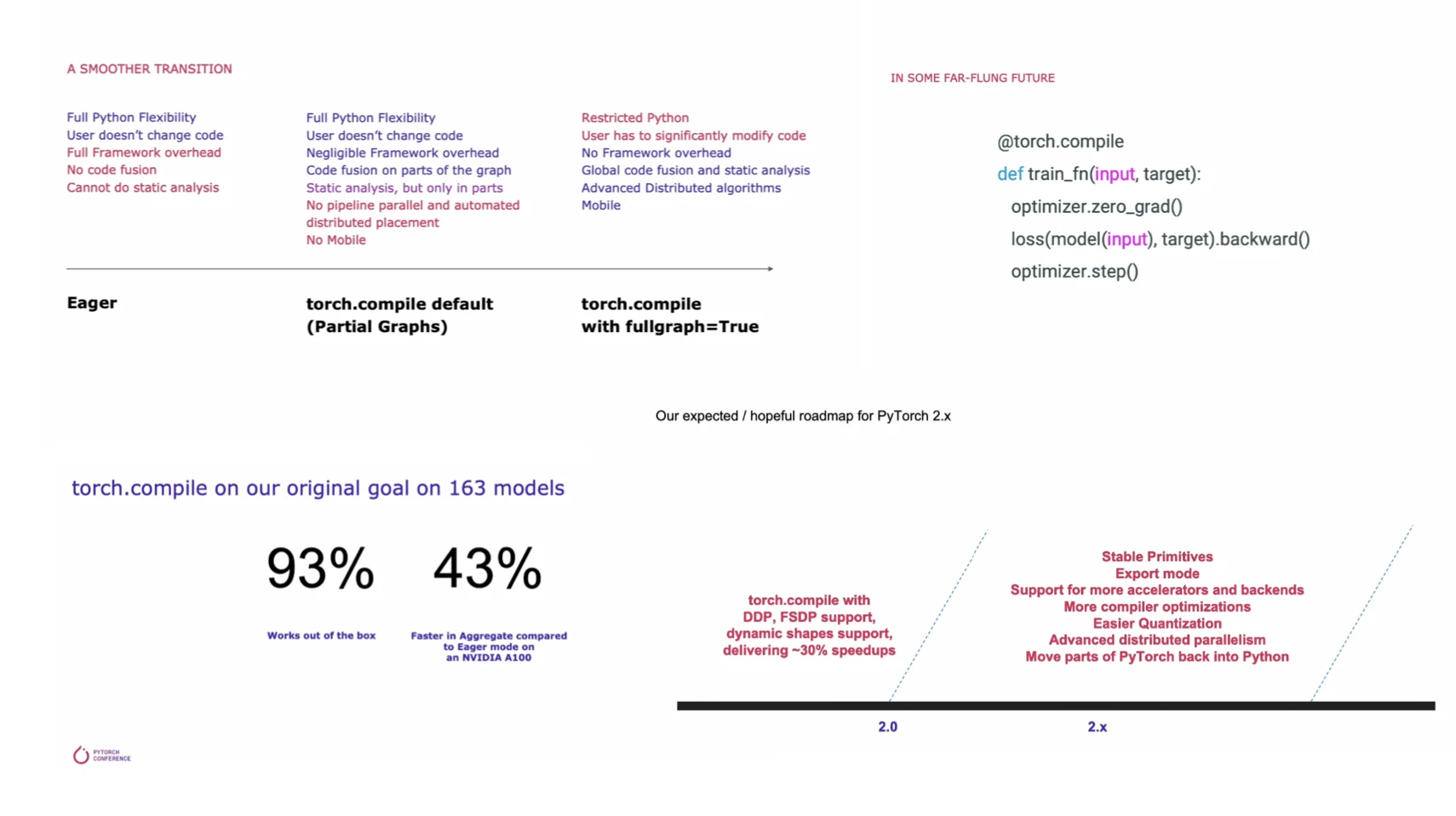
PyTorch 2.0 focuses on changes under the hood. And it includes the optional new torch.compile function for graph compilation to improve model efficiency. In the future, it will be possible to use torch.compile to wrap the entire training loop. Of course, users can continue using PyTorch in eager mode.
torch.compile is already available via the PyTorch nightly releases and will be part of the upcoming PyTorch release. Want to give it a try? It requires only one line of code:
compiled_model= torch.compile(model)
The stable release of PyTorch 2.0 is planned for March 2023. In the meantime, you can find a more detailed write-up by the PyTorch team here.
2) Lovely Tensors – Tensors Ready for Human Consumption
Lovely tensors is a library that aims to help with debugging code for neural networks in PyTorch.
As networks become larger and more complex, it can be challenging to keep track of all the tensors and variables in your code. The lovely tensors library offers a set of tools and features to make debugging easier and more efficient. I just recently discovered this library, and while I have not used it extensively in my own work, yet, it looks super fun and useful.

3) Multi-GPU Training Support in Jupyter Notebooks
As someone who regularly uses Jupyter notebooks for prototyping and teaching, I am always looking for ways to improve my workflow.
One limitation of Jupyter notebooks is that they don’t support many modern multi-GPU paradigms for deep learning due to multiprocessing restrictions. That’s why I was excited about the recent release of PyTorch Lightning 1.7, which introduced multi-GPU support for PyTorch in Jupyter notebooks.

This is a really convenient feature for anyone who uses PyTorch and Jupyter notebooks together. You can learn more about this new feature here.
4) Scikit-learn 1.2: Refining a Foundational Machine Learning Library
The latest version of scikit-learn, one of my favorite machine learning libraries, was released in December. Some of the standout updates for me include enhancements to the HistGradientBoostingClassifier, which is an implementation of LightGBM. Some of the new features supported by the HistGradientBoostingClassifier include:
- interaction constraints (in trees, features that appear along a particular path are considered as “interacting”);
- class weights;
- feature names for categorical features.
Another highlight is the new .set_output() method that we can configure to return DataFrame objects:
For example
scalar = StandardScaler().set_output(transform="pandas")
scalar.fit(X_df)
# X_trans_df is a pandas DataFrame
X_trans_df = scalar.transform(X_df)
or
log_reg = make_pipeline(
SimpleImputer(), StandardScaler(), LogisticRegression())
log_reg.set_output(transform="pandas")
This will help us eliminate many workarounds in the future where we need to pass around column names.
You can find a full list of changes in the release notes.
5) Embetter: Embeddings for Scikit-Learn
Recently, there has been a trend towards using pre-trained large language models and vision transformers in machine learning. In the past, I have discussed the various ways we can train and use transformers. One particularly convenient approach is to use pretrained models to generate embeddings and then feed these embeddings into other models downstream.
I recently stumbled upon embetter, a little scikit-learn compatible library centered around embeddings for computer vision and text. Using embetter, you can build a classifier pipeline that trains a logistic regression model on sentence embeddings of a transformer in 4 lines of code:
text_emb_pipeline = make_pipeline(
ColumnGrabber("text"),
SentenceEncoder('all-MiniLM-L6-v2')
LogisticRegression()
)
It probably won’t break any predictive performance records, but it’s a nice, quick performance baseline when working with text and image datasets.
6) Train, Deploy, and Ship AI Products Lightning Fast
As some of you may know, I joined a startup (Grid.ai) earlier this year. In summer, Grid.ai became Lightning AI, and we launched the open-source Lighting AI framework.
Our platform allows users to build AI products, train and fine-tune models, and deploy them on the cloud without having to worry about infrastructure, cost management, scaling, and other technical challenges.
I will share two hands-on AI product examples below, but if you prefer a bottom-up approach, I wrote two blog articles to explain how the lightning library works:
- Sharing Deep Learning Research Models with Lightning Part 1: Building A Super Resolution App
- Sharing Deep Learning Research Models with Lightning Part 2: Leveraging the Cloud
7) Muse: Diffusion Models in Production
Our team at Lightning AI launched the Muse app, which showcases how you can use the Lightning AI framework (mentioned above) to put a large model like Stable Diffusion into production. The open source code for this project is available on GitHub here.
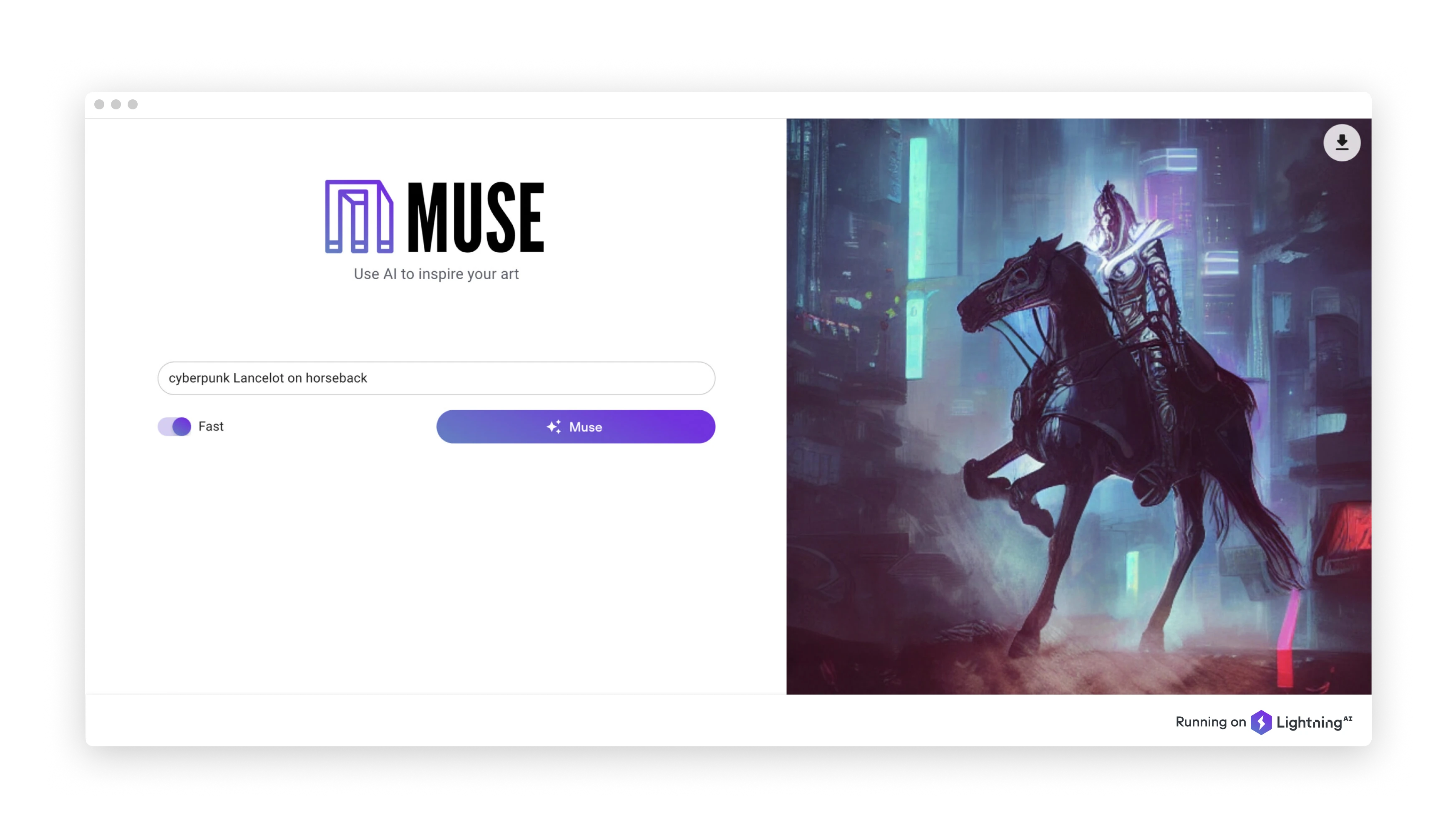
The app comes with a step-by-step article (Diffusion Models in Production) on lessons learned and things to consider if you want to make your model scale to thousands of users, from autoscaling to dynamic batching.
8) Generating High-Quality Subtitles with Whisper
OpenAI recently announced and released Whisper, an open-source language model to generate subtitles (closed captions) for audio files and summarizations. I took Whisper for a test run, and it worked amazingly well. Compared to YouTube’s default method for generating subtitles and the several paid services I tried over the years, Whisper generates subtitles with far greater accuracy. I am particularly impressed by how well it can handle both my accent and technical deep learning jargon.
Hoping that this is useful to you as well, here is the script I used to generate new subtitles for all my deep learning lecture videos on YouTube.
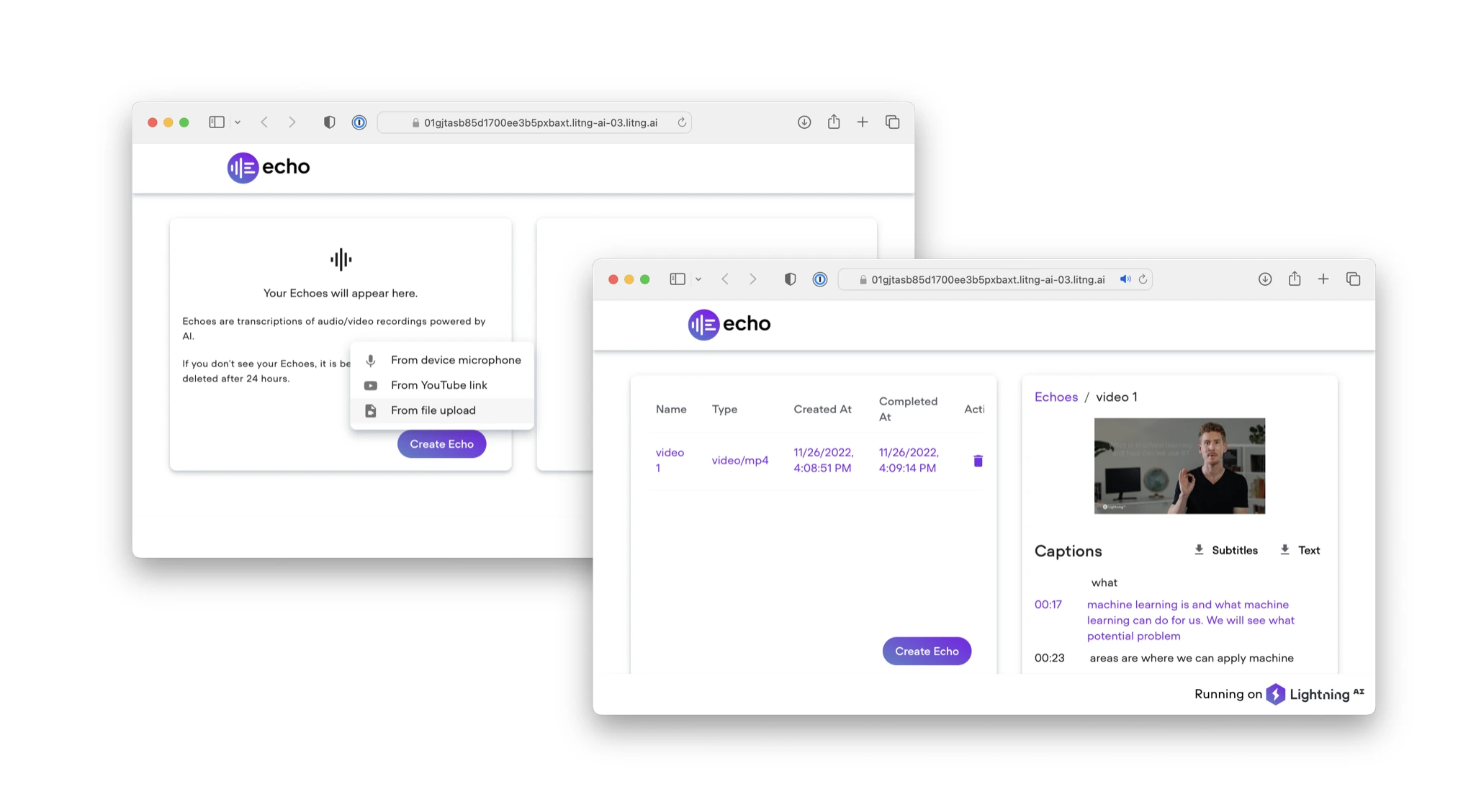
Shameless plug: we recently launched the Echo app, which provides a user-friendly interface around Whisper that lets you drag & drop videos directly from your computer.
Similar to the Muse app, which uses the Stable Diffusion model, Echo demonstrates the ability to bring large models into production and scale them to support multiple users using the Lightning AI framework.
Of course, Echo is fully open-source. Check out the Deploy OpenAI Whisper as a Cloud Product tutorial to learn how this was built.
9) The MLxtend Feature Group Update
I am still (occasionally) maintaining the machine learning-utility library MLxtend that I started as graduate student back in 2012.
Among some other additions this year, MLxtend v0.21 now supports the ability to group related features (such as those created from one-hot encoding) as a single unit during selection. This update allows users to more easily handle and analyze multiple related features together.
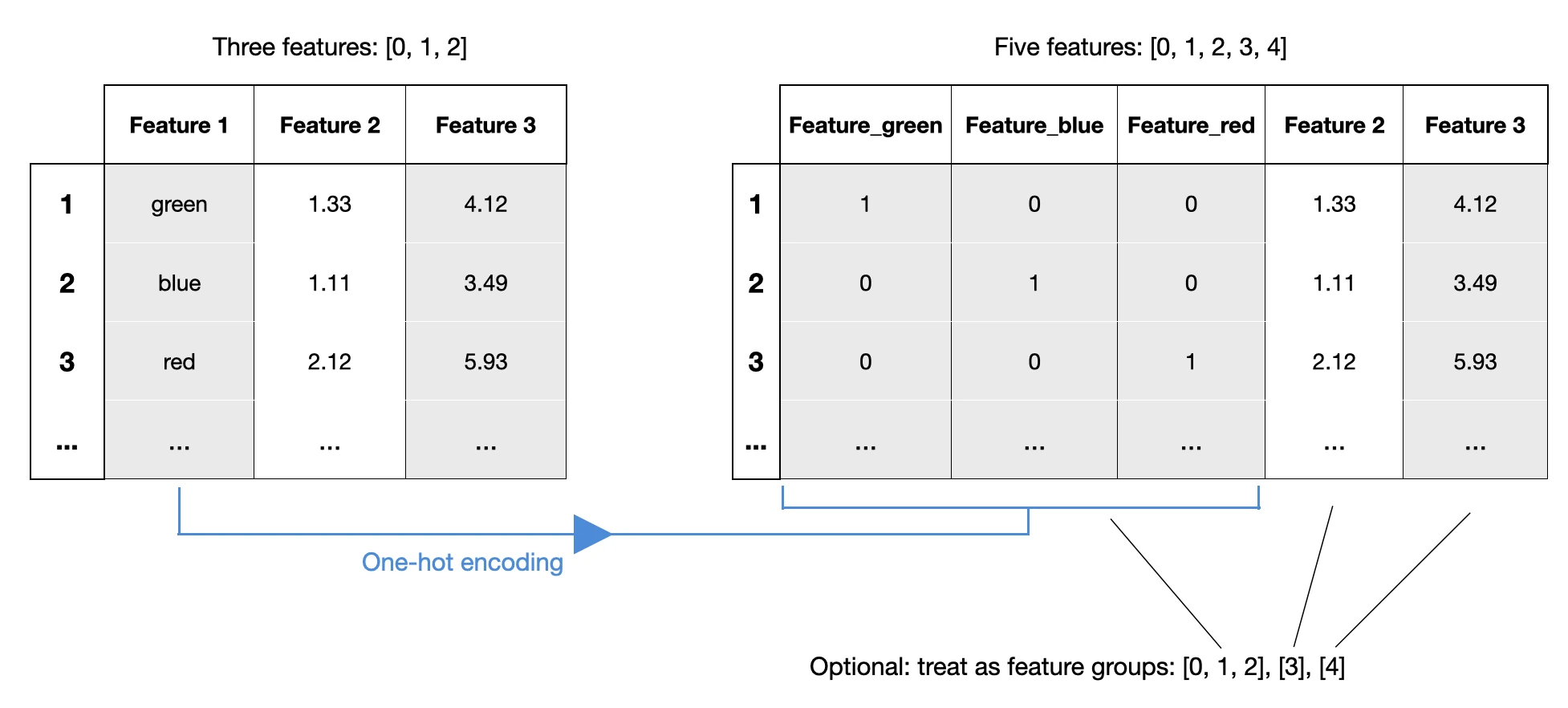
10) AlphaFold Protein Structures in (Bio)Pandas
Another small library I am still maintaining is BioPandas.
BioPandas is a library that allows computational biologists to work with protein structure files in the familiar pandas DataFrame format. For example, The Protein Data Bank (PDB) format is widely used but could be more convenient. BioPandas aims to make working with these files in modern programming languages easier by allowing users to manipulate them using the powerful and user-friendly pandas library.
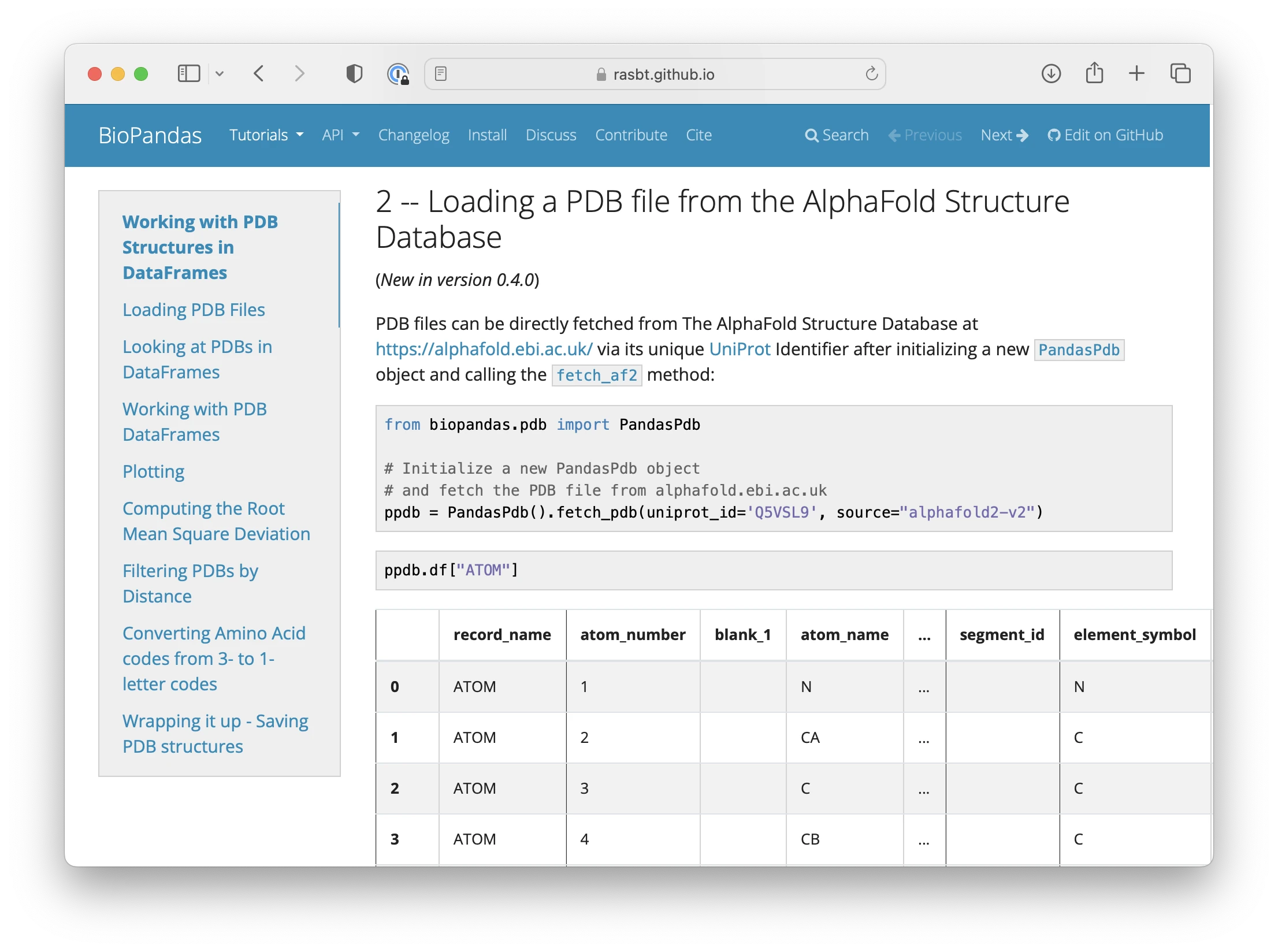
Both the PandasPdb and PandasmmCIF classes let you fetch AlphaFold 2 structures now. For example:
protein = PandasPdb().fetch_pdb(uniprot_id='Q5VSL9', source="alphafold2-v2")
protein = PandasMmcif().fetch_mmcif(uniprot_id='Q5VSL9', source='alphafold2-v2')
Conclusion
Open source is more attractive and active than ever. For instance, in the past year, more than three-quarters of organizations have increased their use of open-source software.
Above, you have seen a small list of open source projects that came to mind, which is by no means comprehensive. (And if you can’t get enough, I recommend the yearly Top Python libraries you should know about list by my friends at Tryolabs.)
Read Next
 Optimizing LLMs From a Dataset Perspective
Practical guide to improving LLM finetuning with better instruction datasets, covering data curation, prompt-output pairs, synthetic data, and experiment i
Optimizing LLMs From a Dataset Perspective
Practical guide to improving LLM finetuning with better instruction datasets, covering data curation, prompt-output pairs, synthetic data, and experiment i
 The NeurIPS 2023 LLM Efficiency Challenge Starter Guide
Large language models (LLMs) offer one of the most interesting opportunities for developing more efficient training methods. A few weeks ago, the NeurIPS..
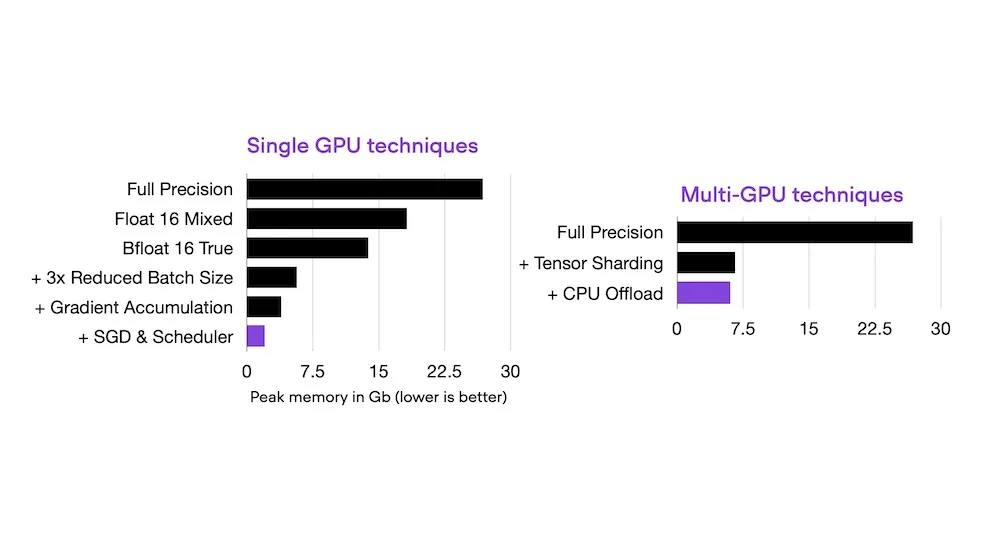
Optimizing Memory Usage for Training LLMs and Vision Transformers in PyTorch
Peak memory consumption is a common bottleneck when training deep learning models such as vision transformers and LLMs. This article provides a series of..
The NeurIPS 2023 LLM Efficiency Challenge Starter Guide
Large language models (LLMs) offer one of the most interesting opportunities for developing more efficient training methods. A few weeks ago, the NeurIPS..
Optimizing Memory Usage for Training LLMs and Vision Transformers in PyTorch
Peak memory consumption is a common bottleneck when training deep learning models such as vision transformers and LLMs. This article provides a series of..

If you read the book and have a few minutes to spare, I'd really appreciate a brief review. It helps us authors a lot!
Your support means a great deal! Thank you!