Gated Attention
Gated Attention keeps standard content-based attention in the stack, but wraps it in a few stability and output gating tweaks that make it fit better into hybrid long-context models.
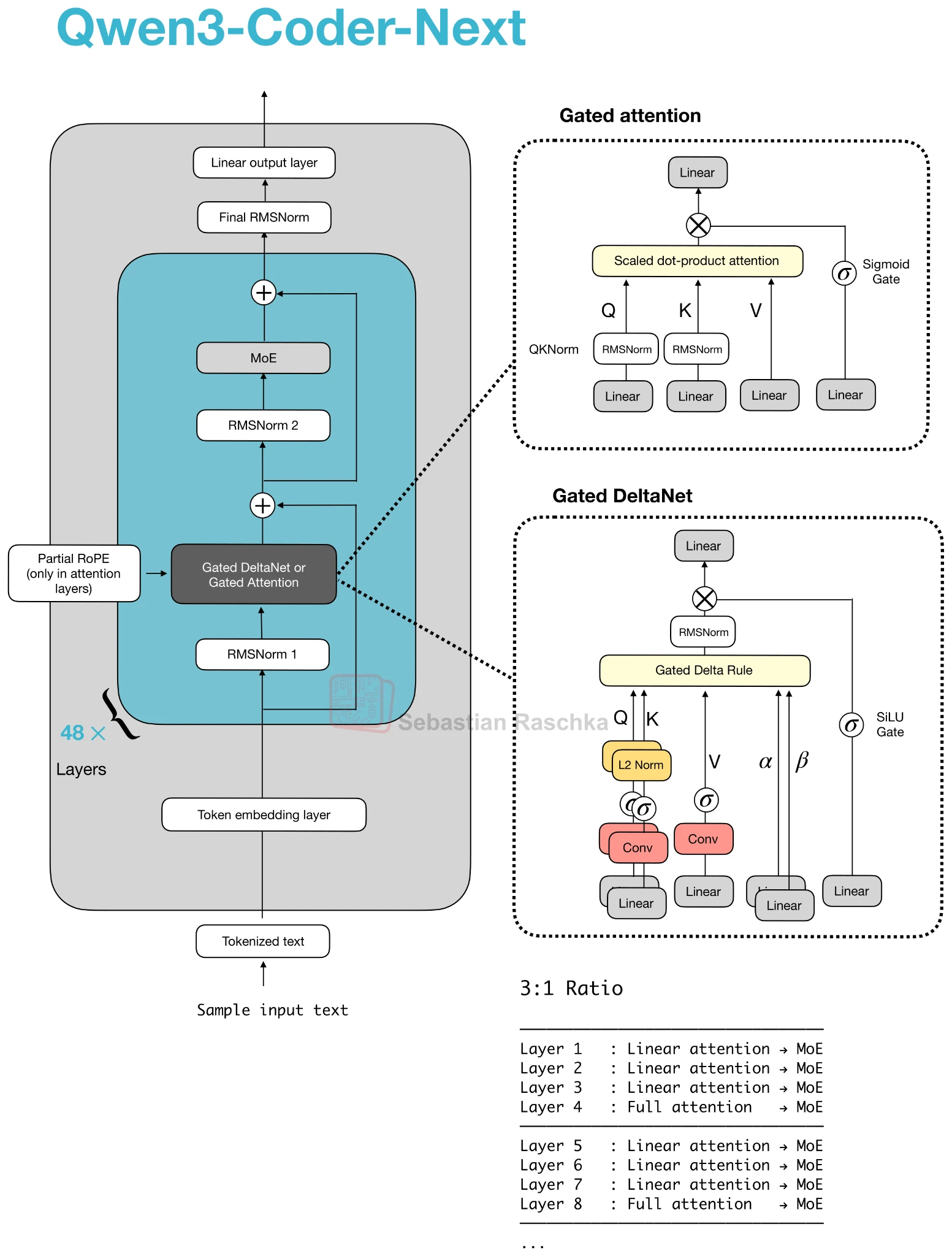
In the Qwen3-Next family, this is the “full attention” side of the hybrid. Most layers use Gated DeltaNet for efficiency, and every few layers one Gated Attention block remains to preserve the precise content retrieval that linear-attention substitutes still struggle to match.
Why It Exists
Pure linear-attention replacements are attractive because they remove the quadratic scaling of ordinary attention. The problem is that they usually make a stronger compromise on exact content retrieval. Gated Attention exists because recent hybrid stacks do not want to give up that capability completely.
So the design pattern is not “replace attention everywhere.” It is “replace most attention layers, but keep a smaller number of stronger attention blocks around.”
What Changes Relative To Plain GQA
The useful mental model is that Gated Attention is still a dot-product attention block, often close to GQA, but with a few extra stabilizers on top. In the Qwen3-Next discussion, the important details were an output gate, a zero-centered QK-Norm variant, and partial RoPE rather than plain full-dimension rotary embeddings.
That means Gated Attention is not a new asymptotic complexity class. It is a tuned attention block designed to work well alongside more aggressive efficiency layers.
Why Hybrid Stacks Keep One Attention Layer
DeltaNet-style layers compress history into a state, which is efficient but less expressive than direct attention. By inserting one Gated Attention block every few layers, the model periodically regains full content-based mixing. That is why the 3:1 pattern keeps appearing in architecture figures.
The best way to think about Gated Attention today is as the anchor block that keeps the hybrid grounded in transformer behavior.
How To Read It In The Gallery
On the gallery page, Gated Attention mainly appears in Qwen3-Next, Qwen3-Coder-Next, and Qwen3.5 cards. If a card says something like 3:1 Gated DeltaNet and Gated Attention, it means attention has not disappeared. It has just been reduced to the minority block in the stack.