Scientific Computing in Python: Introduction to NumPy and Matplotlib
-- Including Video Tutorials
Since many students in my Stat 451: Introduction to Machine Learning and Statistical Pattern Classification class are relatively new to Python and NumPy, I was recently devoting a lecture to the latter. Since the course notes are based on an interactive Jupyter notebook file, which I used as a basis for the lecture videos, I thought it would be worthwhile to reformat it as a blog article with the embedded “narrated content” – the video recordings.
Additional Material:
-
Here is a link to a Deepnote version of this article that you can interact with in your browser.
-
A link to the Jupyter notebook version of this article can be found on GitHub at: https://github.com/rasbt/numpy-intro-blogarticle-2020.
The code for this article was generated using the following software versions:
- CPython 3.8.3
- numpy 1.19.1
- matplotlib 3.3.1
4.1: NumPy Basics
NumPy – Working with Numerical Arrays
Introduction to NumPy
This section offers a quick tour of the NumPy library for working with multi-dimensional arrays in Python. NumPy (short for Numerical Python) was created in 2005 by merging Numarray into Numeric. Since then, the open source NumPy library has evolved into an essential library for scientific computing in Python. It has become a building block of many other scientific libraries, such as SciPy, Scikit-learn, Pandas, and others.
What makes NumPy so incredibly attractive to the scientific community is that it provides a convenient Python interface for working with multi-dimensional array data structures efficiently; the NumPy array data structure is also called ndarray, which is short for n-dimensional array.
In addition to being mostly implemented in C and using Python as a “glue language,” the main reason why NumPy is so efficient for numerical computations is that NumPy arrays use contiguous blocks of memory that can be efficiently cached by the CPU. In contrast, Python lists are arrays of pointers to objects in random locations in memory, which cannot be easily cached and come with a more expensive memory-look-up. However, the computational efficiency and low-memory footprint come at a cost: NumPy arrays have a fixed size and are homogeneous, which means that all elements must have the same type. Homogenous ndarray objects have the advantage that NumPy can carry out operations using efficient C code and avoid expensive type checks and other overheads of the Python API. While adding and removing elements from the end of a Python list is very efficient, altering the size of a NumPy array is very expensive since it requires to create a new array and carry over the contents of the old array that we want to expand or shrink.
Besides being more efficient for numerical computations than native Python code, NumPy can also be more elegant and readable due to vectorized operations and broadcasting, which are features that we will explore in this article.
Today, NumPy forms the basis of the scientific Python computing ecosystem.
Motivation: NumPy is fast!
Here is some motivation before we discuss further details, highlighting why learning about and using NumPy is useful. We take a look at a speed comparison with regular Python code. In particular, we are computing a vector dot product in Python (using lists) and compare it with NumPy’s dot-product function. Mathematically, the dot product between two vectors \(\mathbf{x}\) and \(\mathbf{w}\) can be written as follows:
\[z = \sum_i x_i w_i = x_1 \times w_1 + x_2 \times w_2 + ... + x_n \times w_n = \mathbf{x}^\top \mathbf{w}\]First, the Python implementation using a for-loop:
In:
def python_forloop_list_approach(x, w):
z = 0.
for i in range(len(x)):
z += x[i] * w[i]
return z
a = [1., 2., 3.]
b = [4., 5., 6.]
print(python_forloop_list_approach(a, b))
Out:
32.0
Let us compute the runtime for two larger (1000-element) vectors using IPython’s %timeit magic function:
In:
large_a = list(range(1000))
large_b = list(range(1000))
%timeit python_forloop_list_approach(large_a, large_b)
Out:
100 µs ± 9.48 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
Next, we use the dot function/method implemented in NumPy to compute the dot product between two vectors and run %timeit afterwards:
In:
import numpy as np
def numpy_dotproduct_approach(x, w):
# same as np.dot(x, w)
# and same as x @ w
return x.dot(w)
a = np.array([1., 2., 3.])
b = np.array([4., 5., 6.])
print(numpy_dotproduct_approach(a, b))
Out:
32.0
In:
large_a = np.arange(1000)
large_b = np.arange(1000)
%timeit numpy_dotproduct_approach(large_a, large_b)
Out:
1.13 µs ± 31.5 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
As we can see, replacing the for-loop with NumPy’s dot function makes the computation of the vector dot product approximately 100 times faster.
N-dimensional Arrays
NumPy is built around ndarrays objects, which are high-performance multi-dimensional array data structures. Intuitively, we can think of a one-dimensional NumPy array as a data structure to represent a vector of elements – you may think of it as a fixed-size Python list where all elements share the same type. Similarly, we can think of a two-dimensional array as a data structure to represent a matrix or a Python list of lists. While NumPy arrays can have up to 32 dimensions if it was compiled without alterations to the source code, we will focus on lower-dimensional arrays for the purpose of illustration in this introduction.
Now, let us get started with NumPy by calling the array function to create a two-dimensional NumPy array, consisting of two rows and three columns, from a list of lists:
In:
a = [1., 2., 3.]
np.array(a)
Out:
array([1., 2., 3.])
In:
lst = [[1, 2, 3],
[4, 5, 6]]
ary2d = np.array(lst)
ary2d
# rows x columns
Out:
array([[1, 2, 3],
[4, 5, 6]])
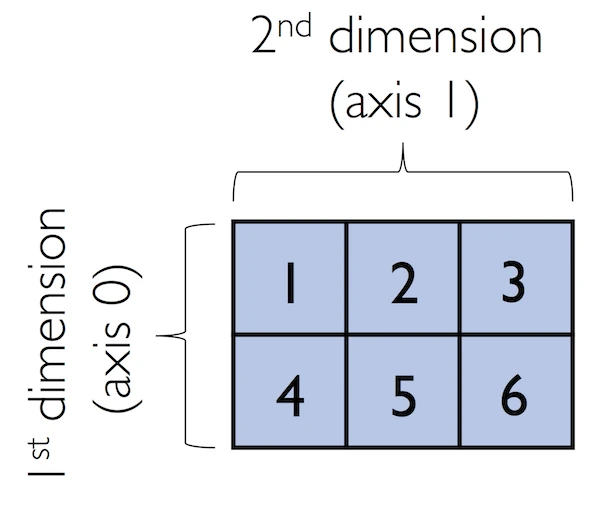
By default, NumPy infers the type of the array upon construction. Since we passed Python integers to the array, the ndarray object ary2d should be of type int64 on a 64-bit machine, which we can confirm by accessing the dtype attribute:
In:
ary2d.dtype
Out:
dtype('int64')
If we want to construct NumPy arrays of different types, we can pass an argument to the dtype parameter of the array function, for example np.int32, to create 32-bit arrays. For a full list of supported data types, please refer to the official NumPy documentation. Once an array has been constructed, we can downcast or recast its type via the astype method as shown in the following examples:
In:
int32_ary = ary2d.astype(np.int32)
int32_ary
Out:
array([[1, 2, 3],
[4, 5, 6]], dtype=int32)
In:
float32_ary = ary2d.astype(np.float32)
float32_ary
Out:
array([[1., 2., 3.],
[4., 5., 6.]], dtype=float32)
In:
float32_ary.dtype
Out:
dtype('float32')
The code snippet above returned 8, which means that each element in the array (remember that ndarrays are homogeneous) takes up 8 bytes in memory. This result makes sense since the array ary2d has type int64 (64-bit integer), which we determined earlier, and 8 bits equals 1 byte. (Note that 'int64' is just a shorthand for np.int64.)
To return the number of elements in an array, we can use the size attribute, as shown below:
And the number of dimensions of our array (Intuitively, you may think of dimensions as the rank of a tensor) can be obtained via the ndim attribute:
In:
ary2d
Out:
array([[1, 2, 3],
[4, 5, 6]])
In:
ary2d.ndim
Out:
2
If we are interested in the number of elements along each array dimension (in the context of NumPy arrays, we may also refer to them as axes), we can access the shape attribute as shown below:
In:
len(ary2d.shape)
Out:
2
The shape is always a tuple; in the code example above, the two-dimensional ary object has two rows and three columns, (2, 3), if we think of it as a matrix representation.
Conversely, the shape (an object of type tuple) of a one-dimensional array only contains a single value:
In:
np.array([1., 2., 3.]).shape
Out:
(3,)
4.2: NumPy Array Construction and Indexing
Array Construction Routines
This section provides a non-comprehensive list of array construction functions. Simple yet useful functions exist to construct arrays containing ones or zeros:
In:
np.ones((3, 4), dtype=np.int)
Out:
array([[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]])
In:
np.zeros((3, 3))
Out:
array([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]])
We can use these functions to create arrays with arbitrary values, e.g., we can create an array containing the values 99 as follows:
In:
np.zeros((3, 3)) + 99
Out:
array([[99., 99., 99.],
[99., 99., 99.],
[99., 99., 99.]])
Creating arrays of ones or zeros can also be useful as placeholder arrays, in cases where we do not want to use the initial values for computations but want to fill it with other values right away. If we do not need the initial values (for instance, '0.' or '1.'), there is also numpy.empty, which follows the same syntax as numpy.ones and np.zeros. However, instead of filling the array with a particular value, the empty function creates the array with non-sensical values from memory. We can think of zeros as a function that creates the array via empty and then sets all its values to 0. – in practice, a difference in speed is not noticeable, though.
NumPy also comes with functions to create identity matrices and diagonal matrices as ndarrays that can be useful in the context of linear algebra – a topic that we will explore later in this article.
In:
np.eye(3)
Out:
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
In:
np.diag((1, 2, 3))
Out:
array([[1, 0, 0],
[0, 2, 0],
[0, 0, 3]])
Lastly, I want to mention two very useful functions for creating sequences of numbers within a specified range, namely, arange and linspace. NumPy’s arange function follows the same syntax as Python’s range objects: If two arguments are provided, the first argument represents the start value and the second value defines the stop value of a half-open interval:
In:
np.arange(4, 10)
Out:
array([4, 5, 6, 7, 8, 9])
Notice that arange also performs type inference similar to the array function. If we only provide a single function argument, the range object treats this number as the endpoint of the interval and starts at 0:
In:
np.arange(5)
Out:
array([0, 1, 2, 3, 4])
Similar to Python’s range, a third argument can be provided to define the step (the default step size is 1). For example, we can obtain an array of all uneven values between one and ten as follows:
In:
np.arange(1., 11., 0.1)
Out:
array([ 1. , 1.1, 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9, 2. ,
2.1, 2.2, 2.3, 2.4, 2.5, 2.6, 2.7, 2.8, 2.9, 3. , 3.1,
3.2, 3.3, 3.4, 3.5, 3.6, 3.7, 3.8, 3.9, 4. , 4.1, 4.2,
4.3, 4.4, 4.5, 4.6, 4.7, 4.8, 4.9, 5. , 5.1, 5.2, 5.3,
5.4, 5.5, 5.6, 5.7, 5.8, 5.9, 6. , 6.1, 6.2, 6.3, 6.4,
6.5, 6.6, 6.7, 6.8, 6.9, 7. , 7.1, 7.2, 7.3, 7.4, 7.5,
7.6, 7.7, 7.8, 7.9, 8. , 8.1, 8.2, 8.3, 8.4, 8.5, 8.6,
8.7, 8.8, 8.9, 9. , 9.1, 9.2, 9.3, 9.4, 9.5, 9.6, 9.7,
9.8, 9.9, 10. , 10.1, 10.2, 10.3, 10.4, 10.5, 10.6, 10.7, 10.8,
10.9])
The linspace function is especially useful if we want to create a particular number of evenly spaced values in a specified half-open interval:
In:
np.linspace(6., 15., num=10)
Out:
array([ 6., 7., 8., 9., 10., 11., 12., 13., 14., 15.])
Array Indexing
In this section, we will go over the basics of retrieving NumPy array elements via different indexing methods. Simple NumPy indexing and slicing works similar to Python lists, which we will demonstrate in the following code snippet, where we retrieve the first element of a one-dimensional array:
In:
ary = np.array([1, 2, 3])
ary[0]
Out:
1
Also, the same Python semantics apply to slicing operations. The following example shows how to fetch the first two elements in ary:
In:
ary[0:3] # equivalent to ary[0:2]
Out:
array([1, 2, 3])
If we work with arrays that have more than one dimension or axis, we separate our indexing or slicing operations by commas as shown in the series of examples below:
In:
ary = np.array([[1, 2, 3],
[4, 5, 6]])
ary[0, -2] # first row, second from last element
Out:
2
In:
ary[-1, -1] # lower right
Out:
6
In:
ary[1, 1] # first row, second column
Out:
5
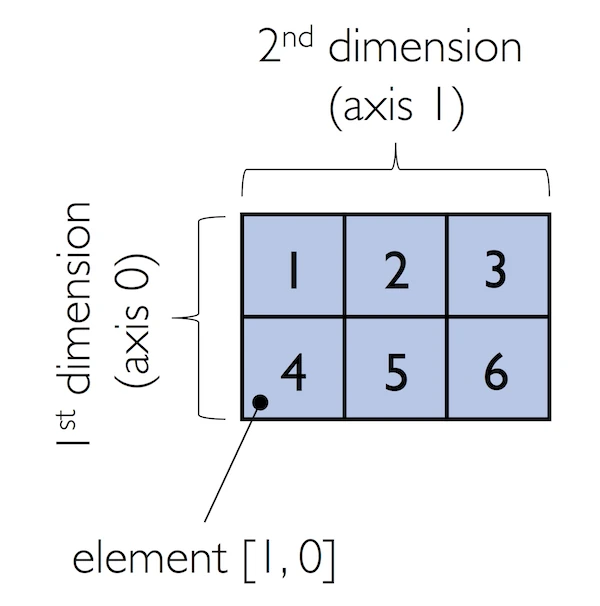
In:
ary[:, 0] # entire first column
Out:
array([1, 4])
In:
ary[:, :2] # first two columns
Out:
array([[1, 2],
[4, 5]])
4.3: NumPy Array Math and Universal Functions
Array Math and Universal Functions
In the previous sections, you learned how to create NumPy arrays and how to access different elements in an array. It is about time that we introduce one of the core features of NumPy that makes working with ndarray so efficient and convenient: vectorization. While we typically use for-loops if we want to perform arithmetic operations on sequence-like objects, NumPy provides vectorized wrappers for performing element-wise operations implicitly via so-called ufuncs – “ufuncs” is short for universal functions.
As of this writing, there are more than 60 ufuncs available in NumPy; ufuncs are implemented in compiled C code and very fast and efficient compared to vanilla Python. In this section, we will take a look at the most commonly used ufuncs, and I recommend you to check out the official documentation for a complete list.
To provide an example of a simple ufunc for element-wise addition, consider the following example, where we add a scalar (here: 1) to each element in a nested Python list:
In:
lst = [[1, 2, 3],
[4, 5, 6]] # 2d array
for row_idx, row_val in enumerate(lst):
for col_idx, col_val in enumerate(row_val):
lst[row_idx][col_idx] += 1
lst
Out:
[[2, 3, 4], [5, 6, 7]]
This for-loop approach is very verbose, and we could achieve the same goal more elegantly using list comprehensions:
In:
lst = [[1, 2, 3], [4, 5, 6]]
[[cell + 1 for cell in row] for row in lst]
Out:
[[2, 3, 4], [5, 6, 7]]
We can accomplish the same using NumPy’s ufunc for element-wise scalar addition as shown below:
In:
ary = np.array([[1, 2, 3], [4, 5, 6]])
ary = np.add(ary, 1) # binary ufunc
ary
Out:
array([[2, 3, 4],
[5, 6, 7]])
The ufuncs for basic arithmetic operations are add, subtract, divide, multiply, power, and exp (exponential). However, NumPy uses operator overloading so that we can use mathematical operators (+, -, /, *, and **) directly:
In:
np.add(ary, 1)
Out:
array([[3, 4, 5],
[6, 7, 8]])
In:
ary + 1
Out:
array([[3, 4, 5],
[6, 7, 8]])
In:
np.power(ary, 2)
Out:
array([[ 4, 9, 16],
[25, 36, 49]])
In:
ary**2
Out:
array([[ 4, 9, 16],
[25, 36, 49]])
Above, we have seen examples of binary ufuncs, which are ufuncs that take two arguments as an input. In addition, NumPy implements several useful unary ufuncs, such as log (natural logarithm), log10 (base-10 logarithm), and sqrt (square root):
In:
np.sqrt(ary)
Out:
array([[1.41421356, 1.73205081, 2. ],
[2.23606798, 2.44948974, 2.64575131]])
Often, we want to compute the sum or product of array element along a given axis. For this purpose, we can use a ufunc’s reduce operation. By default, reduce applies an operation along the first axis (axis=0). In the case of a two-dimensional array, we can think of the first axis as the rows of a matrix. Thus, adding up elements along rows yields the column sums of that matrix as shown below:
In:
ary = np.array([[1, 2, 3],
[4, 5, 6]]) # rolling over the 1st axis, axis 0
np.add.reduce(ary, axis=0)
Out:
array([5, 7, 9])
To compute the row sums of the array above, we can specify axis=1:
In:
np.add.reduce(ary, axis=1) # row sums
Out:
array([ 6, 15])
While it can be more intuitive to use reduce as a more general operation, NumPy also provides shorthands for specific operations such as product and sum. For example, sum(axis=0) is equivalent to add.reduce:
In:
ary.sum(axis=0) # column sums
Out:
array([5, 7, 9])
In:
ary.sum(axis=1) # row sums
Out:
array([ 6, 15])
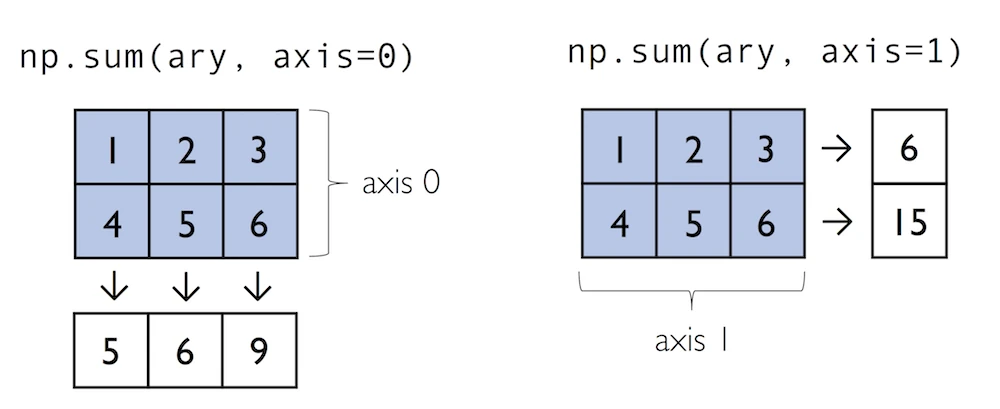
As a word of caution, keep in mind that product and sum both compute the product or sum of the entire array if we do not specify an axis:
In:
ary.sum()
Out:
21
Other useful unary ufuncs are:
-
np.mean(computes arithmetic mean or average) -
np.std(computes the standard deviation) -
np.var(computes variance) -
np.sort(sorts an array) -
np.argsort(returns indices that would sort an array) -
np.min(returns the minimum value of an array) -
np.max(returns the maximum value of an array) -
np.argmin(returns the index of the minimum value) -
np.argmax(returns the index of the maximum value) -
np.array_equal(checks if two arrays have the same shape and elements)
4.4: NumPy Broadcasting
Broadcasting
A topic we glanced over in the previous section is broadcasting. Broadcasting allows us to perform vectorized operations between two arrays even if their dimensions do not match by creating implicit multidimensional grids. You already learned about ufuncs in the previous section where we performed element-wise addition between a scalar and a multidimensional array, which is just one example of broadcasting.
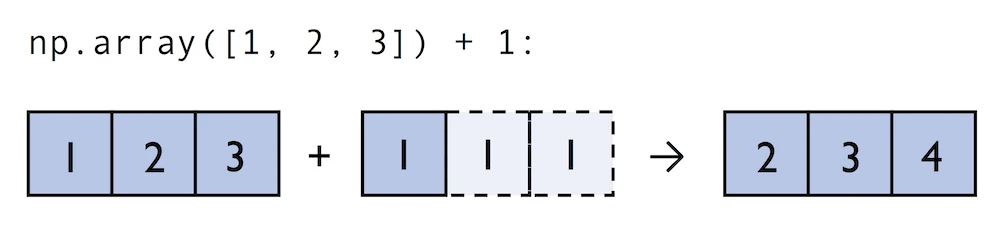
Naturally, we can also perform element-wise operations between arrays of equal dimensions:
In contrast to what we are used from linear algebra, we can also add arrays of different shapes. In the example above, we will add a one-dimensional to a two-dimensional array, where NumPy creates an implicit multidimensional grid from the one-dimensional array ary1:
In:
ary = np.array([1, 2, 3])
ary + 1
Out:
array([2, 3, 4])
In:
ary + np.array([1, 1, 1])
Out:
array([2, 3, 4])
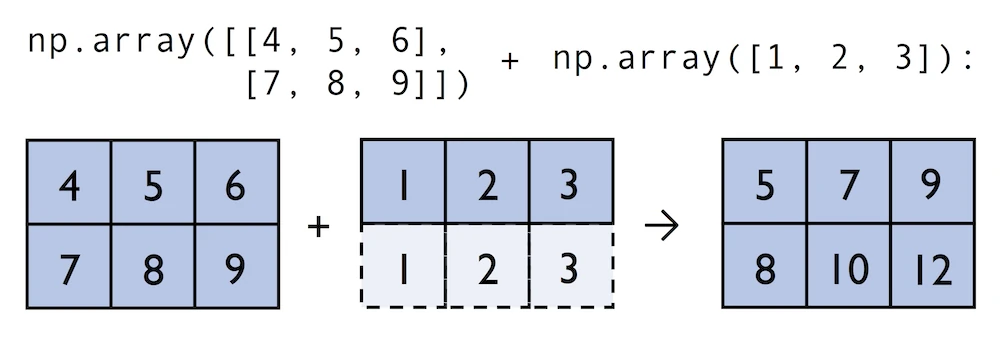
In:
ary2 = np.array([[4, 5, 6],
[7, 8, 9]])
ary2 + ary
Out:
array([[ 5, 7, 9],
[ 8, 10, 12]])
4.5: NumPy Advanced Indexing – Memory Views and Copies
Advanced Indexing – Memory Views and Copies
In the previous sections, we have used basic indexing and slicing routines. It is important to note that basic integer-based indexing and slicing create so-called views of NumPy arrays in memory. Working with views can be highly desirable since it avoids making unnecessary copies of arrays to save memory resources. To illustrate the concept of memory views, let us walk through a simple example where we access the first row in an array, assign it to a variable, and modify that variable:
In:
ary = np.array([[1, 2, 3],
[4, 5, 6]])
first_row = ary[0]
Out: In:
first_row
Out:
array([1, 2, 3])
In:
first_row += 99
Out:
As expected, first_row was modified, now containing the original values in the first row incremented by 99:
In:
first_row
Out:
array([100, 101, 102])
Note, however, that the original array was modified as well:
In:
ary
Out:
array([[100, 101, 102],
[ 4, 5, 6]])
As we saw in the example above, changing the value of first_row also affected the original array. The reason for this is that ary[0] created a view of the first row in ary, and its elements were then incremented by 99. The same concept applies to slicing operations:
In:
ary = np.array([[1, 2, 3],
[4, 5, 6]])
first_row = ary[1:3]
first_row += 99
ary
Out:
array([[ 1, 2, 3],
[103, 104, 105]])
In:
ary = np.array([[1, 2, 3],
[4, 5, 6]])
center_col = ary[:, 2]
center_col += 99
ary
Out:
array([[ 1, 2, 102],
[ 4, 5, 105]])
If we are working with NumPy arrays, it is always important to be aware that slicing creates views – sometimes it is desirable since it can speed up our code by avoiding to create unnecessary copies in memory. However, in certain scenarios we want force a copy of an array; we can do this via the copy method as shown below:
In:
ary = np.array([[1, 2, 3],
[4, 5, 6]])
first_row = ary[0].copy()
first_row += 99
In:
first_row
Out:
array([100, 101, 102])
In:
ary
Out:
array([[1, 2, 3],
[4, 5, 6]])
Fancy Indexing
In addition to basic single-integer indexing and slicing operations, NumPy supports advanced indexing routines called fancy indexing. Via fancy indexing, we can use tuple or list objects of non-contiguous integer indices to return desired array elements. Since fancy indexing can be performed with non-contiguous sequences, it cannot return a view – a contiguous slice from memory. Thus, fancy indexing always returns a copy of an array – it is important to keep that in mind. The following code snippets show some fancy indexing examples:
In:
ary = np.array([[1, 2, 3],
[4, 5, 6]])
ary[:, [0, 2]] # first and and last column
Out:
array([[1, 3],
[4, 6]])
In:
this_is_a_copy = ary[:, [0, 2]]
this_is_a_copy += 99
Note that the values in this_is_a_copy were incremented as expected:
In:
this_is_a_copy
Out:
array([[100, 102],
[103, 105]])
However, the contents of the original array remain unaffected:
In:
ary
Out:
array([[1, 2, 3],
[4, 5, 6]])
Boolean Masks for Indexing
Finally, we can also use Boolean masks for indexing – that is, arrays of True and False values. Consider the following example, where we return all values in the array that are greater than 3:
In:
ary = np.array([[1, 2, 3],
[4, 5, 6]])
greater3_mask = ary > 3
greater3_mask
Out:
array([[False, False, False],
[ True, True, True]])
Using these masks, we can select elements given our desired criteria:
In:
ary[greater3_mask]
Out:
array([4, 5, 6])
We can also chain different selection criteria using the logical and operator & or the logical or operator |. The example below demonstrates how we can select array elements that are greater than 3 and divisible by 2:
In:
(ary > 3) & (ary % 2 == 0)
Out:
array([[False, False, False],
[ True, False, True]])
Similar to the previous example, we can use this boolean array as a mask for selecting the respective elements from the array:
In:
ary[(ary > 3) & (ary % 2 == 0)]
Out:
array([4, 6])
Note that indexing using Boolean arrays is also considered “fancy indexing” and thus returns a copy of the array.
4.6: Random Number Generators
Random Number Generators
In machine learning and deep learning, we often have to generate arrays of random numbers – for example, the initial values of our model parameters before optimization. NumPy has a random subpackage to create random numbers and samples from a variety of distributions conveniently. Again, I encourage you to browse through the more comprehensive numpy.random documentation for a complete list of functions for random sampling.
To provide a brief overview of the pseudo-random number generators that we will use most commonly, let’s start with drawing a random sample from a uniform distribution:
In:
np.random.seed(123)
np.random.rand(3)
Out:
array([0.69646919, 0.28613933, 0.22685145])
In the code snippet above, we first seeded NumPy’s random number generator. Then, we drew three random samples from a uniform distribution via random.rand in the half-open interval [0, 1). I highly recommend the seeding step in practical applications as well as in research projects, since it ensures that our results are reproducible. If we run our code sequentially – for example, if we execute a Python script – it should be sufficient to seed the random number generator only once at the beginning to enforce reproducible outcomes between different runs. However, it is often useful to create separate RandomState objects for various parts of our code, so that we can test methods of functions reliably in unit tests. Working with multiple, separate RandomState objects can also be useful if we run our code in non-sequential order – for example if we are experimenting with our code in interactive sessions or Jupyter Notebook environments.
The example below shows how we can use a RandomState object to create the same results that we obtained via np.random.rand in the previous code snippet:
In:
rng2 = np.random.RandomState(seed=531)
rng2.rand(3)
Out:
array([0.68980796, 0.35494577, 0.94994208])
Also, the NumPy developer community developed new random number generation method in recent versions of NumPy. For more details, please see the new random Generator documentation:
In:
rng2 = np.random.default_rng(seed=123)
rng2.random(3)
Out:
array([0.68235186, 0.05382102, 0.22035987])
4.7: Reshaping NumPy Arrays
Reshaping Arrays
In practice, we often run into situations where existing arrays do not have the right shape to perform certain computations. As you might remember from the beginning of this article, the size of NumPy arrays is fixed. Fortunately, this does not mean that we have to create new arrays and copy values from the old array to the new one if we want arrays of different shapes – the size is fixed, but the shape is not. NumPy provides a reshape methods that allow us to obtain a view of an array with a different shape.
For example, we can reshape a one-dimensional array into a two-dimensional one using reshape as follows:
In:
ary1d = np.array([1, 2, 3, 4, 5, 6])
ary2d_view = ary1d.reshape(2, 3)
ary2d_view
Out:
array([[1, 2, 3],
[4, 5, 6]])
The True value returned from np.may_share_memory indicates that the reshape operation returns a memory view, not a copy:
In:
np.may_share_memory(ary2d_view, ary1d)
Out:
True
While we need to specify the desired elements along each axis, we need to make sure that the reshaped array has the same number of elements as the original one. However, we do not need to specify the number elements in each axis; NumPy is smart enough to figure out how many elements to put along an axis if only one axis is unspecified (by using the placeholder -1):
In:
ary1d.reshape(-1, 2)
Out:
array([[1, 2],
[3, 4],
[5, 6]])
We can, of course, also use reshape to flatten an array:
In:
ary = np.array([[[1, 2, 3],
[4, 5, 6]]])
ary.reshape(-1)
Out:
array([1, 2, 3, 4, 5, 6])
Other methods for flattening arrays exist, namely flatten, which creates a copy of the array, and ravel, which creates a memory view like reshape:
In:
ary.flatten()
Out:
array([1, 2, 3, 4, 5, 6])
In:
ary.ravel()
Out:
array([1, 2, 3, 4, 5, 6])
Sometimes, we are interested in merging different arrays. Unfortunately, there is no efficient way to do this without creating a new array, since NumPy arrays have a fixed size. While combining arrays should be avoided if possible – for reasons of computational efficiency – it is sometimes necessary. To combine two or more array objects, we can use NumPy’s concatenate function as shown in the following examples:
In:
ary = np.array([1, 2, 3])
# stack along the first axis
np.concatenate((ary, ary))
Out:
array([1, 2, 3, 1, 2, 3])
In:
ary = np.array([[1, 2, 3]])
# stack along the first axis (here: rows)
np.concatenate((ary, ary), axis=0)
Out:
array([[1, 2, 3],
[1, 2, 3]])
In:
# stack along the second axis (here: column)
np.concatenate((ary, ary), axis=1)
Out:
array([[1, 2, 3, 1, 2, 3]])
4.8: NumPy Comparison Operators and Masks
Comparison Operators and Masks
Section 4.5 already briefly introduced the concept of Boolean masks in NumPy. Boolean masks are bool-type arrays (storing True and False values) that have the same shape as a certain target array. For example, consider the following 4-element array below. Using comparison operators (such as <, >, <=, and >=), we can create a Boolean mask of that array which consists of True and False elements depending on whether a condition is met in the target array (here: ary):
In:
ary = np.array([1, 2, 3, 4, 5])
mask = ary > 2
mask
Out:
array([False, False, True, True, True])
One we created such a Boolean mask, we can use it to select certain entries from the target array – those entries that match the condition upon which the mask was created):
In:
ary[mask]
Out:
array([3, 4, 5])
Beyond the selection of elements from an array, Boolean masks can also come in handy when we want to count how many elements in an array meet a certain condition:
In:
mask.sum()
Out:
3
A related, useful function to assign values to specific elements in an array is the np.where function. In the example below, we assign a 1 to all values in the array that are greater than 2 – and 0, otherwise:
In:
ary = np.array([1, 2, 3, 4, 5])
np.where(ary > 2, 1, 0)
Out:
array([0, 0, 1, 1, 1])
There are also so-called bit-wise operators that we can use to specify more complex selection criteria:
In:
ary = np.array([1, 2, 3, 4, 5])
mask = ary > 2
ary[mask] = 1
ary[~mask] = 0
ary
Out:
array([0, 0, 1, 1, 1])
The ~ operator in the example above is one of the logical operators in NumPy:
- A:
&ornp.bitwise_and - Or:
|ornp.bitwise_or - Xor:
^ornp.bitwise_xor - Not:
~ornp.bitwise_not
These logical operators allow us to chain an arbitrary number of conditions to create even more “complex” Boolean masks. For example, using the “Or” operator, we can select all elements that are greater than 3 or smaller than 2 as follows:
In:
ary = np.array([1, 2, 3, 4, 5])
ary[(ary > 3) | (ary < 2)]
Out:
array([1, 4, 5])
And, for example, to negate the condition, we can use the ~ operator:
In:
ary[~((ary > 3) | (ary < 2))]
Out:
array([2, 3])
4.9: Linear Algebra with NumPy
Linear Algebra with NumPy Arrays
Intuitively, we can think of one-dimensional NumPy arrays as data structures that represent row vectors:
In:
row_vector = np.array([1, 2, 3])
row_vector
Out:
array([1, 2, 3])
Similarly, we can use two-dimensional arrays to create column vectors:
In:
column_vector = np.array([1, 2, 3]).reshape(-1, 1)
column_vector
Out:
array([[1],
[2],
[3]])
Instead of reshaping a one-dimensional array into a two-dimensional one, we can simply add a new axis as shown below:
In:
row_vector[:, np.newaxis]
Out:
array([[1],
[2],
[3]])
Note that in this context, np.newaxis behaves like None:
In:
row_vector[:, None]
Out:
array([[1],
[2],
[3]])
All three approaches listed above, using reshape(-1, 1), np.newaxis, or None yield the same results – all three approaches create views not copies of the row_vector array.
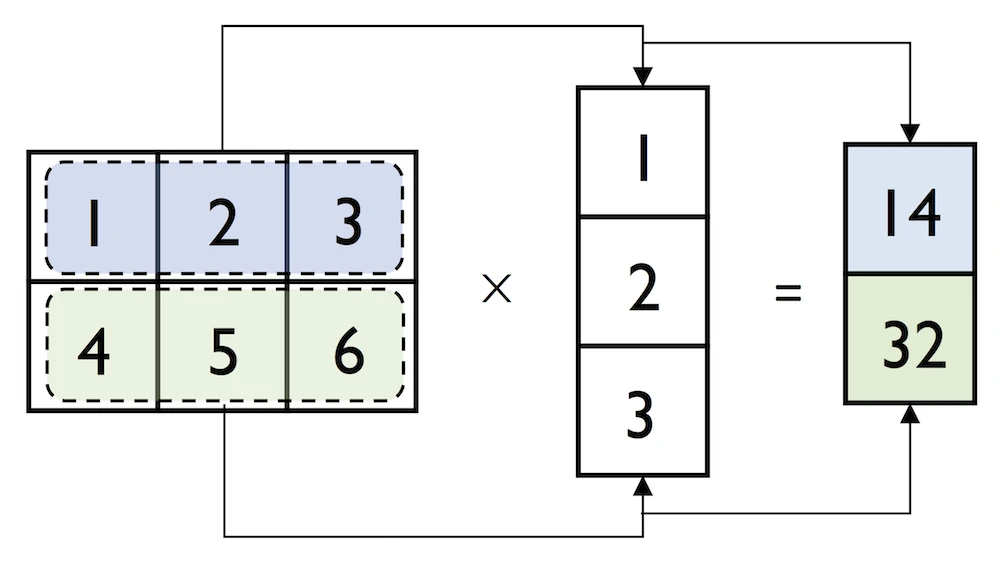
We can think of a column vector as a matrix consisting only of one column. To perform matrix multiplication between matrices, we learned that number of columns of the left matrix must match the number of rows of the matrix to the right. In NumPy, we can perform matrix multiplication via the matmul function:
In:
matrix = np.array([[1, 2, 3],
[4, 5, 6]])
In:
np.matmul(matrix, column_vector)
Out:
array([[14],
[32]])
However, if we are working with matrices and vectors, NumPy can be quite forgiving if the dimensions of matrices and one-dimensional arrays do not match exactly – thanks to broadcasting. The following example yields the same result as the matrix-column vector multiplication, except that it returns a one-dimensional array instead of a two-dimensional one:
In:
np.matmul(matrix, row_vector)
Out:
array([14, 32])
Similarly, we can compute the dot-product between two vectors (here: the vector norm)
In:
np.matmul(row_vector, row_vector)
Out:
14
NumPy has a special dot function that behaves similar to matmul on pairs of one- or two-dimensional arrays – its underlying implementation is different though, and one or the other can be slightly faster on specific machines and versions of BLAS:
In:
np.dot(matrix, row_vector)
Out:
array([14, 32])
Note that an even more convenient way for executing np.dot is using the @ symbol with NumPy arrays:
In:
matrix @ row_vector
Out:
array([14, 32])
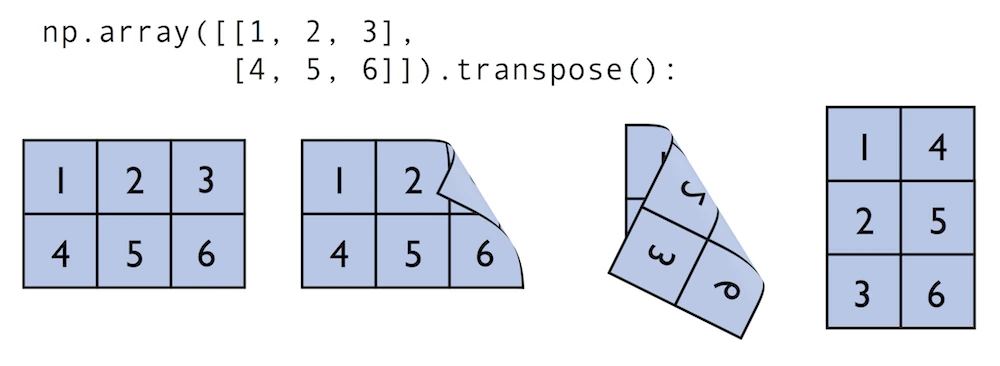
Similar to the examples above we can use matmul or dot to multiply two matrices (here: two-dimensional arrays). In this context, NumPy arrays have a handy transpose method to transpose matrices if necessary:
In:
matrix = np.array([[1, 2, 3],
[4, 5, 6]])
matrix.transpose()
Out:
array([[1, 4],
[2, 5],
[3, 6]])
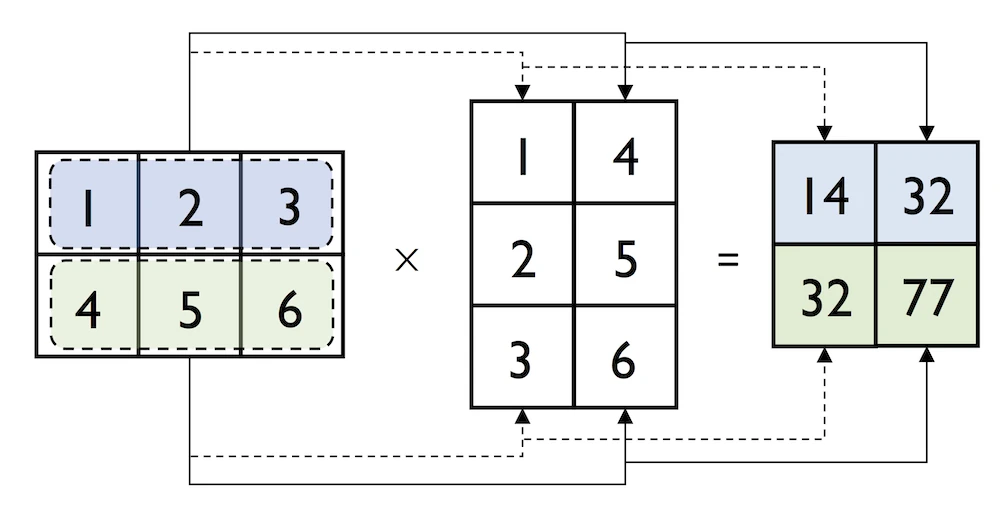
In:
np.dot(matrix, matrix.transpose())
Out:
array([[14, 32],
[32, 77]])
While transpose can be annoyingly verbose for implementing linear algebra operations – think of PEP8’s 80 character per line recommendation – NumPy has a shorthand for that: T:
In:
matrix.T
Out:
array([[1, 4],
[2, 5],
[3, 6]])
While this section demonstrates some of the basic linear algebra operations carried out on NumPy arrays that we use in practice, you can find an additional function in the documentation of NumPy’s submodule for linear algebra: numpy.linalg. If you want to perform a particular linear algebra routine that is not implemented in NumPy, it is also worth consulting the scipy.linalg documentation – SciPy is a library for scientific computing built on top of NumPy.
I want to mention that there is also a special matrix type in NumPy. NumPy matrix objects are analogous to NumPy arrays but are restricted to two dimensions. Also, matrices define certain operations differently than arrays; for instance, the * operator performs matrix multiplication instead of element-wise multiplication. However, NumPy matrix is less popular in the science community compared to the more general array data structure.
SciPy
SciPy is another open-source library from Python’s scientific computing stack. SciPy includes submodules for integration, optimization, and many other kinds of computations that are out of the scope of NumPy itself. We will not cover SciPy as a library here, since it can be more considered as an “add-on” library on top of NumPy.
I recommend you to take a look at the SciPy documentation to get a brief overview of the different function that exists within this library: https://docs.scipy.org/doc/scipy/reference/
4.10: Matplotlib
What is Matplotlib?
Lastly, we will briefly cover Matplotlib in this article. Matplotlib is a plotting library for Python created by John D. Hunter in 2003. Unfortunately, John D. Hunter became ill and past away in 2012. However, Matplot is still the most mature plotting library, and is being maintained until this day.
In general, Matplotlib is a rather “low-level” plotting library, which means that it has a lot of room for customization. The advantage of Matplotlib is that it is so customizable; the disadvantage of Matplotlib is that it is so customizable – some people find it a little bit too verbose due to all the different options.
In any case, Matplotlib is among the most widely used plotting library and the go-to choice for many data scientists and machine learning researchers and practictioners.
In my opinion, the best way to work with Matplotlib is to use the Matplotlib gallery on the official website at https://matplotlib.org/gallery/index.html often. It contains code examples for creating various different kinds of plots, which are useful as templates for creating your own plots. Also, if you are completely new to Matplotlib, I recommend the tutorials at https://matplotlib.org/tutorials/index.html.
In this section, we will look at a few very simple examples, which should be very intuitive and shouldn’t require much explanation.
In:
%matplotlib inline
import matplotlib.pyplot as plt
The main plotting functions of Matplotlib are contained in the pyplot module, which we imported above. Note that the %matplotlib inline command is an “IPython magic” command. This particular %matplotlib inline is specific to Jupyter notebooks (which, in our case, use an IPython kernel) to show the plots “inline,” that is, the notebook itself.
Plotting Functions and Lines
In:
x = np.linspace(0, 10, 100)
plt.plot(x, np.sin(x))
plt.show()
Out:
Add axis ranges and labels:
In:
x = np.linspace(0, 10, 100)
plt.plot(x, np.sin(x))
plt.xlim([2, 8])
plt.ylim([0, 0.75])
plt.xlabel('x-axis')
plt.ylabel('y-axis')
plt.show()
Out:
In:
x = np.linspace(0, 10, 10)
plt.plot(x, np.sin(x), label=('sin(x)'), linestyle='', marker='o')
plt.ylabel('f(x)')
plt.xlabel('x')
plt.legend(loc='lower left')
plt.show()
Out:
Scatter Plots
In:
rng = np.random.RandomState(123)
x = rng.normal(size=500)
y = rng.normal(size=500)
plt.scatter(x, y)
plt.show()
Out:
Bar Plots
In:
# input data
means = [5, 8, 10]
stddevs = [0.2, 0.4, 0.5]
bar_labels = ['bar 1', 'bar 2', 'bar 3']
# plot bars
x_pos = list(range(len(bar_labels)))
plt.bar(x_pos, means, yerr=stddevs)
plt.show()
Out:
Histograms
In:
rng = np.random.RandomState(123)
x = rng.normal(0, 20, 1000)
# fixed bin size
bins = np.arange(-100, 100, 5) # fixed bin size
plt.hist(x, bins=bins)
plt.show()
Out:
In:
rng = np.random.RandomState(123)
x1 = rng.normal(0, 20, 1000)
x2 = rng.normal(15, 10, 1000)
# fixed bin size
bins = np.arange(-100, 100, 5) # fixed bin size
plt.hist(x1, bins=bins, alpha=0.5)
plt.hist(x2, bins=bins, alpha=0.5)
plt.show()
Out:
Subplots
In:
x = range(11)
y = range(11)
fig, ax = plt.subplots(nrows=2, ncols=3,
sharex=True, sharey=True)
for row in ax:
for col in row:
col.plot(x, y)
plt.show()
Out:
Colors and Markers
In:
x = np.linspace(0, 10, 100)
plt.plot(x, np.sin(x),
color='blue',
marker='^',
linestyle='')
plt.show()
Out:
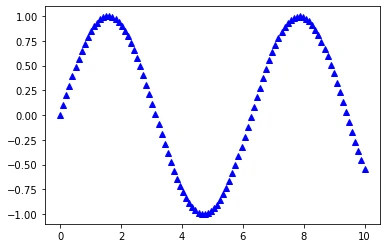
Saving Plots
The file format for saving plots can be conveniently specified via the file suffix (.eps, .svg, .jpg, .png, .pdf, .tiff, etc.). Personally, I recommend using a vector graphics format (.eps, .svg, .pdf) whenever you can, which usually results in smaller file sizes than bitmap graphics (.jpg, .png, .bmp, tiff) and does not have a limited resolution.
In:
x = np.linspace(0, 10, 100)
plt.plot(x, np.sin(x))
plt.savefig('myplot.png', dpi=300)
plt.savefig('myplot.pdf')
plt.show()
Out:
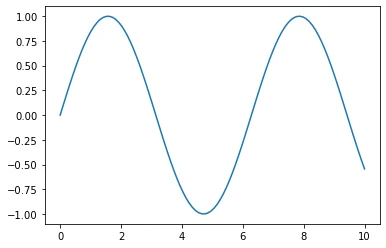
Thank you for reading/watching. If you liked this content, you can also find me on Twitter, where I share more helpful content.
Resources
NumPy and Matplotlib reference material:
NumPy books, tutorials, and papers:
- Rougier, N.P., 2016. From Python to NumPy.
- Oliphant, T.E., 2015. A Guide to NumPy: 2nd Edition. USA: Travis Oliphant, independent publishing.
- Varoquaux, G., Gouillart, E., Vahtras, O., Haenel, V., Rougier, N.P., Gommers, R., Pedregosa, F., Jędrzejewski-Szmek, Z., Virtanen, P., Combelles, C. and Pinte, D., 2015. SciPy Lecture Notes.
- Harris, C.R., Millman, K.J., van der Walt, S.J. et al. Array Programming with NumPy. Nature 585, 357–362 (2020).
Read Next
 Model evaluation, model selection, and algorithm selection in machine learning
Part 4 of the model evaluation series explaining statistical tests, algorithm comparisons, corrected resampled tests, and nested cross-validation.
Model evaluation, model selection, and algorithm selection in machine learning
Part 4 of the model evaluation series explaining statistical tests, algorithm comparisons, corrected resampled tests, and nested cross-validation.
 Generating Gender-Neutral Face Images with Semi-Adversarial Neural Networks to Enhance Privacy
I thought that it would be nice to have short and concise summaries of recent projects handy, to share them with a more general audience, including...
Generating Gender-Neutral Face Images with Semi-Adversarial Neural Networks to Enhance Privacy
I thought that it would be nice to have short and concise summaries of recent projects handy, to share them with a more general audience, including...
 Model evaluation, model selection, and algorithm selection in machine learning
Part 3 of the model evaluation series covering hyperparameter tuning, model selection, validation sets, k-fold cross-validation, and nested workflows.
Model evaluation, model selection, and algorithm selection in machine learning
Part 3 of the model evaluation series covering hyperparameter tuning, model selection, validation sets, k-fold cross-validation, and nested workflows.

If you read the book and have a few minutes to spare, I'd really appreciate a brief review. It helps us authors a lot!
Your support means a great deal! Thank you!