Per-Layer Embeddings (PLE)
Per-layer embeddings (PLE) are an extra embedding path used in the Gemma 4 E2B and E4B models. They give each transformer block a small token-specific vector without scaling the full attention and feed-forward stack to the larger parameter count.
This is separate from cross-layer KV sharing. KV sharing reduces cache growth during inference. PLE is about parameter efficiency. It adds representational capacity through embedding tables and small projections while keeping the main transformer compute closer to the smaller effective model size.
What changes
Each transformer layer receives its own small token-specific embedding slice
Practical benefit
It adds parameter capacity while keeping the main transformer compute closer to the effective size
Example architectures
Effective Size
The “E” in Gemma 4 E2B and E4B stands for “effective”. Gemma 4 E2B is listed as 2.3B effective parameters and 5.1B total parameters when embeddings are counted. Gemma 4 E4B is listed as 4.5B effective parameters and 8B total parameters with embeddings.
The useful interpretation is that the main transformer-stack compute is closer to the smaller number. The larger number includes additional embedding-table parameters. Those parameters still matter for capacity, but they are cheaper than making every attention and feed-forward block wider or deeper.
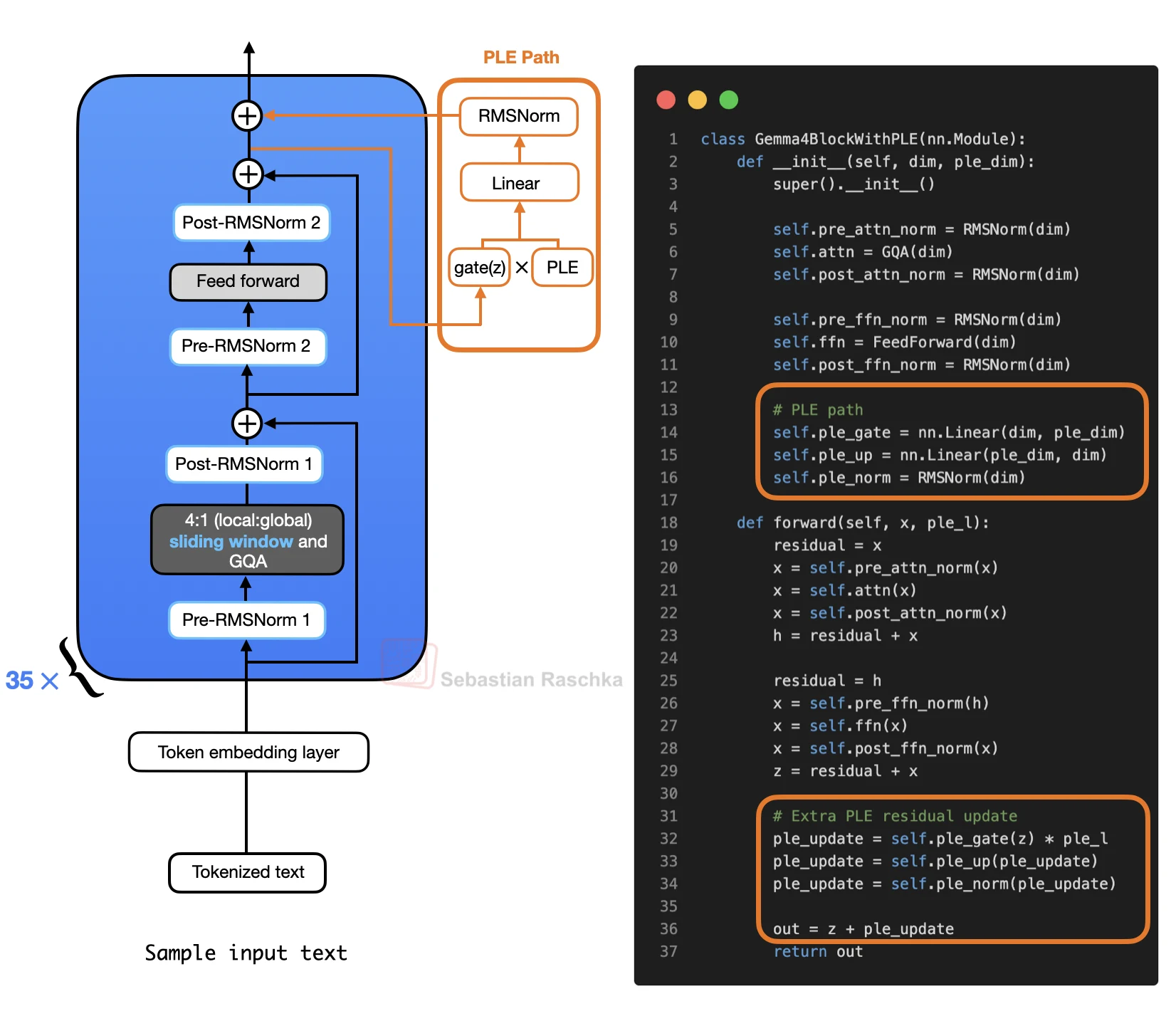
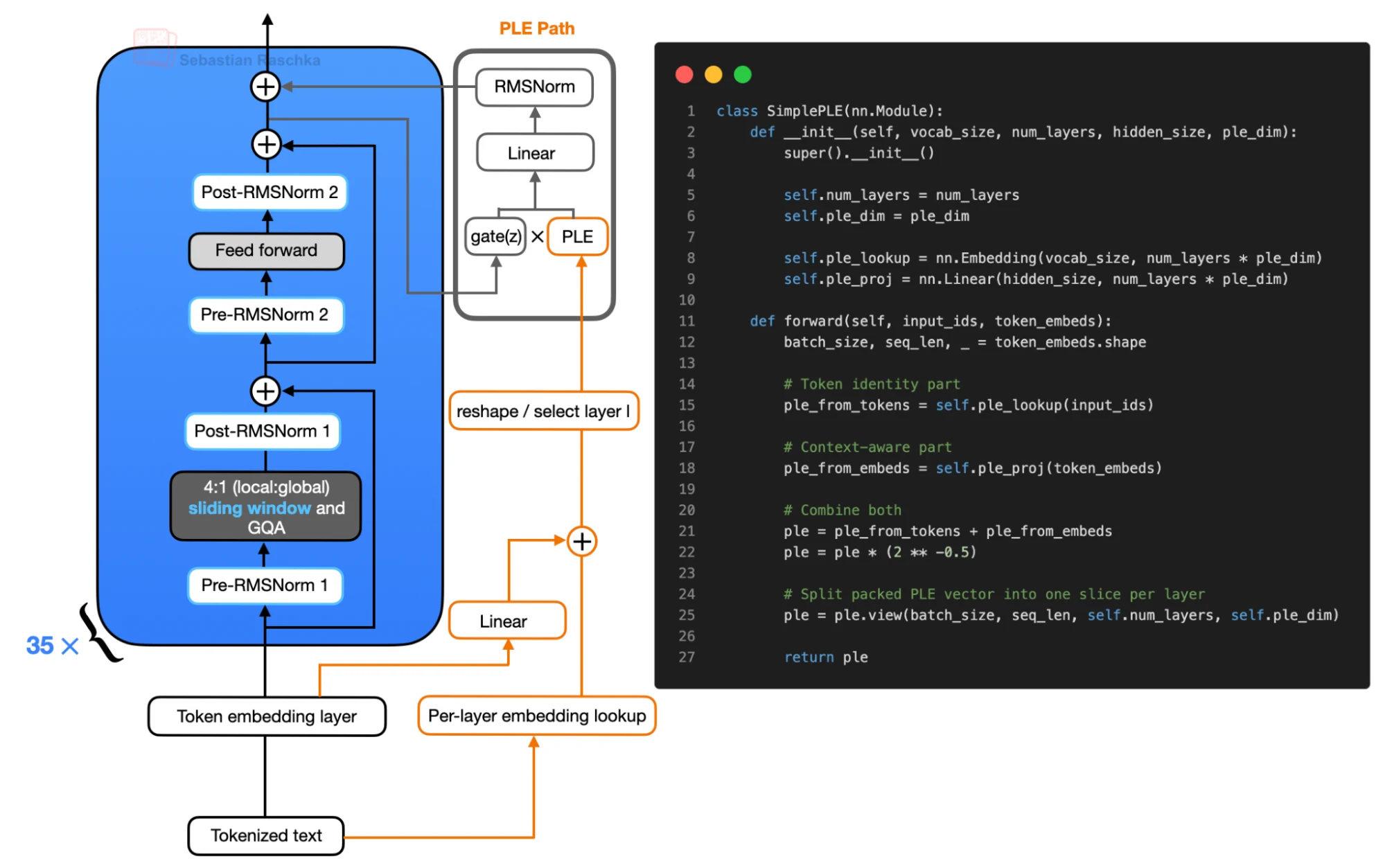
How The PLE Path Works
In simplified form, Gemma 4 prepares a packed PLE tensor before the repeated transformer blocks. It uses two ingredients:
- token IDs that go through a per-layer embedding lookup
- normal token embeddings that are projected into the same packed PLE space
These two pieces are added, scaled, and reshaped so that there is one small slice per transformer layer. During the forward pass, layer l receives only its own slice.
Inside the block, the normal attention branch and feed-forward branch run first. After the feed-forward residual update, the hidden state gates the layer-specific PLE vector. That gated vector is projected back to the model hidden size, normalized, and added as another residual update.
So the transformer block still has the usual attention and feed-forward path. PLE adds a small token-specific residual update after that path.
Why Not Just Make The Dense Model Smaller?
A smaller dense model would reduce latency and memory, but it would also remove capacity from the main computation path. PLE keeps the expensive repeated transformer blocks closer to the effective size and stores extra capacity in embedding-style parameters.
This makes most sense for small edge models, where the target is a stronger model under a tight compute budget. It is less obvious that the same trick would help much in larger models, where the main transformer stack already has enough capacity and MoE is often the preferred way to add sparse capacity.
Sources