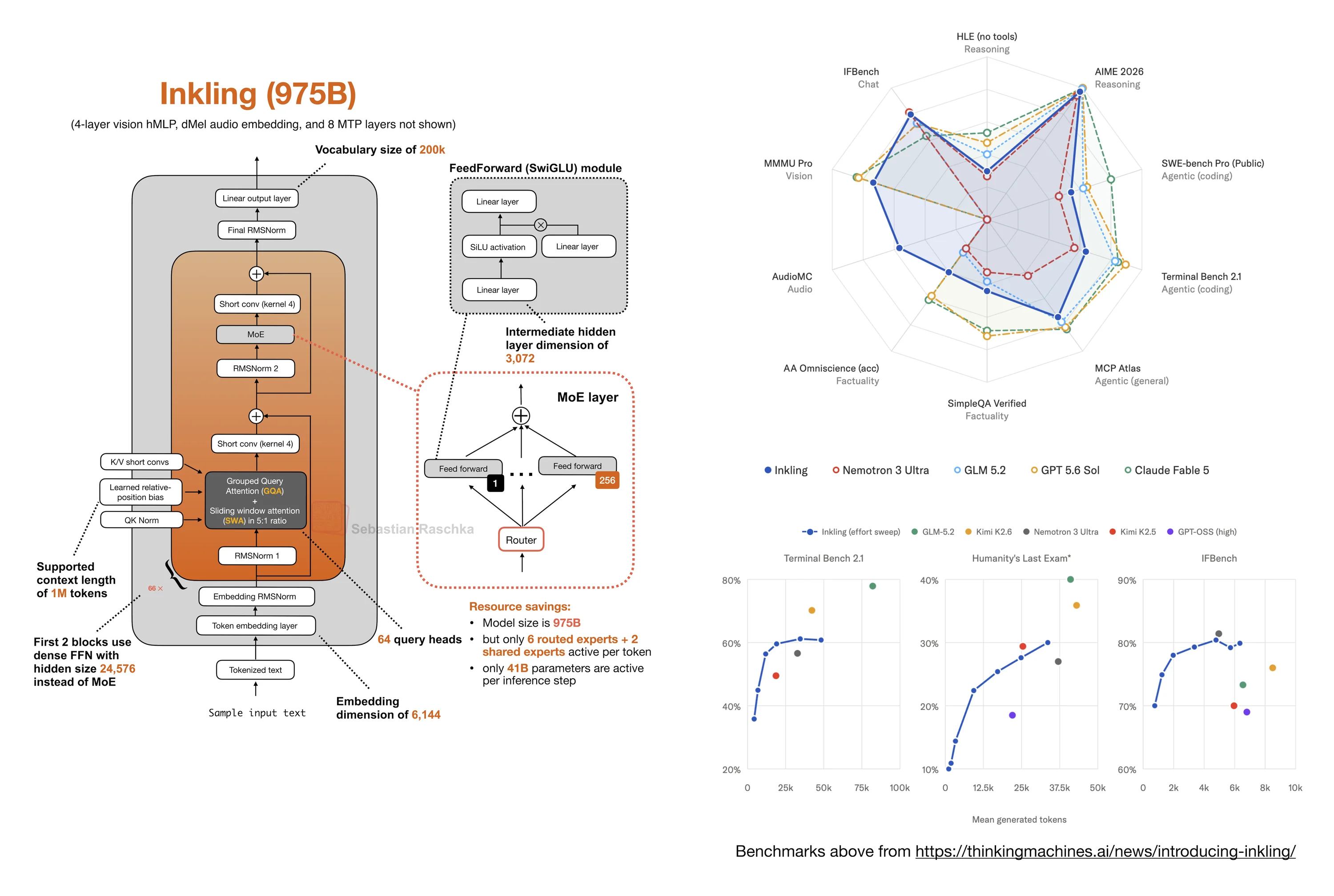
Nemotron 3 Ultra and Latent MoE Scaling
A good week for open-weight LLMs. Several nice models now run locally, and even Gemma 4 12B needs less than 16 GB of RAM.
Nemotron 3 Ultra is too large for that category, but it is interesting from a performance-efficiency perspective. At a high level, it is the large sibling of Nemotron 3 Super. The overall design is still a hybrid Mamba-Transformer MoE stack, but scaled to 550B total parameters with 55B active per token.
The part I find most interesting is the Latent MoE idea introduced in Nemotron 3 Super.
In a regular MoE layer, the routed experts operate directly at the model width. In Latent MoE, the routed path is first projected down into a smaller latent space, the experts operate there, and the result is projected back up.
For Super, this was 4096 -> 1024 -> 4096. For Ultra, it is 8192 -> 2048 -> 8192.
So the 4x compression ratio stays the same, but the model is scaled up substantially. This is a nice example of architecture scaling by combining several efficiency mechanisms: Mamba-2, GQA, Latent MoE, and MTP.
The LLM Architecture Gallery card has the higher-resolution architecture figure and the detailed configuration summary. NVIDIA’s technical report has the full model and training details.
As usual, benchmark snapshots should be read as date-sensitive. The Artificial Analysis numbers in the figure are useful as a June 4, 2026 reference point, but leaderboard positions can move quickly as providers update inference stacks, quantization, and serving settings.
Source: lightly edited website version of my Substack note.