Compressed Convolutional Attention
Compressed Convolutional Attention (CCA) is the attention mechanism used in ZAYA1-8B. The model combines it with a 4:1 grouped-query attention layout, where 8 query heads share 2 key/value heads.
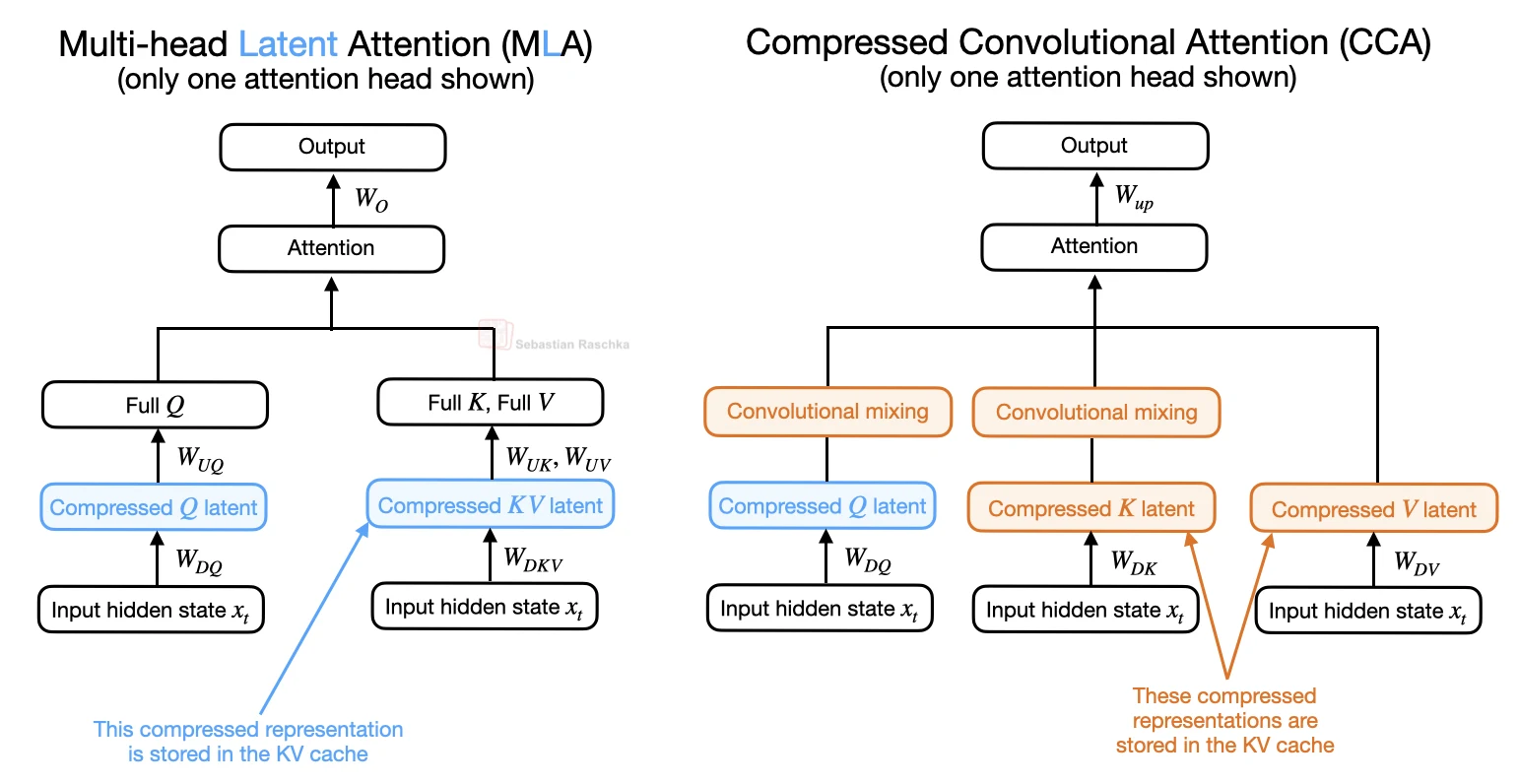
The key difference from standard attention is where the attention operation happens. CCA compresses queries, keys, and values first, then runs attention directly in that compressed latent space. The attention output is up-projected afterward.
What changes
Q, K, and V are compressed before attention is computed
Practical benefit
The compressed attention space reduces KV-cache size and attention FLOPs
Example architectures
How It Differs From MLA
Multi-head latent attention (MLA) is the closest comparison. MLA stores a compressed latent representation in the KV cache and then projects it into the attention-head space for the attention operation.
CCA uses the compressed representation more directly. It compresses Q, K, and V, performs attention in the compressed latent space, and then projects the compressed attention output back to the model dimension.
This changes the cost profile. MLA mainly reduces the KV cache. CCA can reduce the KV cache and the attention computation itself, especially during prefill and training, because the attention matrix is applied to narrower latent vectors.
Why The Convolution Is There
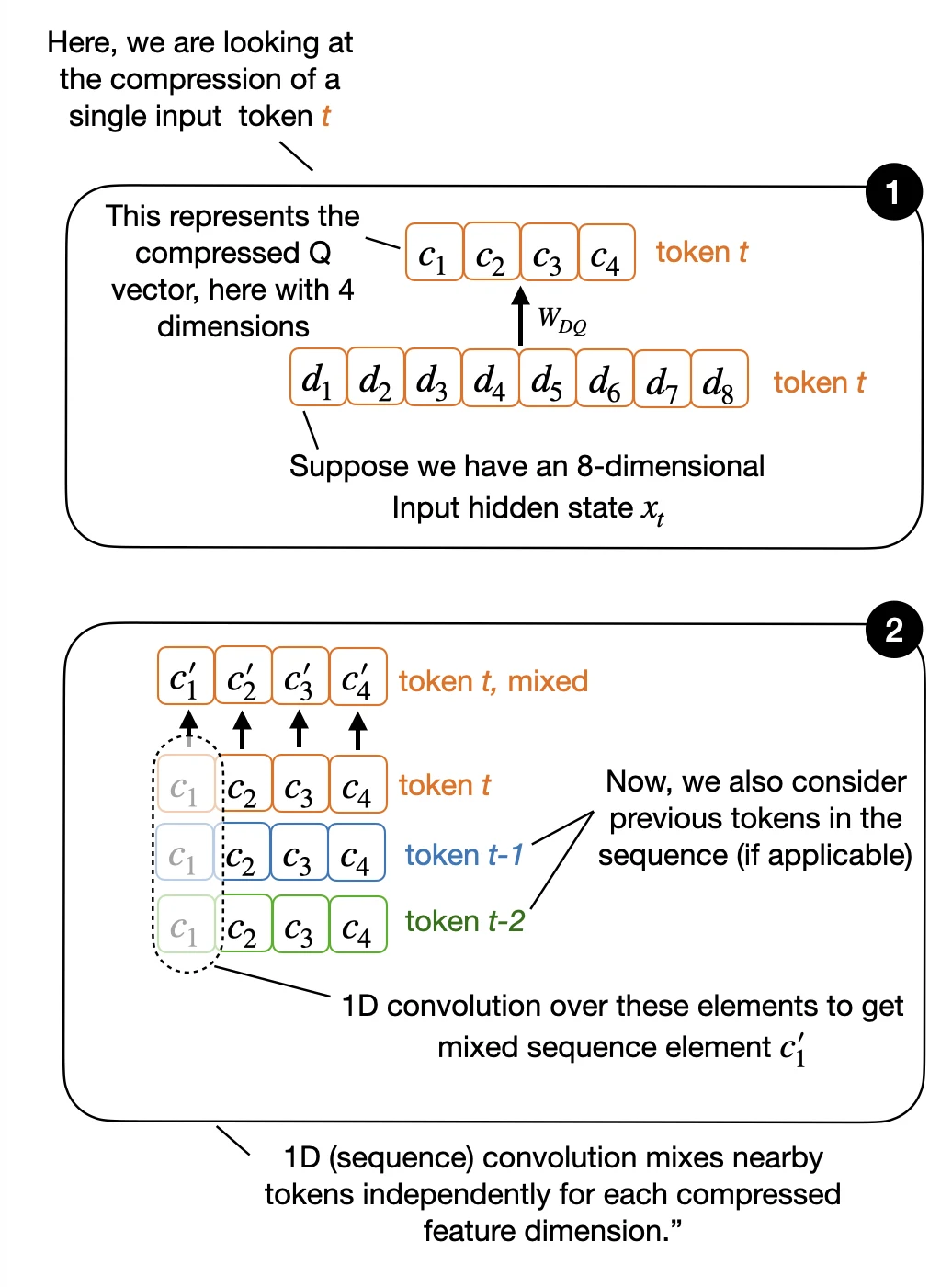
Compression makes the attention representations narrower. That saves memory and compute, but it can also make the attention block less expressive.
CCA adds convolutional mixing on the compressed Q and K tensors. This gives the compressed query and key vectors local sequence context before they determine the attention scores. The value tensor is treated differently because V carries the content that gets averaged by those scores.
The CCA paper also includes channel mixing. The sequence-mixing convolution is the easier part to visualize because it operates across nearby token positions.
How It Fits ZAYA1-8B
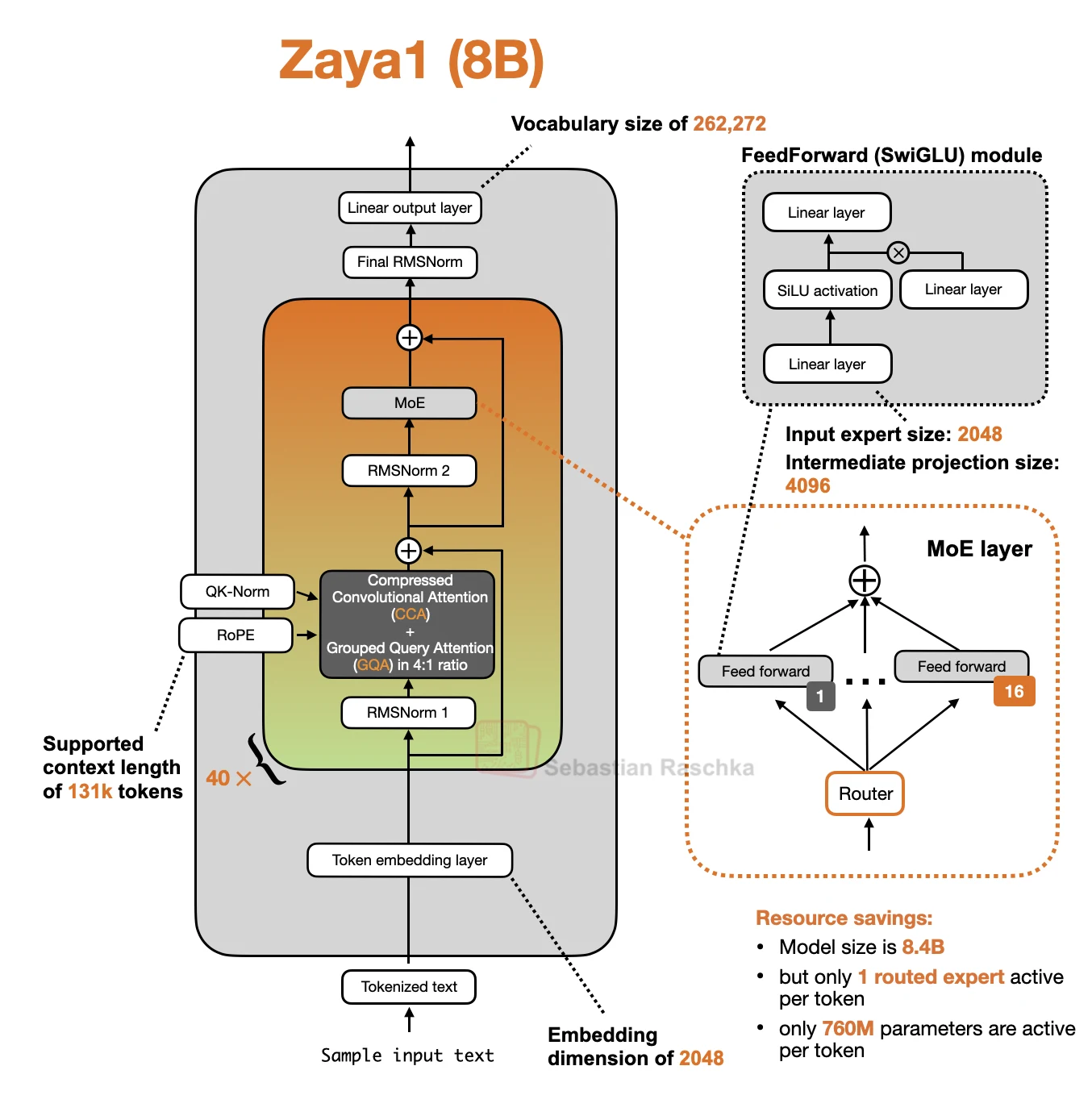
ZAYA1-8B is a sparse MoE model with 8.4B total parameters and about 760M active parameters per token. Its feed-forward path is very sparse because each token uses one routed expert.
The attention path is also optimized for cost. ZAYA1-8B uses CCA with 4:1 GQA, RoPE, and Q/K L2 normalization. The grouped-query part reduces the number of key/value heads. The CCA part moves the attention computation into a compressed latent space.
The model config lists 80 alternating layer entries rather than 40 conventional transformer blocks. These entries alternate between CCA/GQA attention and top-1 MoE feed-forward layers. For a high-level architecture drawing, it is reasonable to group them into 40 attention plus MoE pairs.
Tradeoff
CCA saves attention cost by compressing the vectors that participate in attention. That compression is also the tradeoff. Narrower latent vectors carry less raw per-token information than full-width attention representations.
The convolutional and channel mixing steps are meant to recover some expressiveness without giving up the compressed attention path. In ZAYA1-8B, this makes CCA the attention-side counterpart to the model’s sparse MoE feed-forward path.
Sources