MiniMax M2 and Production-Oriented Model Design
The MiniMax M2 series was one of the most widely used open-weight LLM series earlier this year. The technical report has several interesting details that are worth highlighting.
The paper frames the flagship M2 model as a sparse MoE with 229.9B total parameters and 9.8B active parameters per token. In the local architecture gallery, this corresponds to the MiniMax M2, MiniMax M2.5, and MiniMax M2.7 cards.
The parts I found most interesting:
- Full attention as an anti-trend. They tried hybrid sliding-window attention variants, similar to what many other recent models use. Even though there were efficiency gains, the production-quality tradeoffs were apparently not worth it for M2.
- Linear and sparse attention deployment issues. These attention variants reduce long-context attention cost on paper, but the report says they were harder to make work well in a production agent system. Two practical issues were lower-precision KV-like state and weaker prefix caching support, which matters a lot for coding agents that reuse large chunks of context.
- Fine-grained MoE still helps. The report includes a useful MoE ablation at the 2B-active scale. A baseline with 32 experts and top-2 routing is compared with a fine-grained setup with 128 experts and top-8 routing. The fine-grained setup improves MATH from 19.6 to 24.1 and HumanEval from 29.7 to 32.5.
- Agent training pipelines are now a major component. The report describes mining GitHub pull requests, building runnable Docker environments, extracting task-specific test rewards, and turning software-engineering tasks into verifiable training trajectories.
- Interleaved thinking matters for context management. Removing reasoning blocks from previous turns hurt performance, especially in multi-step agent tasks. This is another reason why long-context support is so important for agent workloads.
- Speed rewards are part of the RL design. Token penalties are common, but MiniMax also adds a task-completion-time reward based on wall-clock time. The goal is to reduce unnecessary slow tool calls. If the harness supports it, this may also encourage more parallel agent behavior.
- Self-evolution is already part of the loop. The report says M2.7 handles 30 to 50 percent of the daily RL iteration workload, modifies its own scaffold, and completed a 100-round autonomous scaffold optimization cycle with a 30 percent gain on internal evaluations.
As usual, I would treat the benchmark and internal-evaluation numbers as a May 2026 snapshot. The broader takeaway is more durable: production constraints such as prefix caching, tool latency, executable environments, and scaffold iteration are becoming first-class model-design inputs.

Source: lightly edited website version of my Substack note.
Read Next
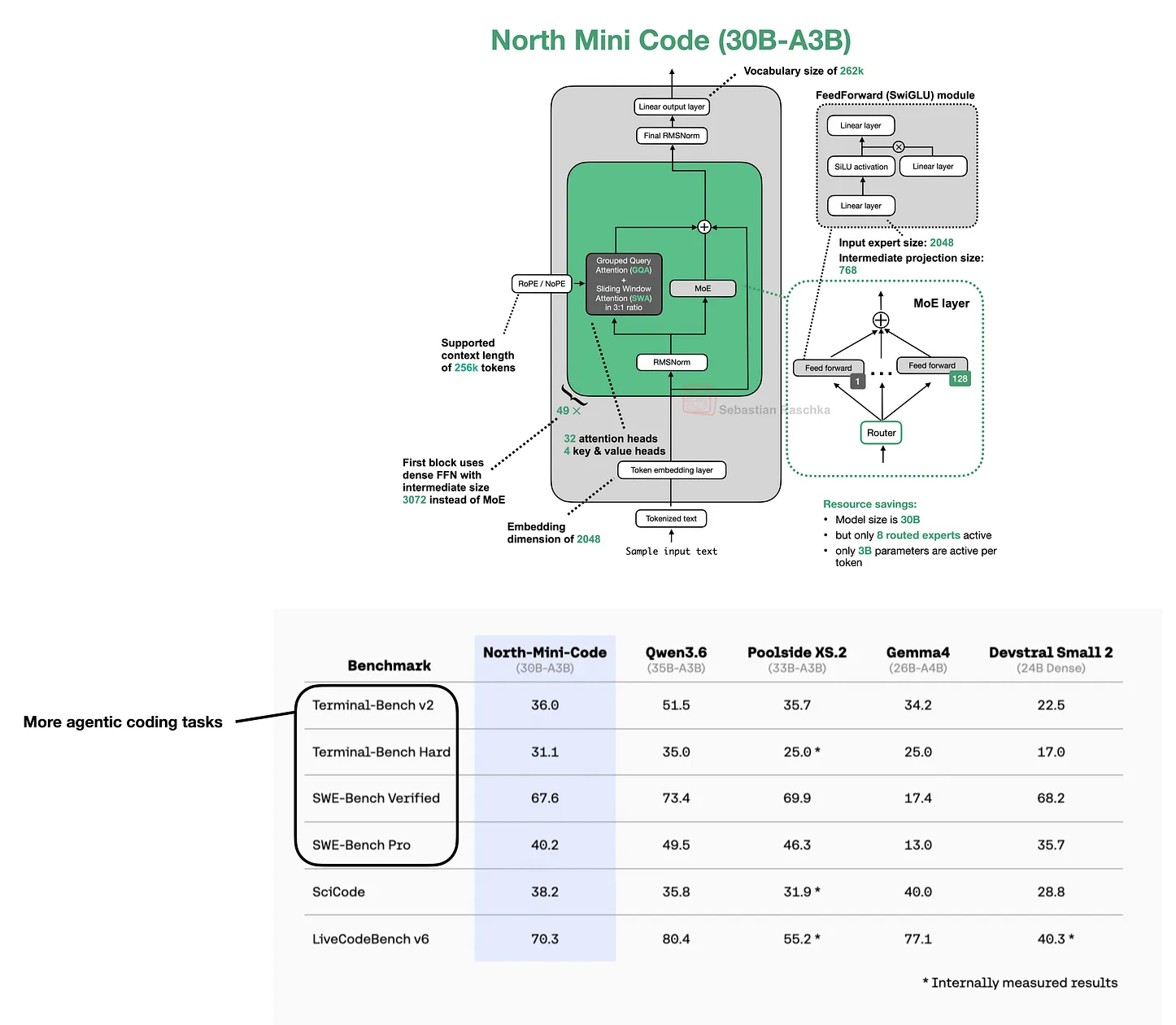 North Mini Code and Agentic Coding Benchmarks
Compare another model release focused on agentic coding workflows.
North Mini Code and Agentic Coding Benchmarks
Compare another model release focused on agentic coding workflows.
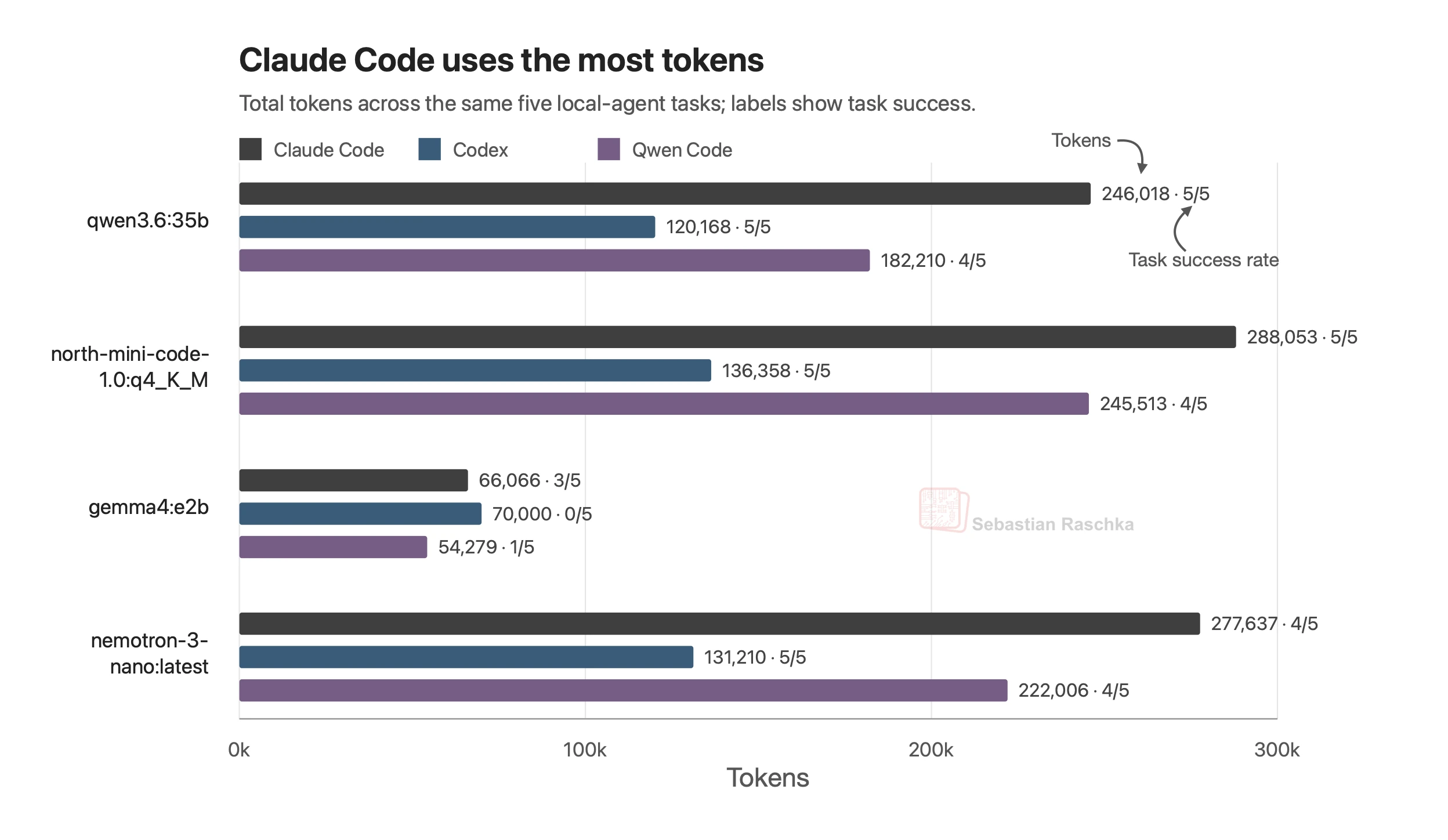 Local Open-Weight LLMs in Coding Harnesses
See local harness results for open-weight coding models.
Local Open-Weight LLMs in Coding Harnesses
See local harness results for open-weight coding models.
 Components of a Coding Agent
Review why tool loops and harness design matter for coding-agent models.
Components of a Coding Agent
Review why tool loops and harness design matter for coding-agent models.