Python, Machine Learning, and Language Wars
– A Highly Subjective Point of View
Oh god, another one of those subjective, pointedly opinionated click-bait headlines? Yes! Why did I bother writing this? Well, here is one of the most trivial yet life-changing insights and worldly wisdoms from my former professor that has become my mantra ever since: “If you have to do this task more than 3 times just write a script and automate it.”
By now, you may have already started wondering about this blog. I haven’t written anything for more than half a year! Okay, musings on social network platforms aside, that’s not true: I have written something – about 400 pages to be precise. This has really been quite a journey for me lately. And regarding the frequently asked question “Why did you choose Python for Machine Learning?” I guess it is about time to write my script.
In the following paragraphs, I really don’t mean to tell you why you or anyone else should use Python. To be honest, I really hate those types of questions: “Which * is the best?” (* insert “programming language, text editor, IDE, operating system, computer manufacturer” here). This is really a nonsense question and discussion. Sometimes it can be fun and entertaining though, but I recommend saving this question for our occasional after-work beer or coffee with friends and colleagues.
The short answer to a complex question
Maybe I should start with the short answer. You are welcome to stop reading this article below this paragraph because it really nails it. I am a scientist, I like to get my stuff done. I like to have an environment where I can quickly prototype and jot down my models and ideas. I need to solve very particular problems. I analyze given datasets to draw my conclusions. This is what matters most to me: How can I get the job done most productively? What do I mean by “productively”? Well, I typically run an analysis only once (the testing of different ideas and debugging aside); I don’t need to repeatedly run a particular piece of code 24/7, I am not developing software applications or web apps for end users. When I quantify “productivity,” I literally estimate the sum of (1) the time that it takes to get the idea written down in code, (2) debug it, and (3) execute it. To me, “most productively” means “how long does it take to get the results?” Now, over the years, I figured that Python is for me. Not always, but very often. Like everything else in life, Python is not a “silver bullet,” it’s not the “best” solution to every problem. However, it comes pretty close if you compare programming languages across the spectrum of common and not-so common problem tasks; Python is probably the most versatile and capable all-rounder.

(Source: https://xkcd.com/974/)
Remember: “Premature optimization is the root of all evil” (Donald Knuth). If you are part of the software engineering team that wants to optimize the next game-changing high-frequency trading model from your machine learning and data science division, Python is probably not for you (but maybe it was the language of choice by the data science team, so it may still be useful to learn how to read it). So, my little piece of advice is to evaluate your daily problem tasks and needs when you choose a language. “If all that you have is a hammer, everything starts to look like a nail” – you are too smart to fall for this trap! However, keep in mind that there is a balance. There are occasions where the hammer may be the best choice even if a screwdriver would probably be the “nicer” solution. Again, it comes down to productivity. ⇧
Let me give you an example from personal experience. I needed to develop a bunch of novel algorithms to “screen” 15 million small, chemical compounds with regard to a very problem specific hypothesis. I am an entirely computational person, but I am collaborating with biologists who do non-computational experiments (we call them “wet lab” experiments). The goal was to narrow it down to a list of 100 potential compounds that they could test in their lab. The caveat was that they needed the results quickly, because they only had limited time to conduct the experiments. Trust me, time was really “limited:” We just got our grant application accepted and research funded a few weeks before the results had to be collected (our collaborators were doing experiments on larvae of a certain fish species that only spawns in Spring). Therefore, I started thinking “How could I get those results to them as quickly as possible?” Well, I know C++ and FORTRAN, and if I implement those algorithms in the respective languages executing the “screening” run may be faster compared to a Python implementation. This was more of an educated guess, I don’t really know if it would have been substantially faster. But there was one thing I knew for sure: If I started developing the code in Python, I could be able to get it to run in a few days – maybe it would take a week to get the respective C++ versions coded up. I would worry about a more efficient implementation later. At that moment, it was just important to get those results to my collaborators – “Premature optimization is the root of all evil.” On a side node: The same train of thought applies to data storage solutions. Here, I just went with SQLite. CSV didn’t make quite sense since I had to annotate and retrieve certain molecules repeatedly. I surely didn’t want to scan or rewrite a CSV from start to end every time I wanted to look up a molecule or manipulate its entry – issues in dealing with memory capacities aside. Maybe MySQL would have been even better but for the reasons mentioned above, I wanted to get the job done quickly, and setting up an additional SQL server … there was no time for that, SQLite was just fine to get the job done.

(Source: https://xkcd.com/1319/)
The verdict: Choose the language that satisfies your needs! However, there is once little caveat here! How can a beginning programmer possibly know about the advantages and disadvantages of a language before learning it, and how should the programmer know if this language will be useful to her at all? This is what I would do: Just search for particular applications and solutions related to your most common problem tasks on Google and GitHub. You don’t need to read and understand the code. Just look at the end product. Also, don’t hesitate to ask people. Don’t just ask about the “best” programming language in general but be specific, describe your goals and why you want to learn how to program. If you want to develop applications for MacOS X you will probably want to check out Objective C and Swift, if you want to develop on Android, you are probably more interested in learning Java and so on. ⇧
What are my favorite Python tools?
If you are interested, those are my favorite and most frequently used Python “tools,” I use most of them on a daily basis.
- NumPy: My favorite library for working with array structures and vectorizing equations using linear algebra; augmented by SciPy.
- Theano: Implementing machine learning algorithms for the heavy-lifting and distributing computations across cores in my GPU(s).
- scikit-learn: The most convenient API for the daily, more basic machine learning tasks.
- matplotlib: My library of choice when it comes to plotting. Sometimes I also use seaborn for particular plots, for example, the heat maps are particularly great!
(Source: http://stanford.edu/~mwaskom/software/seaborn/examples/structured_heatmap.html)
- Flask (Django): Rarely, I want to turn an idea into a web application. Here, Flask comes in very handy!
- SymPy: For symbolic math, it replaced WolframAlpha for me.
- pandas: Working with relatively small datasets, mostly from CSV files.
- sqlite3: Annotating and querying “medium-sized” datasets.
- IPython notebooks: What can I say, 90% of my research takes place in IPython notebooks. It’s just a great environment to have everything in one place: Ideas, code, comments, LaTeX equations, illustrations, plots, outputs, …
Note that the IPython Project recently evolved into Project Jupyter. Now, you can use Jupyter notebook environment not only for Python but R, Julia, and many more. ⇧
What do I think about MATLAB?
I used MATLAB (/Octave) quite extensively some years ago; most of the computer science-data science classes were taught in MATLAB. I really think that it’s not a bad environment for prototyping after all! Since it was built with linear algebra in mind (MATLAB for MATrix LABoratory), MATLAB feels a tad more “natural” when it comes to implementing machine learning algorithms compared to Python/NumPy – okay, to be fair, 1-indexed programming languages may seem a little bit weird to us programmers. However, keep in mind that MATLAB comes with a big price tag, and I think it is slowly fading from academia as well as industry. Plus, I am a big fan open-source enthusiast after all ;). In addition, its performance is also not that compelling compared to other “productive” languages looking at the benchmarks below:
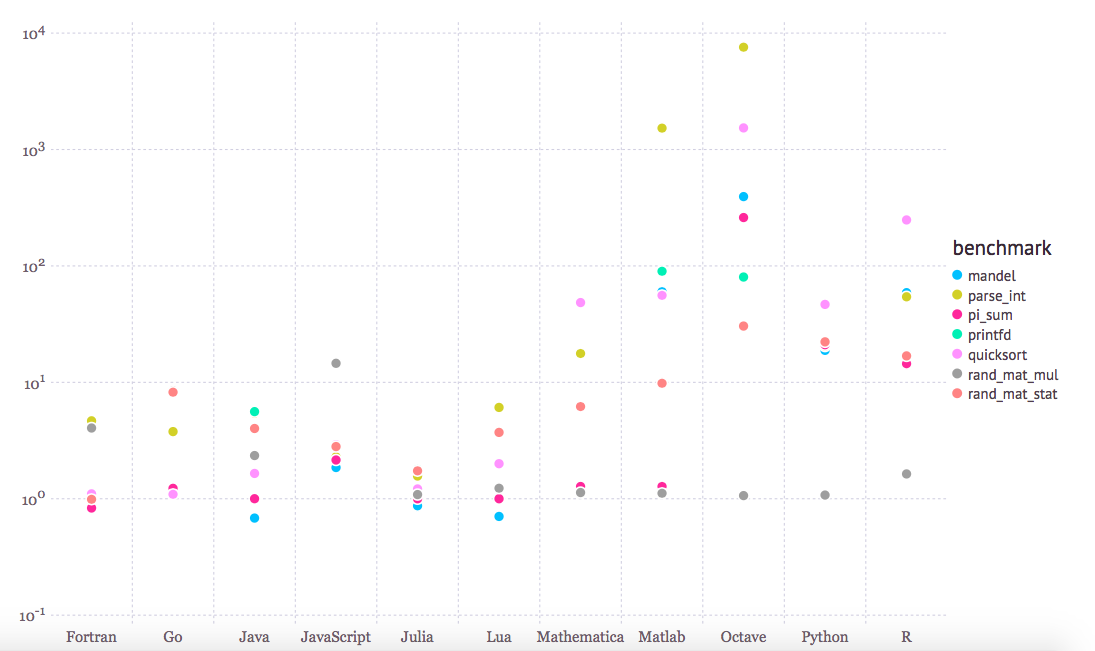
(Benchmark times relative to C – smaller is better, C performance = 1.0; Source: http://julialang.org/benchmarks/)
However, we should not forget that there is also this neat Theano library for Python. In 2010, the developers of Theano reported an 1.8x faster performance than NumPy when the code was run on the CPU, and if Theano targeted the GPU, it was even 11x faster than NumPy (J. Bergstra, O. Breuleux, F. Bastien, P. Lamblin, R. Pascanu, G. Desjardins, J. Turian, D. Warde-Farley, and Y. Bengio. Theano: A CPU and GPU math compiler in Python. In Proc. 9th Python in Science Conf, pages 1–7, 2010.). Now, keep in mind that this Theano benchmark is from 2010, and Theano has improved significantly over the years and so did the capabilities of modern graphics cards.
I have learned that many of the Greeks believe Pythagoras said all things are generated from number. The very assertion poses a difficulty: How can things which do not exist even be conceived to generate? - Theano of Croton (Philosopher, 6th-century BC)
PS: If you don’t like NumPy’s dot method, stay tuned for the upcoming Python 3.5 – we will get an infix operator for matrix multiplication, yay!
Matrix-matrix multiplication “by hand” (I mean without the help of NumPy and BLAS or LAPACK looks tedious and pretty inefficient).
[[1, 2], [[5, 6], [[1 * 5 + 2 * 7, 1 * 6 + 2 * 8],
[3, 4]] x [7, 8]] = [3 * 5 + 4 * 7, 3 * 6 + 4 * 8]]
Who wants to implement this expression using nested for-loops if we have linear algebra and libraries that are optimized to take care of it!?
>>> X = numpy.array()
>>> W = numpy.array()
>>> X.dot(W)
[[19, 22],
[43, 50]]
Now, if this dot product does not appeal to you, this is how it will look like in Python 3.5:
>>> X @ W
[[19, 22],
[43, 50]]
To be honest, I have to admit that I am not necessarily a big fan of the “@” symbol as matrix operator. However, I really thought long and hard about this and couldn’t find any better “unused” symbol for this purpose. If you have a better idea, please let me know, I am really curious! ⇧
Julia is awesome … on paper!
I think Julia is a great language, and I would like to recommend it to someone who’s getting started with programming and machine learning. I am not sure if I really should though. Why? There is this sad, somewhat paradoxical thing about committing to programming languages. With Julia, we cannot tell if it will become “popular” enough in the next few years. Wait, what does “popularity” have to do with how good and useful a programming language is? Let me tell you. The dilemma is that the most useful languages are not necessarily the ones that are well designed but the ones that are popular. Why?
- There are a lot of (mostly free) libraries out there already so that you can make best use of your time and don’t have to reinvent the wheel.
- It is much easier to find help, tutorials, and examples online.
- The language improves, gets updated, and patches are applied more frequently to make it “even better.”
- It is better for collaboration and easier to work in teams.
- More people will benefit from your code (for example, if you decide to share it on GitHub).
Personally, I love Julia for what it is. It perfectly fits my niche of interest. I use Python though; mainly because there is so much great stuff out there that makes it especially handy. The Python community is just great, and I believe that it will be around and thriving in the (at least) next 5 to 10 upcoming years. With Julia, I am not so sure. I love the design, I think it’s great. Nevertheless, if it is not popular, I can’t tell if it is “future-proof.” What if the development stops in a couple of years? I would have invested in something that will be “dead” at that point. However, if everyone would think like this, no new language would ever stand a chance. ⇧
There is really nothing wrong with R
Well, I guess it’s no big secret that I was an R person once. I even wrote a book about it (okay, it was actually about Heat maps in R to be precise. Note that this was years ago, before ggplot2 was a thing. There’s no real compelling reason to check it out – I mean the book. However, if you can’t resist, here’s is the free, 5-minute-read short version).
I agree, this is a bit of a digression. So, back to the discussion: What’s wrong with R? I think there is nothing wrong with it at all. I mean, it’s pretty powerful and a capable and “popular” language for “data science” after all! Not too long ago even Microsoft became really, really interested: Microsoft acquires Revolution Analytics, a commercial provider of services for the open source R programming language for statistical computing and predictive analytics.
So, how can I summarize my feelings about R? I am not exactly sure where this quote is comes from – I picked it up from someone somewhere some time ago – but it is great for explaining the difference between R and Python: “R is a programming language developed by statisticians for statisticians; Python was developed by a computer scientist, and it can be used by programmers to apply statistical techniques.” Part of the message is that both R and Python are similarly capable for “data science” tasks, however, the Python syntax simply feels more natural to me – it’s a personal taste.
I just wanted to bring up Theano and computing on GPUs as a big plus for Python, but I saw that R is also pretty capable: Parallel Programming with GPUs and R. I know what you want to ask next: “Okay, what about turning my model into a nice and shiny web application? I bet this is something that you can’t do in R!” Sorry, but you lose this bet; have a look at Shiny by RStudio A web application framework for R. You see what I am getting at? There is no winner here. There will probably never be,
To take one of my favorite Python quotes out of its original context: “We are all adults here” – let’s not waste our time with language wars. Choose the tool that “clicks” for you. When it comes to perspectives on the job market: There is no right or wrong here either. I don’t think a company that wants to hire you as a “data scientist” really bothers about your favorite toolbox – programming languages are just “tools” after all. The most important skill is to think like a “data scientist,” to ask the right questions, to be able to solve problems. The hard part is the math and machine learning theory, a new programming language can easily be learned. Just think about, you learned how to swing a hammer to drive the nail in, how hard can it possibly be to pick up a hammer from a different manufacturer? But if you are still interested, look at the Tiobe Index for example, one measure of popularity of programming languages:
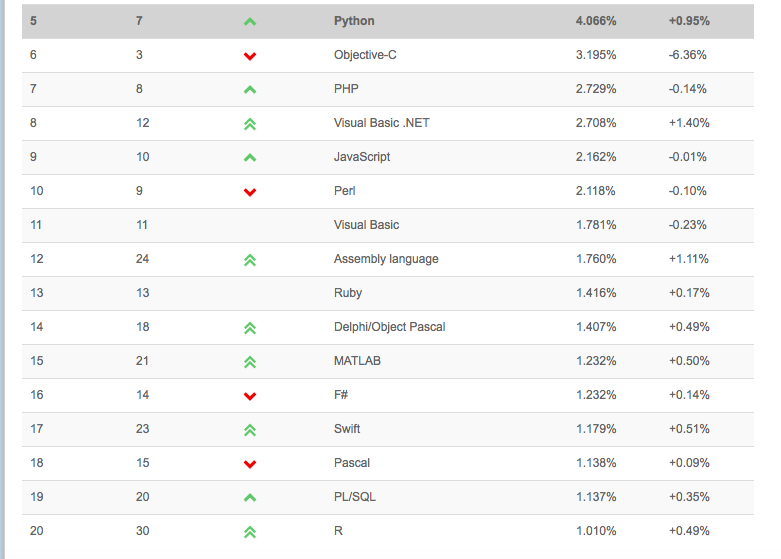
(Source: http://www.tiobe.com/index.php/content/paperinfo/tpci/index.html)
However, if we look at the The 2015 Top Ten Programming Languages by Spectrum IEEE, the R language is climbing fast (left column: 2015, right column: 2014).
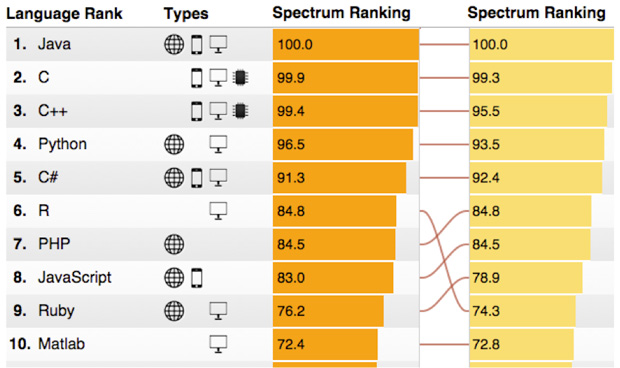
(Source: http://spectrum.ieee.org/computing/software/the-2015-top-ten-programming-languages)
I think you get the idea. Python and R, there’s really no big difference anymore. Moreover, you shouldn’t worry about job opportunities when you are choosing one language over the other. ⇧
What happened to Perl?
Perl was the first language I picked up in my early career (aside from Basic, Pascal, and Delphi in High School of course). I took a Perl programming class when I was still an undergrad in Germany. At that time I really liked it, but hey, I really didn’t have anything to compare it to at this point either. Personally, I only know a handful of people who are actively using Perl for scripting on a day-to-day basis. I think it is still quite common in the bioinformatics field though!? Anyways, let’s keep this part short so that it can rest in peace: ““Perl is Dead. Long live Perl.” ⇧
Other options
There are many other languages that can are used for Machine Learning, for example, Ruby (Thoughtful Machine Learning: A Test-Driven Approach), Java (Java-ML), Scala (Breeze), Lua (Torch), and so on. However, except for a Java class I attended years ago, or PySpark, a Python API for Spark, which is written in Scala, I really don’t have much experience with those languages and wouldn’t know what to say. ⇧
Is Python a dying language?
This is a legit question, it came up on Quora recently, and if you want to hear many other great opinions on this, check out the question thread. However, if you want to hear my opinion, I would say No, it is not. Why? Okay, Python is a “relatively” old language - the first release was sometime in the early 90s (we can start counting at 1991), and like with every programming language, certain choices and compromises had to be made. Every programming language has its quirks, and the more modern languages tend to learn from the mistakes of the past, which is a good thing (R was released not long after Python by the way: 1995). Python is far from being “perfect,” and like every other language, it has its warts. As a core Python user, I have to say that the GIL (Global Interpreter Lock) is what annoys me most – but note that there a multiprocessing and multithreading modules, and it’s not really a limitation but more of a little “inconvenience” in certain contexts.
There is no metric that can quantify “how good” a programming language is, and it really depends on what you are looking for. The question you’d want to ask is: “What do I want to achieve, and which is the best tool to accomplish that” – “if all you have is a hammer, everything looks like a nail.” Speaking of hammers and nails again, Python is extremely versatile, the largest chunk of my day-to-day research happens via Python using the great scikit-learn machine learning library, pandas for data munging, matplotlib/seaborn for visualization, and IPython notebooks to keep track of all those things. ⇧
Conclusion
Well, this is a pretty long answer to a seemingly very simple question. Trust me, I can go on for hours and days. But why complicate things? Let’s bring the talks to a conclusion:

(Source: https://xkcd.com/353/)
Thank you for reading. If you liked this content, you can also find me on Twitter, where I share more helpful content.
Feedback and opinions
I so much great feedback about this article that I want to share with you. Remember, it’s in the nature of the “piece of advice” to be biased; you may have noticed that my bias is pretty much in favor of Python – sorry, but that’s who I am! I believe that it may be helpful to hear other people’s thoughts too! Especially, if you are new to the “data science,” machine learning, and programming field. That being said, please go ahead and take a look at those informative comments below! ⇧
Python
- rm999 on hackernews:
I switched from mostly using R to Python about a year ago for gluing together my data pipeline (from data source all the way to production models and frontends/visualizations). It hasn’t really impacted what I’m capable of doing or my productivity, except the standard extra googling that comes in the first couple years I use any language. The main reason I went for Python is purely practical: it’s a language people outside my team will respect and deal with. It makes it easier for me to collaborate in many different ways: share tools with other teams, transfer ownership of my code, get help when I need it, etc. Data science at some companies has the reputation of “hack something together and throw it over the wall for someone else to deal with”. In my experience R only furthers this reputation. Which is too bad, it’s really great at what it does.
- DrNuke on hackernews:
I love the hacking approach in the post: a tool is only a tool to do something valuable and not the goal itself. The Python ecosystem is the right tool at the right time, nowadays, because of the data science explosion and the need to interact very quickly with non-specialists.
- zzleeper on hackernews:
Quite interesting post. I feel that a lot of the numerical Pythonistas are in the same spot: They tolerate most languages, but find R’s syntax a bit unnatural, Matlab lacking when trying to go beyond pure matrix stuff, and are waiting to see if Julia picks up (which it seems to be from what I can tell)
- JanneJM on reddit:
The key is enough good-quality libraries. Many people I know - myself included - aren’t really interested in Python as such. We’re using Numpy, Scipy, Matplotlib, Pandas and so on and so on. Python just comes along for the ride. Had these libraries appeared for Ruby or Perl or Lua, then that’s what we would be using today.
Perl
- leni536 on hackernews
“I think it Perl is still quite common in the bioinformatics field though!?” That’s true - many day-to-day tasks in bioinformatics are more or less plain-text parsing [1], and Perl excels in parsing text and quickly using regular expressions. “My” generation of bioinformaticians doing data cleanup and analysis (20–30) uses Python, sometimes because plotting is nicer, the language is easier to get into, it’s more commonly taught in universities, or other reasons - people older than that normally use P
R
- geomark on hackernews
I just completed the Coursera data science track which took me from a complete R newbie to being at least somewhat proficient. Having previously used Python for a quite a bit of web programming, I disliked R at first except for its power in statistical programming. But I’ve since discovered a number of great R packages that make it a pleasure to use for things I would normally turn to Python for. Like I recently discovered the rvest package for webscraping. Data visualizations with R seem vastly superior, unless I am missing something with Python (highly likely). And putting up a slick statistics app is easy with shiny or RStudio Presenter. But R can’t really scale to a large production app, isn’t that right? So I feel I need to keep working with both Python and R. Added: That’s a nice list Lofkin. Thanks. Also, in the article he says that Python syntax feels more natural, which I also felt. But then I started to use things like the magrittr and dplyr packages in R which gives you nice things like pipes and that feeling starts to ebb.
- Adam_O on hackernews
From the perspective of a student, most of the good online analytics/data analysis/stats courses use R, so it is hard to get away from it while learning the material. Once you get the base concepts down, switching to python shouldn’t be hard. I think most people still prefer ggplot2 for visualization though. Whenever I use R I feel like a statistician, I can feel that ‘cold rigor’ emanating from the language. But in the end I think it is advantageous to wield both languages.
MATLAB/Octave
- sampo on hackernews
Andrew Ng said in the Coursera Machine learning class that according to his experience, students implement the course homework faster in Octave/Matlab than in Python. But yes, the point of that course is to implement and play around with small numerical algorithms, whereas the linked blog is about someone who mainly calls existing machine learning libraries from Python.
- misiti3780 on hackernews
Octave/Matlab are “great” but good luck trying to integrate them into a production web application. Since you cant really do that - avoid using them unless you are fine with implementing the same algorithm twice. Matlab licenses cost money also, and the toolboxes cost additional money. R is useful because there are a lot of resources as it has been along for so long and is used by a large portion of the stats community. It also has a lot of useful libraries that have not been ported over to other languages yet (ggmap!!!). But you still still run into the same problem that you cannot integrate R into a production web application. I am pretty sure Hadoop streaming does not support R,Octave, or Matlab either
- thanatropism on hackernews
One thing missing here: Matlab syntax is actually very close to modern Fortran. At least twice I’ve written Fortran code (for Monte Carlo simulations; different contexts) by overwriting Matlab code adding types / general verbosity / fixing the syntax of do-loops / etc.
Julia
- Lofkin on hackernews:
Personally I’m tempted to make the switch to Julia, but slow higher order functions, high churn in the core data infrastructure and no Pymc 3 are keeping me on pydata for a bit longer. I have numba to hold me over.
- Buttons 840 on hackernews:
I’ve used Python professionally for 8 years, and it’s my favorite language. I have used numpy and a scikit-learn a little bit. That said, I’ve really enjoying learning Julia recently. It’s been easy to learn and it really does perform well (read: it’s fast). In fact, I think learning Julia has been about as much work as learning something like numba would be, and gives similar (some say slightly better?) performance.
- idunning on hackernews:
As someone who almost exclusively uses Julia for their day-to-day work (and side projects), I think most of the author’s thoughts about Julia are correct. I think the language is great, and using it makes my life better. There are some packages that are actually better than any of their equivalents in other languages, in my opinion. On the other hand, I’ve also got a higher tolerance for things not being perfect, I can figure things out for myself (and luckily have the time do so), and I’m willing to code it up if it doesn’t already exist (to a point). Naturally, that is not true for most people, and thats fine. The author isn’t willing to take the risk that Julia won’t “survive”, which is fair. Its definitely not complete yet, but its getting there. I am confident that it will survive (and thrive) though, and continue growing the not-insubstantial community. I have a feeling the author will find their way to Julia-land eventually, in a couple of years or so.
- niksko on reddit:
I agree on the subject of Julia. It has really great potential and it’s basically tailor-made for these sorts of applications, but the community and support just isn’t there yet. I spent a semester doing a small research project in the area of computation evolutionary dynamics, and the most tedious and difficult part was getting Julia to plot what I wanted to. Also it didn’t have docstring support at the time :/. It’s fast, it’s fancy, but it’s not mature enough.
- KG7ULQ on reddit:
After I took the Ng ML course on Coursera I looked around and it seemed like the thing to do was to use Python… but there were several large libraries including the ones you mention that had to be learned. Then I looked at Julia and figured that I might as well learn it as it already has all of the linear algebra & SIMD stuff built in and is more performant. It really does seem like the “sweet-spot” language for ML.
Other Languages (that I forgot to mention)
- leni536 on hackernews:
And there is nothing wrong with C++. For linear algebra I use the armadillo library and it’s really a nice wrapper around LAPACK and BLAS (and fast!). For some reason scientists are somewhat afraid of C++. For some reason you “have to” prototype in an “easier” language. Sure, you can’t use C++ as a calculator as opposed to interpreted languages, but I see people being stuck with their computations at the prototyping language and eventually not bringing it to a faster platform. Point being: C++ is not hard for scientific calculations.
- WallyMetropolis on reddit:
If anything is going to replace Python for me, it looks like Scala is the likeliest candidate. I think functional languages are a nice fit for mathy work, and it’s on the JVM so prototypes can become production code without much overhead that can run ‘anywhere.’ Spark is a killer app for Scala. Now I can go from prototype to running on an arbitrarily large dataset without too much barrier in between.
- rpcope1 on reddit:
[Scala] may be slow on the compilation, but it’s both safer and far faster than CPython (barring using code that’s not bytecode and calls to C/Fortran libraries), and has a number of concepts that I am really missing in Python now, like Option[T], the implicit modifier, non-crap map/reduce/filter, non-crap lambdas, etc.
Read Next
 Scientific Computing in Python: Introduction to NumPy and Matplotlib
Beginner's guide to NumPy and Matplotlib for scientific computing: arrays, indexing, broadcasting, linear algebra, and plotting with Python code examples.
Scientific Computing in Python: Introduction to NumPy and Matplotlib
Beginner's guide to NumPy and Matplotlib for scientific computing: arrays, indexing, broadcasting, linear algebra, and plotting with Python code examples.
 Model evaluation, model selection, and algorithm selection in machine learning
Part 4 of the model evaluation series explaining statistical tests, algorithm comparisons, corrected resampled tests, and nested cross-validation.
Model evaluation, model selection, and algorithm selection in machine learning
Part 4 of the model evaluation series explaining statistical tests, algorithm comparisons, corrected resampled tests, and nested cross-validation.
 Generating Gender-Neutral Face Images with Semi-Adversarial Neural Networks to Enhance Privacy
I thought that it would be nice to have short and concise summaries of recent projects handy, to share them with a more general audience, including...
Generating Gender-Neutral Face Images with Semi-Adversarial Neural Networks to Enhance Privacy
I thought that it would be nice to have short and concise summaries of recent projects handy, to share them with a more general audience, including...

If you read the book and have a few minutes to spare, I'd really appreciate a brief review. It helps us authors a lot!
Your support means a great deal! Thank you!