Local Open-Weight LLMs in Coding Harnesses
I have been taking different local open-weight LLMs for a test drive in different harnesses (Qwen-Code, Codex, Claude Code).
30B Mixture-of-Experts models are kind of a nice sweet spot and can solve challenging problems. And they get roughly 40 tok/sec on a Mac or DGX Spark, which is similar to GPT 5.5 in a Pro subscription and totally usable for everyday work.
More interesting is also the harness choice! Claude Code seems to be using 2x as many tokens as Codex.
Gemma 4 E2B is here just for reference to show that the tasks can’t be trivially solved by smaller models.
The longer write-up is now available at Using Local Coding Agents.
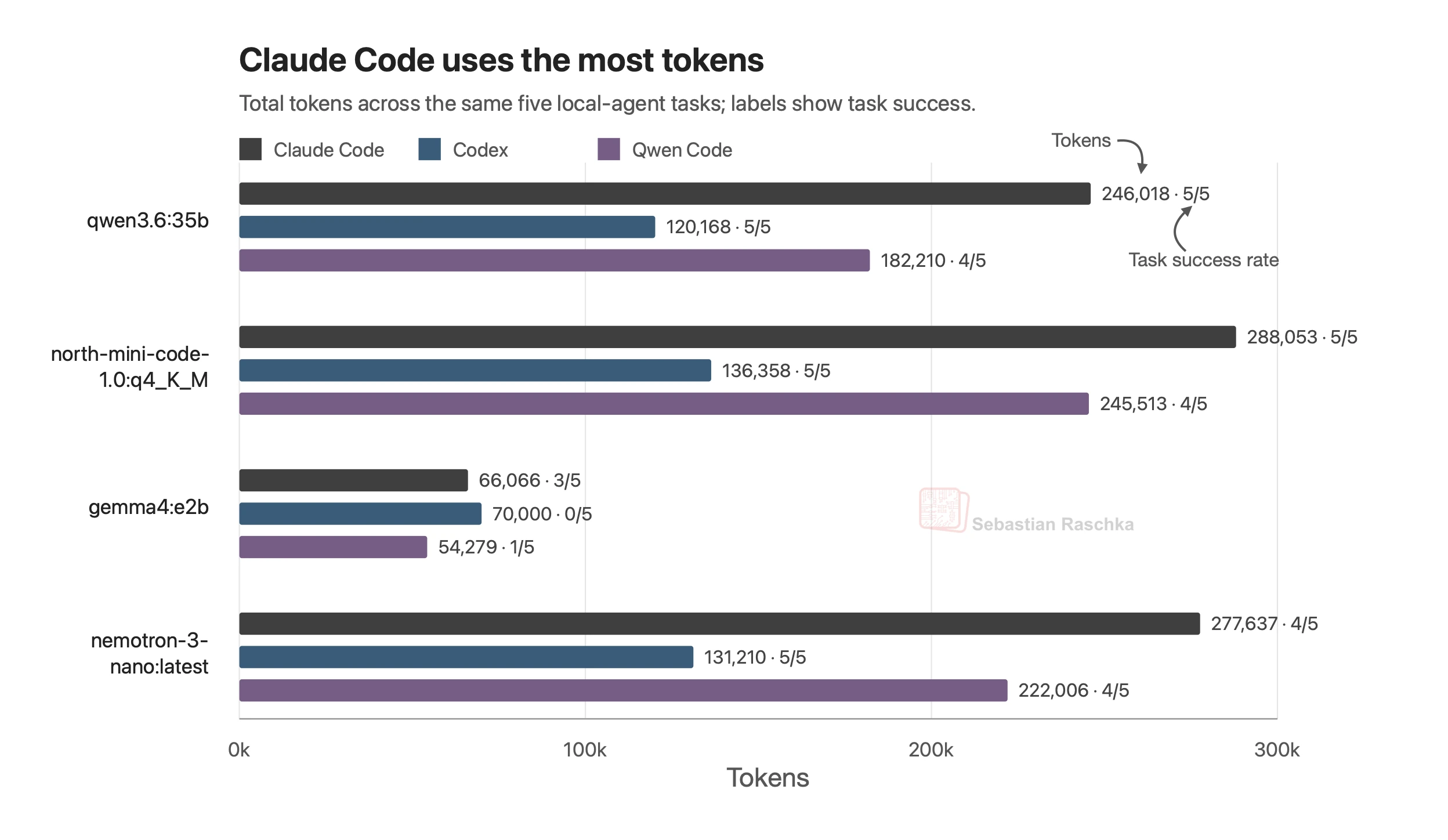
Source: lightly edited website version of my Substack note.
Read Next
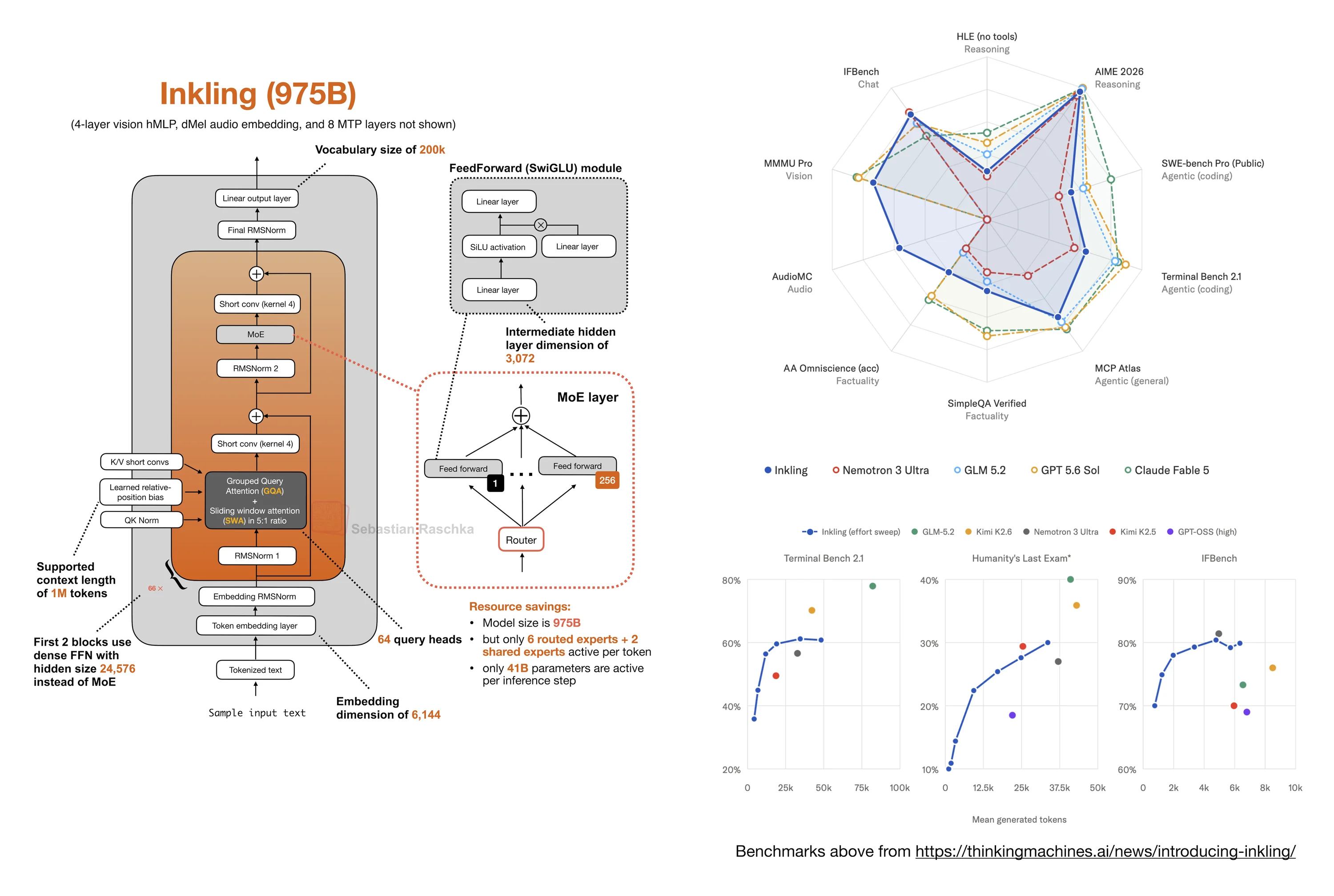 Inkling: A New Open-Weight 975B MoE with a Few Surprises
Short note on Thinking Machines Lab's 975B Inkling open-weight model, its benchmark profile, sparse MoE design, short convolutions, embedding RMSNorm, and
Inkling: A New Open-Weight 975B MoE with a Few Surprises
Short note on Thinking Machines Lab's 975B Inkling open-weight model, its benchmark profile, sparse MoE design, short convolutions, embedding RMSNorm, and
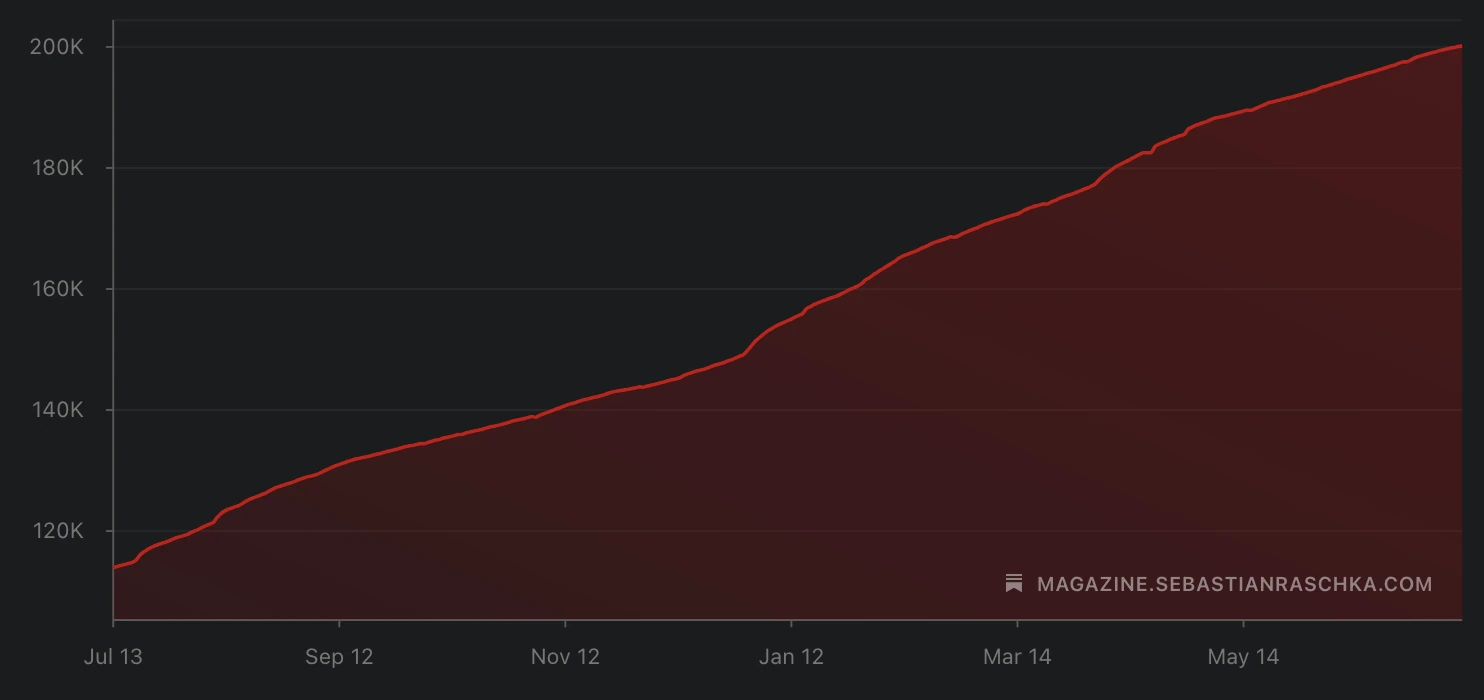 200,000 Subscribers
Short note celebrating Ahead of AI reaching 200,000 subscribers.
200,000 Subscribers
Short note celebrating Ahead of AI reaching 200,000 subscribers.
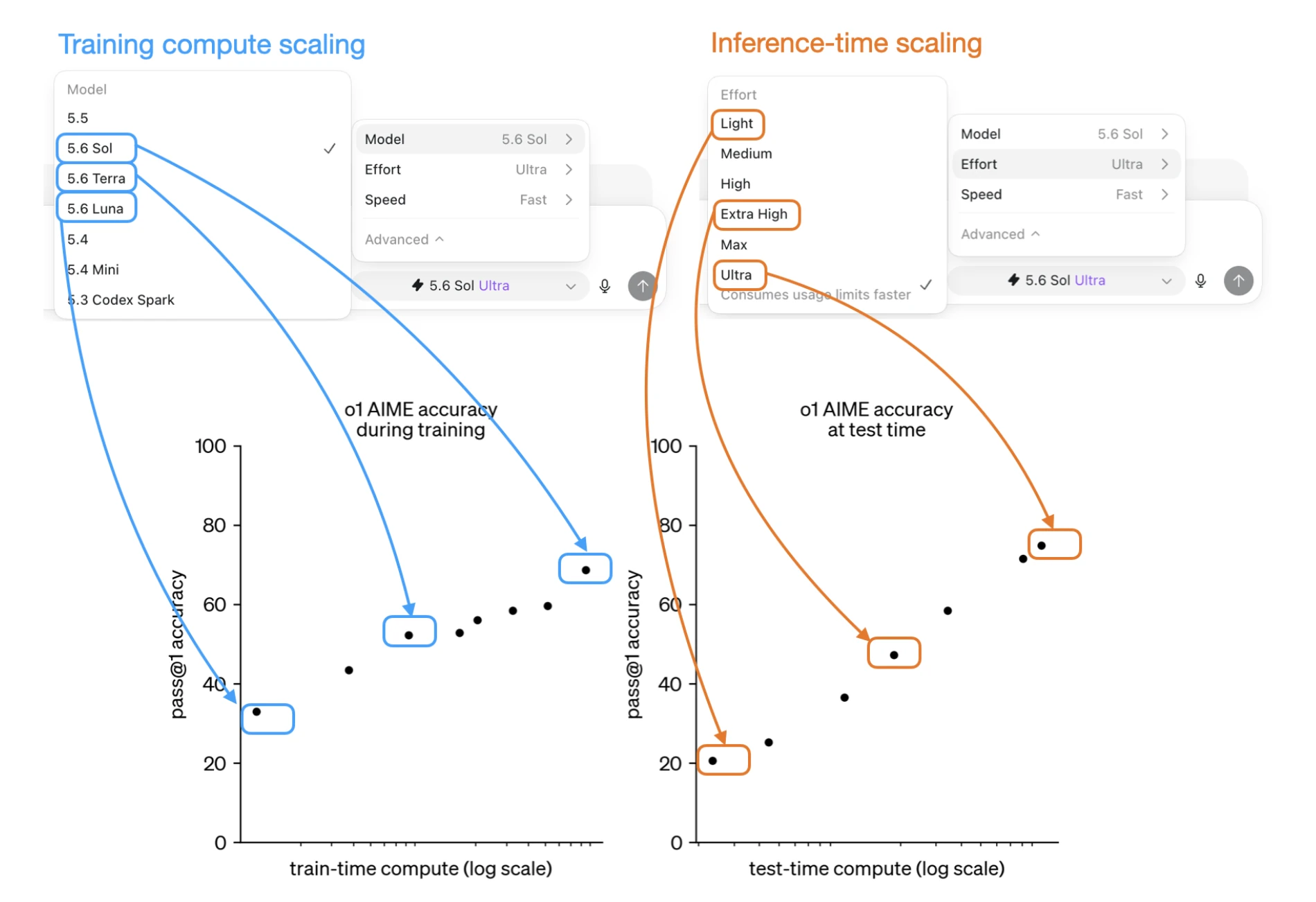 GPT 5.6 Has 72 Possible Configurations. What's A Good Default?
Short note on how GPT 5.6 model and effort choices map onto training-time and inference-time scaling, producing 72 configurations.
GPT 5.6 Has 72 Possible Configurations. What's A Good Default?
Short note on how GPT 5.6 model and effort choices map onto training-time and inference-time scaling, producing 72 configurations.