Nemotron 3 Super Throughput Notes
NVIDIA’s Nemotron 3 Super 120B-A12B is a nice open-weight release because the design is very explicitly aimed at the accuracy-throughput trade-off.
Based on the technical report, model config, and my local architecture card, the 120B total and 12B active model combines several efficiency choices:
- Mamba-2 layers for throughput and long-context efficiency
- Latent MoE layers for sparse scaling at lower inference cost
- Shared-weight multi-token prediction for native speculative decoding
- A small number of GQA layers mixed into the hybrid stack
As of March 2026, the reported benchmark profile looks roughly competitive with GPT-OSS 120B and Qwen3.5 models of similar active scale, while the throughput numbers look stronger. I would treat the exact benchmark ordering as date-sensitive, but the architecture point is more durable. Nemotron 3 Super spends a lot of design effort on reducing latency and cost rather than only pushing raw score.
That makes it a relevant model to watch for local agentic applications, where throughput and cost often matter as much as peak benchmark numbers.
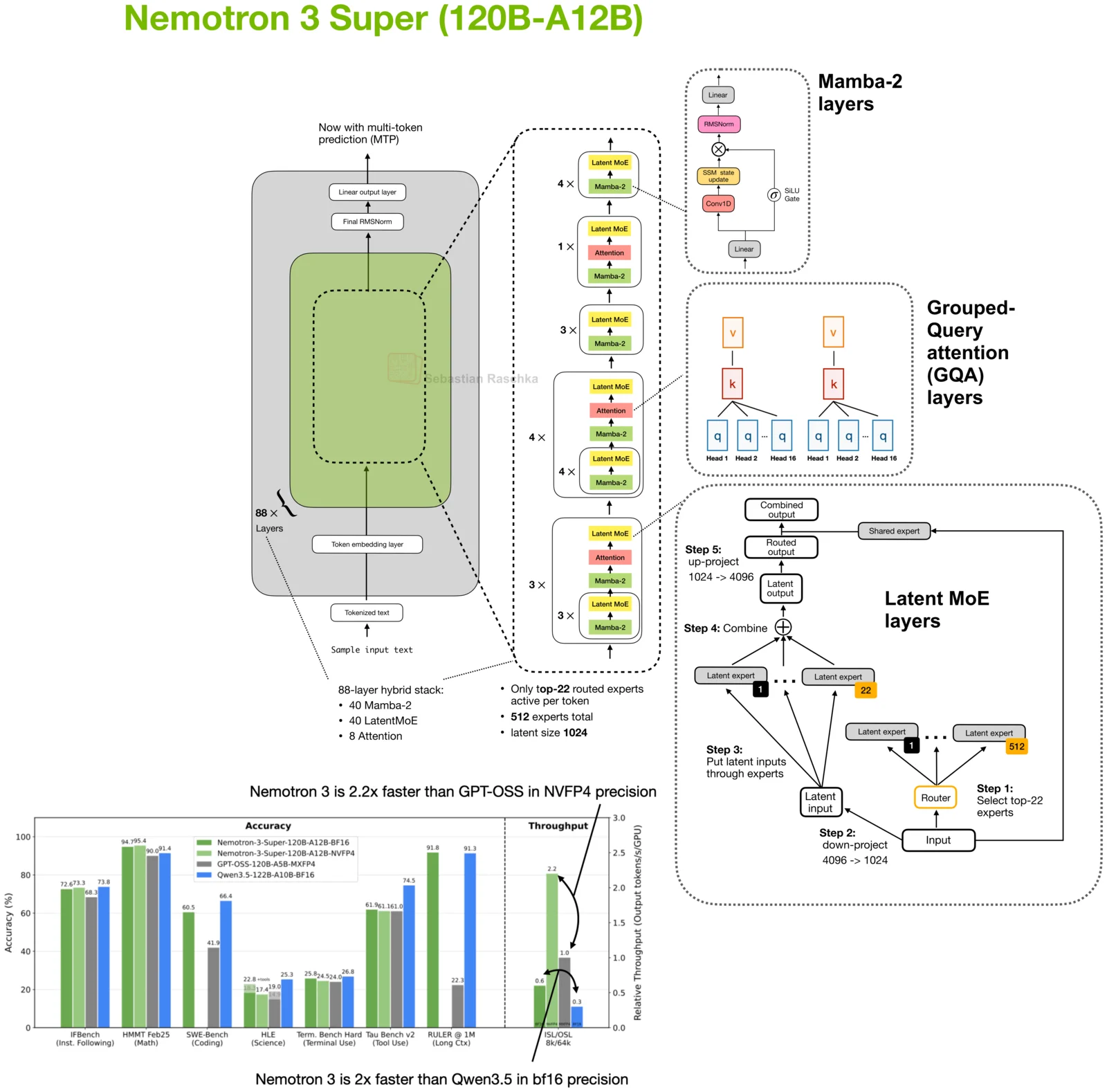
Source: lightly edited website version of my Substack note.
Read Next
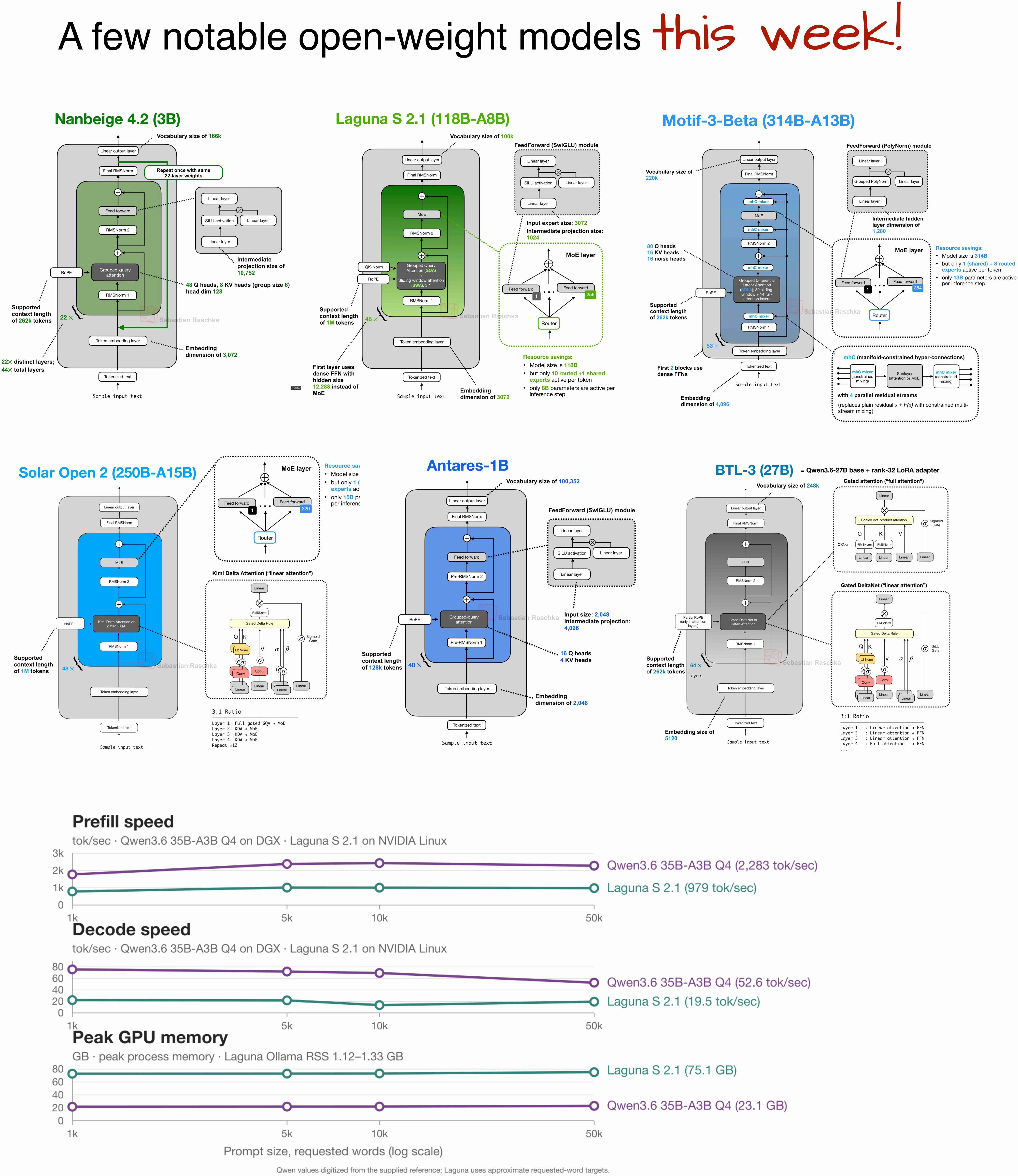 A Few Notable Open-Weight Models This Week
Short note on the architectures of six new open-weight models, including Nanbeige 4.2, Laguna S 2.1, Motif-3-Beta, Solar Open 2, Antares 1B, and BTL-3.
A Few Notable Open-Weight Models This Week
Short note on the architectures of six new open-weight models, including Nanbeige 4.2, Laguna S 2.1, Motif-3-Beta, Solar Open 2, Antares 1B, and BTL-3.
 Correction for Listing 6.5 in Build a Reasoning Model From Scratch
Short correction note for the random seed in Listing 6.5 on page 198 of Build a Reasoning Model From Scratch.
Correction for Listing 6.5 in Build a Reasoning Model From Scratch
Short correction note for the random seed in Listing 6.5 on page 198 of Build a Reasoning Model From Scratch.
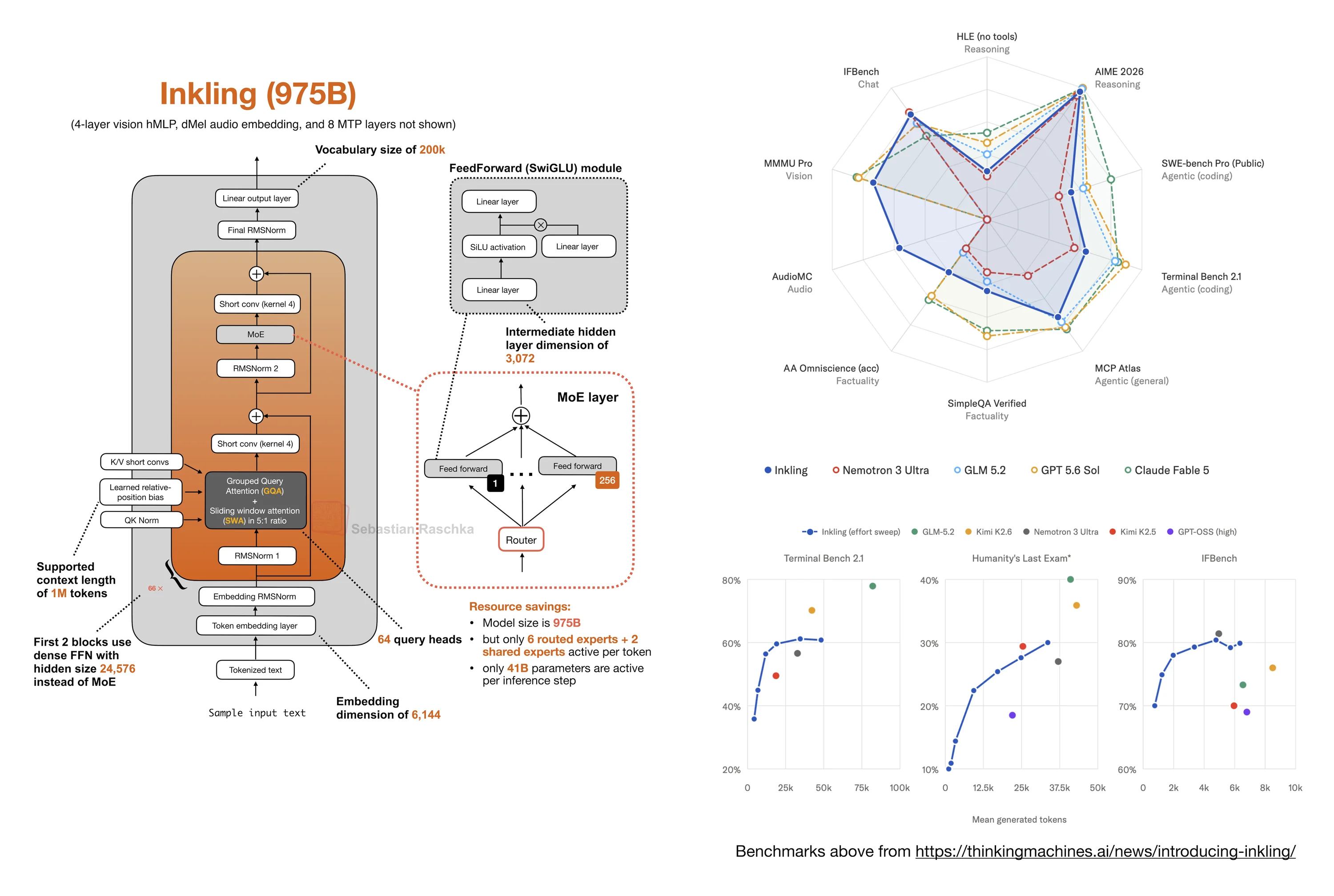 Inkling: A New Open-Weight 975B MoE with a Few Surprises
Short note on Thinking Machines Lab's 975B Inkling model, including benchmarks, sparse MoE design, short convolutions, RMSNorm, and position bias.
Inkling: A New Open-Weight 975B MoE with a Few Surprises
Short note on Thinking Machines Lab's 975B Inkling model, including benchmarks, sparse MoE design, short convolutions, RMSNorm, and position bias.