Writing 'Python Machine Learning'
– A Reflection on a Journey
It’s been about time. I am happy to announce that “Python Machine Learning” was finally released today! Sure, I could just send an email around to all the people who were interested in this book. On the other hand, I could put down those 140 characters on Twitter (minus what it takes to insert a hyperlink) and be done with it. Even so, writing “Python Machine Learning” really was quite a journey for a few months, and I would like to sit down in my favorite coffeehouse once more to say a few words about this experience.

ISBN-10: 1783555130
ISBN-13: 978-1783555130
Paperback: 454 pages, ebook
Packt Publishing Ltd. (September 24th, 2015)
Over time, several people asked me what this book was all about and how I found the time to … (1) write it, (2) read all these interesting articles that I post on twitter, (3) do research, (4) relax and enjoy my life, … Technically, I could summarize point no. 1 in one sentence: I believe that all tech books a written more or less in leisure time. I figured that I could “just” cut down on hobby coding projects and blogging for a few months to make this work.
Write what you know. That should leave you with a lot of free time.
— Howard Nemerov
You don’t agree? Maybe my little bag of productivity tricks can convince you—if you are interested, more on that later. First, let me tell you a bit more about the book.
“Python Machine Learning?” - What Is This All About?
It all started with my good intentions of compiling a useful reference for the aspiring machine learning practitioner. Okay, “Python Machine Learning” turned out to be quite a tome, but writing wasn’t the actual issue here. Quite the contrary, if you are passionate about a topic, you could go on and on and on. The real challenge was to draw the line!
Now, “what’s so exciting about machine learning and Python so that you decided to devote almost all of your free-time to it?” If all my posts on our favorite social networking sites haven’t convinced you yet, I guess I am left with no alternative but to say it with someone else’s words:
We live in the midst of a data deluge. According to recent estimates, 2.5 quintillion (1018) bytes of data are generated on a daily basis. This is so much data that over 90 percent of the information that we store nowadays was generated in the past decade alone. Unfortunately, most of this information cannot be used by humans. Either the data is beyond the means of standard analytical methods, or it is simply too vast for our limited minds to even comprehend.
Through Machine Learning, we enable computers to process, learn from, and draw actionable insights out of the otherwise impenetrable walls of big data. From the massive supercomputers that support Google’s search engines to the smartphones that we carry in our pockets, we rely on Machine Learning to power most of the world around us—often, without even knowing it.
As modern pioneers in the brave new world of big data, it then behooves us to learn more about Machine Learning. What is Machine Learning and how does it work? How can I use Machine Learning to take a glimpse into the unknown, power my business, or just find out what the Internet at large thinks about my favorite movie? All of this and more will be covered in the following chapters authored by my good friend and colleague, Sebastian Raschka. […]
— Dr. Randal S. Olson (excerpt from the Foreword)
 (Source: https://xkcd.com/1570/)
(Source: https://xkcd.com/1570/)
Granted, machine learning is quite hot these days for various reasons, but “why Python?” My short answer is that it is an intuitive and productive environment that is “capable” on so many levels. Talking “productive”, I think was just about to start straying from the current debate for a second, and I hope you don’t mind if delegate this discussion to my previous post, Python, Machine Learning, and Language Wars. A Highly Subjective Point of View.
Technology is nothing. What’s important is that you have a faith in people, that they’re basically good and smart, and if you give them tools, they’ll do wonderful things with them.
— Steve Jobs
Where We Are Going With This Book
“Is this book any different from other books about Python and machine learning?”—there are quite a few out there by now. I believe so! When the publisher asked me for the first time, I politely declined the offer since there were already a couple of books out there that cover these topics. Well, after I declined, I reconsidered after I got the chance to read through some of those. I don’t want to say that other books are better or worse, however, what I’ve seen was a little bit different from what I’d have in mind for a machine learning book with practical Python examples.
[…] So, with machine learning computers program themselves, it’s a bit like the scientific method except that it being done by a computer, and it’s on steroids because it’s much faster and can deal with a lot more data.
— Pedro Domingos (excerpt from an interview with Pedro Domingos on his new book: A Master Algorithm in Machine Learning Could Change Everything)
There are great books out there that focus on the machine learning theory. Some of my favorite books among them are C. Bishop’s Pattern Recognition and Machine Learning and Pattern Classification by Duda, Hart, and Stork. These books are great, really great. I think there is no need to write something similar. However, although they are considered as “intro” books, they can be pretty hard on beginners in this field. Although I would really recommend them to everyone who is serious about machine learning, I would rather tend to recommend it as part of the “further reading” section rather than a first machine learning book. Anyway, I think that implementing and tinkering with machine learning algorithms along with reading the theory is probably the way to get the best bang for your buck (=time) in this field.
Then, there are books that very practical and read like a * documentation (* insert scikit-learn, Vowpal Wabbit, caret or any other ML library/API here). I think that these are good books too, but I also think that detailed discussions about libraries should be left to the (online) library documentation itself where it can be kept up to date and serve as a reliable, interactive reference.
There are three rules for writing a novel. Unfortunately, no one knows what they are.
— W. Somerset Maugham
My goals for a book were the three essentials building blocks: (1) explaining the big picture concepts (2) augmenting these with the necessary math intuition, and (3) providing examples and applications. The big picture helps us to connect all the different pieces, and the math is required to understand what is going on under the hood and helps us to outmaneuver the common pitfalls. The practical examples definitely help benefit the learning experience. Lastly, it’s really important that we get our hands “dirty,” that is, writing code that puts the learned material into action. We want to understand the concepts, but eventually, we also want to use them for real-world problem solving.
 (Source: https://xkcd.com/1045/)
(Source: https://xkcd.com/1045/)
Throughout this book, we will make use of various libraries such as scikit-learn and Theano among others, which are efficient and well-tested tools that we would want to use in our “real-world” applications. However, we will also implement several algorithms from scratch. This helps us to understand these algorithms, to learn how the libraries work, and to practice implementing our own algorithms—some of them are not part of scikit-learn, yet.
What This Book Is About and What It Is Not
This book is not a “data science” book. It is not about formulating hypotheses, collecting data, and drawing conclusions from the analysis of novel and exotic data sets; the focus is on the machine learning. However, besides talking about different learning algorithms, I think that it is very important to discuss the other aspects of a typical machine learning and model building pipeline starting with the preprocessing of a data set. We will cover topics such as dealing with missing values, transforming categorical variables into machine-learning suitable formats, selecting informative features, and compressing data onto lower dimensional subspaces. There is a full chapter on model evaluation discussing hold-out cross-validation, k-fold cross-validation, nested cross-validation, hyperparameter tuning, and different performance metrics. As a little refresher, I also added a chapter about embedding machine learning models into a web application to share it with the world.
 (Source: https://xkcd.com/1343/)
(Source: https://xkcd.com/1343/)
This is not yet just another “this is how scikit-learn works” book. I aim to explain how Machine Learning works, tell you everything you need to know in terms of best practices and caveats, and then we will learn how to put those concepts into action using NumPy, scikit-learn, Theano, and so on. Sure, this book will also contain a decent amount of “math & equations,” and in my opinion, there is no way around it if we want to get away from the “black box thinking.” However, I hope I managed to make it really easy to follow so that it can be read by a person who doesn’t have a strong math background. Many parts of this book will provide examples in scikit-learn, in my opinion, the most beautiful and practical machine learning library.
Here’s a quick chapter overview:
- 01 - Machine Learning - Giving Computers the Ability to Learn from Data
- 02 - Training Machine Learning Algorithms for Classification
- 03 - A Tour of Machine Learning Classifiers Using Scikit-Learn
- 04 - Building Good Training Sets – Data Pre-Processing
- 05 - Compressing Data via Dimensionality Reduction
- 06 - Learning Best Practices for Model Evaluation and Hyperparameter Optimization
- 07 - Combining Different Models for Ensemble Learning
- 08 - Applying Machine Learning to Sentiment Analysis
- 09 - Embedding a Machine Learning Model into a Web Application
- 10 - Predicting Continuous Target Variables with Regression Analysis
- 11 - Working with Unlabeled Data – Clustering Analysis
- 12 - Training Artificial Neural Networks for Image Recognition
- 13 - Parallelizing Neural Network Training via Theano
Quicklinks
- GitHub Repository for general info and code examples
- Literature References & Resources for Further Reading
- Links to the ebook and paperback versions at Amazon.com, Amazon.co.uk, Packt, Apple iBooks, and Google Books
- Sample chapter
- Thanks for the nice feedback so far!
Errata
As for the Errata, I was thinking about how to turn something negative like little annoying typos and other errors into something more positive. I am going to reward each error with a small donation to UNICEF USA, the US branch of the United Nations agency for raising funds to provide emergency food and healthcare for children in developing countries. So, if you are interested in reading this book, and if you should find some mishaps in this first edition, please let me know! I will keep the list up to date here.
Paperbacks and E-books
Unfortunately, I can’t say much about the different e-book versions since I haven’t seen them, yet. Personally, I prefer to read technical books in paperback format or PDF over ePub or Amazon Kindle. I know that the digital version at Packt includes PDF, ePub, and Mobi formats, but I am not sure about Amazon though. I haven’t bought a non-fiction e-book at Amazon, yet, but I believe it is Mobi only?
In any case, you can get the code examples (mostly in IPython notebook format) from the publisher’s website no matter whether you got the book from there or not (access to the code examples requires a quick registration though). However, for your convenience, I will also upload the code examples to the GitHub repository shortly!
A Cover That May or May Not Make Sense
What do you think about the cover? I remember that a neuroscientist asked me why there were neurons on the cover. A fair question and ample ammunition for an epic discussion that could rival the best programming language and text editor wars. The publisher seems to be into architecture and nature. When I was presented with the initial collection of about 20 stock images, the best I could find was some glass roof of a city hall somewhere in Poland. It was a really nice picture but as a book cover, hm, but as a book cover? So when we later added about 200 extra pages to the “initial” final draft, the publisher took the liberty to present me with a whole new cover. I didn’t get to choose this time, but hey, I liked it—it’s so much better than the previous cover.
There are books of which the backs and covers are by far the best parts.
— Charles Dickens (Oliver Twist)
Anyway, I think that neurons are quite fitting overall if you think back of the origins of machine learning (which I briefly introduce in the second chapter). It all started when W. S. McCulloch and W. Pitts proposed the McCulloch-Pitt (MCP) Neuron, a first model of how a neuron in a mammal’s brain could work (A logical calculus of the ideas immanent in nervous activity. The bulletin of mathematical biophysics, 5(4):115–133, 1943). This was followed by one of the early ML algorithms, the perceptron (F. Rosenblatt. The perceptron, a perceiving and recognizing automaton. Project Para. Cornell Aeronautical Laboratory, 1957). Soon thereafter, we had our Adaline (adaptive linear neuron) based on gradient descent optimization (B. Widrow. Adaptive ”Adaline” neuron using chemical ”memistors”. Number Technical Report 1553-2. Stanford Electron. Labs., Stanford, CA, October 1960). About the same time, researchers started connected these single learning units to powerful multi-layered network architectures, replacing linear by non-linear cost functions.
This is the brief story how the multi-layer perceptron came to life sometime in the midst of the 20th century.
No matter how much the biological brain and artificial neural networks eventually have in common, we and at least say that the former is kindling spark and namesake of the latter.
And yes, understanding and using concepts from biological information-processing pipelines is still a hot topic in modern research for inventing and improving upon machine learning algorithms!
I am in the camp that believes in developing artificial neural nets that work really well and then making them more brain-like when you understand the computational advantages of adding an additional brain-like property.
— Geoff Hinton (from his Reddit AMA)
So, I Decided to Write a Book
Yes, that it happened back in March 2015, I reconsidered the inital offer by the publisher and eventually decided to write this book. I know, half a year sounds there was plenty of time, but …
A Day Only Has 24 Hours After All
Of course, I had to do the math first: There a always too many things I have and want to do, how does “writing a book” fit into my (24h) day?
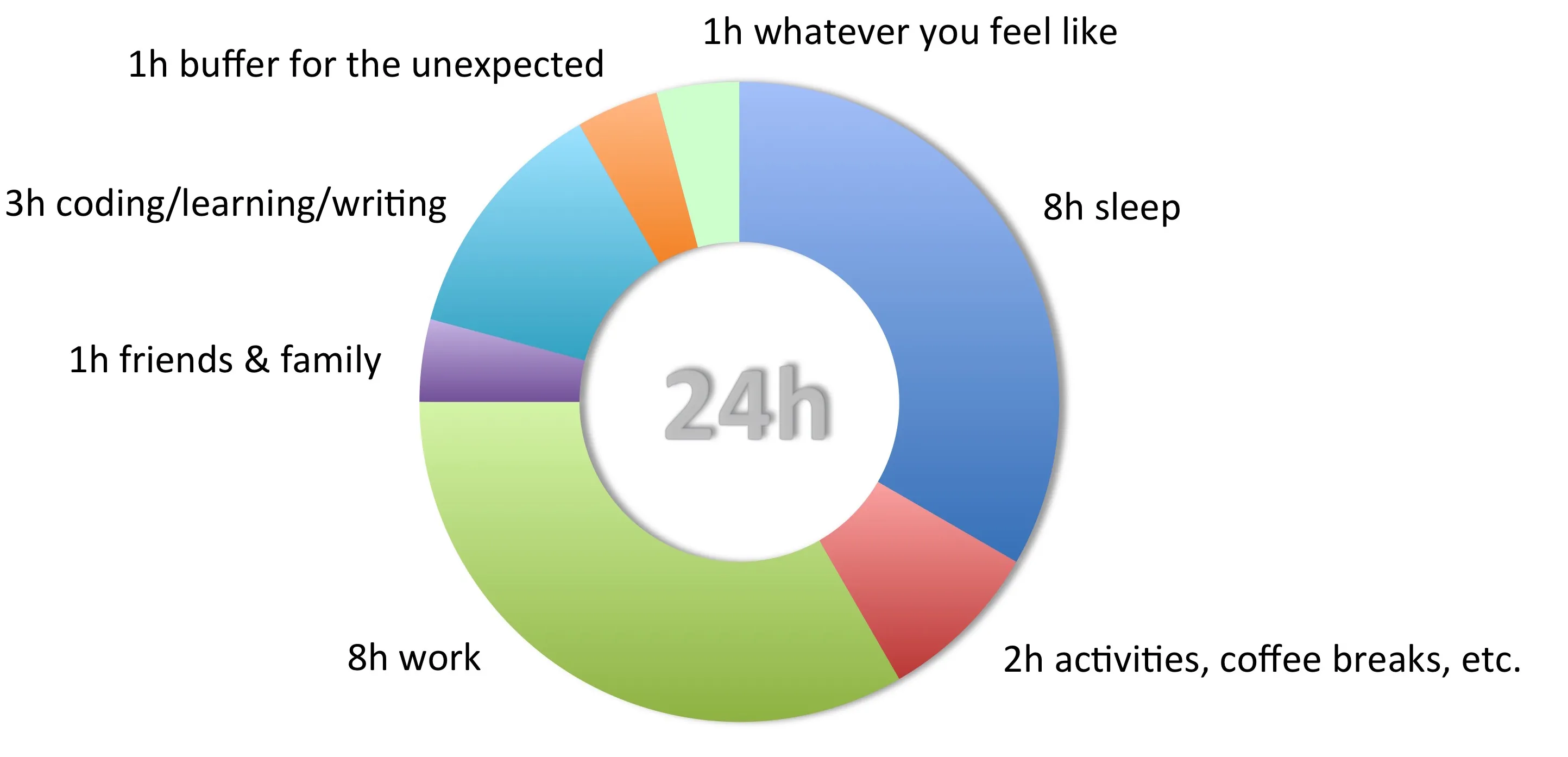
Sure, pie charts are considered “evil” by data visualization experts, but since this is a very rough estimate at best, I found it quite fitting in this context. First and foremost, my day is centered around 8h of work/research. Moreover, I can’t imagine a life without spending time with friends and/or family. Sure, sleeping sounds like the most boring task, but it is (still) quite necessary. And while machine learning is eating the software world, I also need my breakfast, lunch, and dinner time. To stay sane, I really need my daily walk to work or some exercise like soccer, and there is the occasional coffee break to keep the creative juices flowing.
There is only one kind of shock worse than the totally unexpected: the expected for which one has refused to prepare.
— Mary Renault (The Charioteer)
Lastly, how can I call it a day without drifting off in the fictional world of a good book before I go to sleep? Now, that leaves myself with roughly three hours of writing a day, sometimes more, sometimes less. Even if push comes to shove, don’t you dare to think about carving out precious hours from your good night’s sleep—here, I feel guilty on many occasions.
Your time is your life. You are absolutely the final authority on how you will use it.
— Anne Katherine
Even though I had this queasy feeling that I may have missed something in my pie chart—hey come on, it’s a pie chart after all, what do you expect—I was also pretty enthusiastic about getting a chance to write about my favorite topic(s). So, the initial chapter proposal was ready beginning of April. This was just a rough idea of the 10 chapters I wanted to write about, a bunch of headlines accompanied by short summaries. Next, I had roughly two weeks per chapter to put it down on paper. The challenging part was that the book was supposed to be 180 - 230 pages long for the format (an “Essentials” book) that the publisher had in mind.
Writer’s block is a fancy term made up by whiners so they can have an excuse to drink alcohol.
— Steve Martin
Later, it turned out that I had largely underestimated how much (time and) space it takes to write a chapter. Initially, I put down 20 pages per chapter in my outline-proposal, but later it ended up being ~25 pages. And those are 25 pages after aggressive shortening! It sounds somewhat paradoxical, but having to think carefully about the sections and paragraphs I could remove without turning the book into a resource that raises more questions than it answers was the real challenge here! Good news is that after I handed in the last chapter in July, the publisher really liked the book and granted me some extra pages; this resulted in a 454 page book eventually. Of course, I could and wanted to write so much more, but you have to draw the line somewhere, right?!
There is no real ending. It’s just the place where you stop the story.
— Frank Herbert
In any case, to get the initial draft together, I had to reach deep into my box of productivity tricks and habits that I accumulated over the years. They are surely not useful for everyone, maybe they are not useful to anyone, but if you are interested, I can write a little about these later.
Time for Credits
I really want to thank all the people who were involved in this project as reviewers and editors. It was a great experience, and I am happy to have such exceptional assistance at my side!
-
Dr. Vahid Mirjalili. I can truly say that Vahid is one of the best friends and colleagues one can have. Vahid is not only an exceptional reviewer, but his professional career is truly impressive and inspiring! Starting with aerospace engineering, winning the two most recent, worldwide competitions for protein structure prediction and refinement with his group (CASP 2012 and 2014), Vahid is now busy working on the next big thing: Using Big Data and Cloud Computing to help researchers in the bio-sciences on their next breakthrough. And by the way, he was actually the one who convinced me to write this book after I have blown off the first request by the publisher.
-
Dmytro Taranovsky. What a great reviewer! His feedback was really outstanding. I don’t want to imagine how this book would look like without his help!
-
Dr. Randal S. Olson. Randy, a good friend, a great colleague, and also an endless source of inspiration. Randy is not yet another Machine Learning and Artificial Intelligence researcher—if you’ve seen his data visualization blog you probably know what I am talking about. Thanks for the nice Foreword, Randy!
-
One problem with writing technical books about the topics you are really excited about is that you are so into it and forget the outsider’s perspective. Thus, I was happy to have Richard Dutton on board to help me simplify all these sections rich in technical jargon.
-
Actually, all the reviewers were really invaluable during this process. Think of ensemble learning methods, a committee of experts! Thanks Dave Julian and Hamidreza Sattari!
-
A special thanks goes to Jason Wolosonovich. Although Jason was not part of the initial “review crew,” he sent me tons of nice and motivational feedback when he was reading the final draft along with a comprehensive list of typos that slipped through the copy-editing stage.
-
Lastly, I was really impressed with Riddhi Tuljapurkar’s patience; she was the “Content Development Editor” of this book. Well, despite all the deliberate planning, I have to admit that I missed a deadline here and there, and it was just nice to have such a nice and understanding person on the other side. Thanks!
My Productivity Hacks That Are Not for Everyone
I think that’s all I wanted to say, but do you remember the “productivity” hacks I mentioned earlier? I had about three hours a day reserved for writing, and a little more on weekends. That’s actually not that much when it comes to writing a book, and there were a few old habits of mine that may or may not have been helpful during this process. Read on if you are interested.
Growing Ideas on Paper
Well, ideas come at strange times at strange places. Most often it happens on my walk to/from work.
One always has a better book in one’s mind than one can manage to get onto paper.
— Michael Cunningham
Although I have a car and could technically drive to work to save an hour a day for the back and forth, I really enjoy a nice walk during the warmer times of the year; it’s also a great way to “read” some books—I mean listening to audio books of course! Nevertheless, I always have this worn-out notebook in my back pocket—ideas come at strange times at strange places.

Yet, writing down those random thoughts doesn’t make a book. I am not sure if it is a blessing or burden, but my German genes like the process of deliberate planning. Here is just a short three-stage checklist that I (try) to use for all kinds of writing.
1. Outline & Create
- mindmap for ideas
- write the headings
- add sub-headings if appropriate
- write paragraph headings (can be deleted later)
- add keywords to each paragraph
- insert references for further information to limit the scope
- create/insert figures that help explaining complicated concepts
Your intuition knows what to write, so get out of the way.
— Ray Bradbury
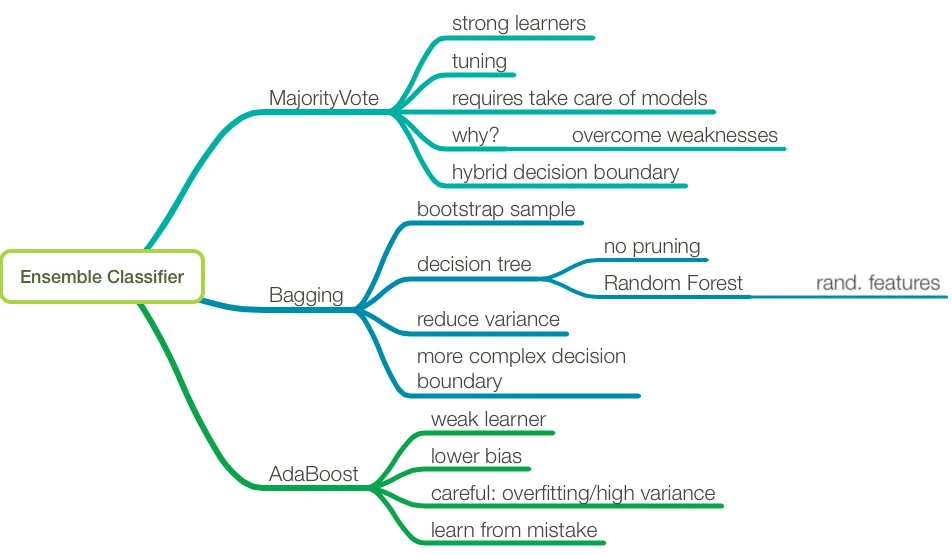
Mind maps are a classic, but it really works! When I start a new topic, I just sit down for a few minutes put all the crazy thinks that come into a mind map format as spontaneously as possible. Writing about topics such as machine learning is an extremely challenging task, because all the concepts are connected and intertwined. Connecting them in a mind map is intuitive and easy, and I would worry about putting them into a linear format (for instance, a written chapter) later.
I typically use software for that since it is a 2-step process for me. The second step includes reordering, cleaning it up, and making additions here and there. Eventually, I end up with a main mind map of topics that I want to cover. Next, I think about the headings and so forth.
An Image is worth more than 1000 words! What may sound like yet another hollow phrase is also something I really believe in. Creating illustrative images of the most complex concepts truly helps both the writer and the reader!
2. Write & Rewrite
- flesh out the paragraphs (quickly); don’t worry about the grammar
- re-read the whole text and change the organization if necessary
- the introduction should address the “why should I care?” question
- provide a roadmap at the beginning before diving into details
- re-read and re-write, and re-read and re-write …
- use some objects in the text (metaphors) to explain tricky concepts
It’s no good to get bogged down in the nitty-gritty details at the early stages of a draft. Fixing grammar and spelling, and worrying about the sentence structure is probably the biggest trap and time sink. Eventually, we may end up removing or changing most of it later anyway. There is no reason to be embarrassed about bad style, metaphorically speaking, write with the “door shut.”
3. Double-Check & Finalize
- remove jargon that is inappropriate for the audience
- make sure all mathematical symbols are defined
- make sure that all important figure elements are described in the text
- if you are using algorithms and models by other people, ensure they are credited
- (remove informalities (don’t -> do not))
- remove redundancies / duplications / repetitions
- prefer active voice over passive
- shorten lengthy sentences
- substitute some adverbs by action verbs
- check for correct comma usage
- check for correct semicolon usage
- check for correct usage of parentheses
- check for correct usages of dashes -
- check for correct usage of em dashes –
- run your grammar & spelling checking tool
- check for consistent spelling, e.g., “dataset” vs. “data set”
- give it a last one complete read before you pass it on to the reviewer
3A. Plot specific
- Use color, shade or size in a scatter plot vs. 3D plots
- use “plain English” instead of variable names like “x[1]” on your plot axes
- make sure that the graphs are readable by color blind people
- add a scatter plot overlay when using box plots or bar plots
- axes in multi-panel plots are all on the same scale
- the coloring is consistent for the same variables in different figures
3B. Data science specific
- describe the purpose of the analysis before you analyze
- cause or lead to shouldn’t be used in correlation analyses
After the initial “outlining” stage, that is, when I think that the overall structure makes sense, it’s about time to apply some polish. Although it may look like overkill, I still like to use a checklist to make sure that I don’t forget anything.
Here is a lesson in creative writing. First rule: Do not use semicolons. They are transvestite hermaphrodites representing absolutely nothing. All they do is show you’ve been to college. — Kurt Vonnegut (A Man Without a Country)
Plaintext-GTD to Keep Me Sane
I may disregard some pearls of wisdom from more elaborate studies about best practices here and there, but this is what works for me. I think that work flows are really person- and task-specific, so I wouldn’t recommend you to take it too seriously, but maybe you will find one or the other useful in this section.
My favorite things in life don’t cost any money. It’s really clear that the most precious resource we all have is time.
— Steve Jobs
The key message is: Keep the future out of your head to make room for the present. In contrast to computer memory, which doubles every couple of years, our brain’s short-term memory is only capable of juggling 4 “things” on average (or 7 depending on whom you ask). Unfortunately, we can’t just simply buy more RAM for our biological motherboard, thus, it is important to reserve the precious storage space for the most important things.
The key lesson I got from David Allen’s GTD approach is to write things down. That’s why always carry a small pen and piece of paper or paper notebook. Sometimes I also just use my smartphone to compose a quick email to myself with the thought in the subject line—especially if the “item” is really important since my email inbox is something that I check at least twice a day. While I am at my computer, I simply keep an __inbox__ directory and an __inbox__.txt file where I can dump the stuff that I want to take a look at later as it happens. It goes without saying that cleaning out those paper, email, and digital inboxes once or twice a day is mandatory if you want to make sure that nothing slips through the cracks. These “inbox things” eventually end up in either one of these locations: My ToDo-list, my notes directory, or the trash.
 (Source: https://xkcd.com/1205/)
(Source: https://xkcd.com/1205/)
When it comes to my ToDo-list, I keep it plain and simple. Just type “GTD todo” into your favorite web search engine and you will find a fast amount of tools that have been developed for these purposes. Well, I tried several of those over the years, but I wasn’t happy with either of them. The price tags for stand alone software and/or monthly subscriptions aside, they never really clicked with me for long. Most of them come with convenient bells and whistles yet all of them have their quirks. Remember, organizing your ToDos is one thing, but actually doing them is what it is all about!
I am really not a big fan of proprietary formats when it comes to my project and task management. I want to be flexible and somewhat independent of the platform developer. Take Evernote for example, I was a heavy user a couple of years ago. Even though it comes with somewhat useful export features, I can tell you that it is quite a hassle to transfer your data from one tool into the other. I constantly have this uneasy feeling that if I use a proprietary tool, I invariably need to be prepared for the worst-case scenario; the time when this tool is not supported anymore will certainly come sooner or later (The First Dead Unicorn is Already Here, You Just Don’t Know It Yet).
And just by the way: Most of the bells and whistle can be a distraction anyways. Remember, organizing your to dos is one thing, but actually doing them is what is important!
The most important aspect of ToDo lists is to check your items off! Yes! Checking tasks off is truly satisfactory, just striking a golf ball with a club on the teeing ground. Ye goode olde paper ToDo list is really great for that purpose. I like paper, but I am also into digital logging and keeping things. I use a simple text expansion tool with a shortcut ( ddate) that gets expanded to the current date (2015-09-24), which use to check off the tasks of my plaintext ToDo list. Yes, I use a simple text file to stay organized. It just works (for me)!
This is accompanied by a simple 150liner written in Python as my task management tool, let’s call it plaintext-gtd.py.
At the end of the day, I simply execute plaintext-gtd.py from my terminal, and all my completed tasks are moved into a todolog.txt file for future reference, and I have a brief summary of my daily productivity printed in the terminal for reflection. If these tasks were part of a bigger project, this gets checked off as well, and I get to see a motivational quote as a reward. Since I keep all of that in Dropbox, it is available across all my computers, and I don’t have to worry about platform-specific workarounds.
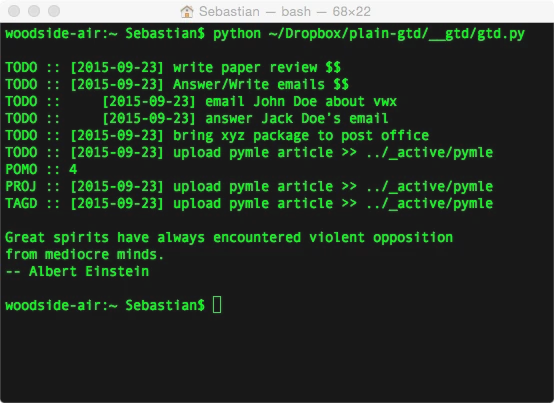
Since my little helper tool is tailored to my personal needs and probably not very intuitive to other people, I recommend checking out taskwarrior, which offers a more mature version of this idea.
Thanks!
This article certainly became longer than I intended it to be. You probably didn’t read all of it, but I hope that you at least skipped forward to this last section! Beause I really want to say “Thank you!” I believe that without the great communities that evolved around machine learning, Python, and machine learning in Python, I would have never found the motivation to write such a book. Python and machine learning are immensily useful in my everyday life and exciting topics for sure. Yet, sharing this passion with other people is a whole different level. The informative resources we share on social media platforms and the interactions with the “machine learning” and “data science” communities … It’s great to be part of it!
A big thanks also goes to scikit-learn, one of the greatest open-source efforts I have ever seen. It is really a pleasure to work with the people who are involved in this project. All these efforts that went into creating, improving, and maintaining this project for us machine learning practitioners merit deep and absolute respect.
Read Next
 Scientific Computing in Python: Introduction to NumPy and Matplotlib
Beginner's guide to NumPy and Matplotlib for scientific computing: arrays, indexing, broadcasting, linear algebra, and plotting with Python code examples.
Scientific Computing in Python: Introduction to NumPy and Matplotlib
Beginner's guide to NumPy and Matplotlib for scientific computing: arrays, indexing, broadcasting, linear algebra, and plotting with Python code examples.
 Model evaluation, model selection, and algorithm selection in machine learning
Part 4 of the model evaluation series explaining statistical tests, algorithm comparisons, corrected resampled tests, and nested cross-validation.
Model evaluation, model selection, and algorithm selection in machine learning
Part 4 of the model evaluation series explaining statistical tests, algorithm comparisons, corrected resampled tests, and nested cross-validation.
 Generating Gender-Neutral Face Images with Semi-Adversarial Neural Networks to Enhance Privacy
I thought that it would be nice to have short and concise summaries of recent projects handy, to share them with a more general audience, including...
Generating Gender-Neutral Face Images with Semi-Adversarial Neural Networks to Enhance Privacy
I thought that it would be nice to have short and concise summaries of recent projects handy, to share them with a more general audience, including...

If you read the book and have a few minutes to spare, I'd really appreciate a brief review. It helps us authors a lot!
Your support means a great deal! Thank you!