Layer-Wise Attention Budgeting
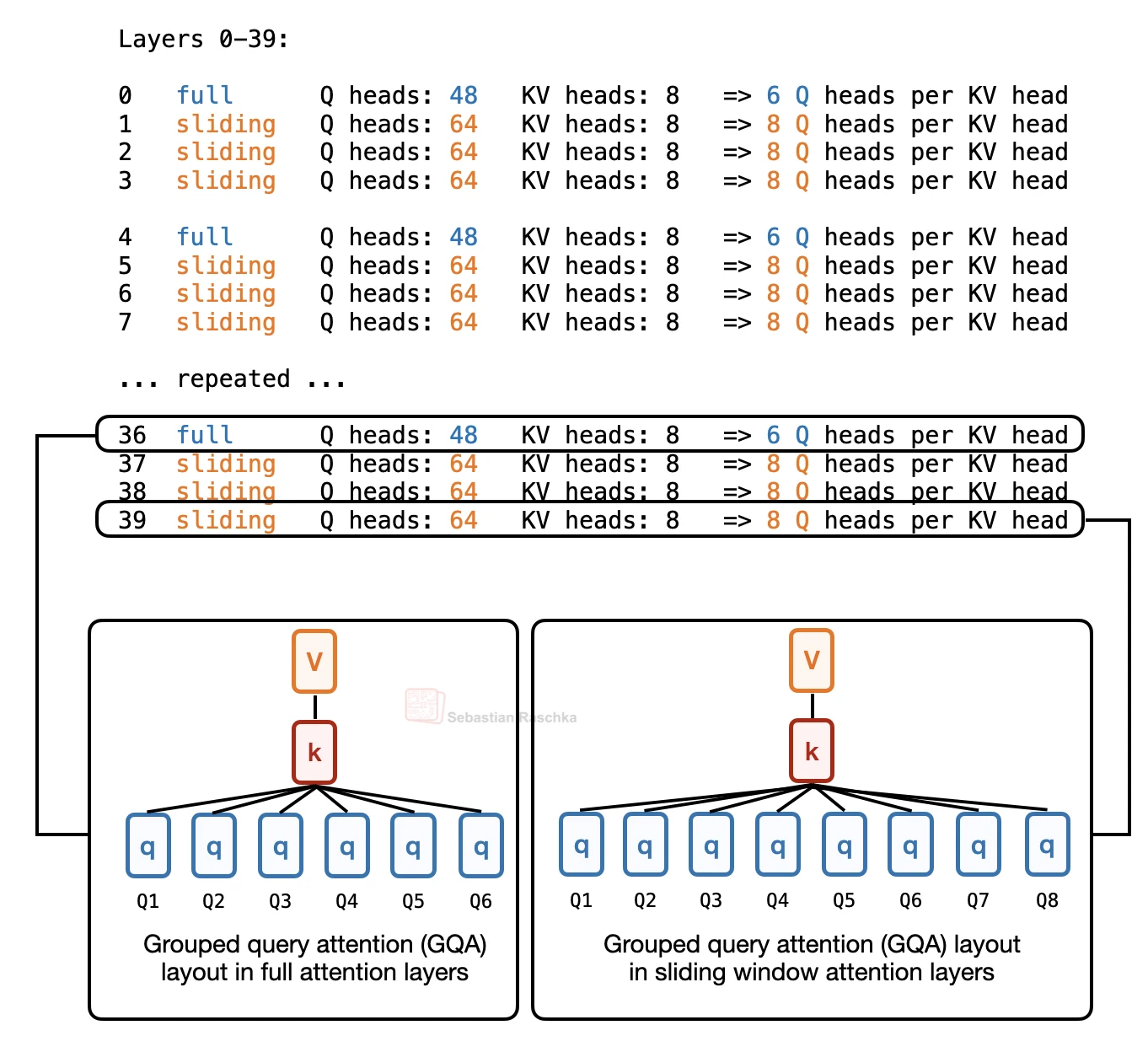
Layer-wise attention budgeting gives different transformer layers different attention capacity. In Laguna XS.2, this shows up as different query-head counts for full-attention layers and sliding-window layers.
The model keeps 8 KV heads throughout the stack. What changes is the number of query heads. Full-attention layers use 48 query heads, or 6 query heads per KV head. Sliding-window layers use 64 query heads, or 8 query heads per KV head.
What changes
Query-head counts vary by layer while the KV-head count stays fixed
Practical benefit
The model spends less attention capacity on expensive global layers and more on cheaper local layers
Example architectures
What Is Being Budgeted
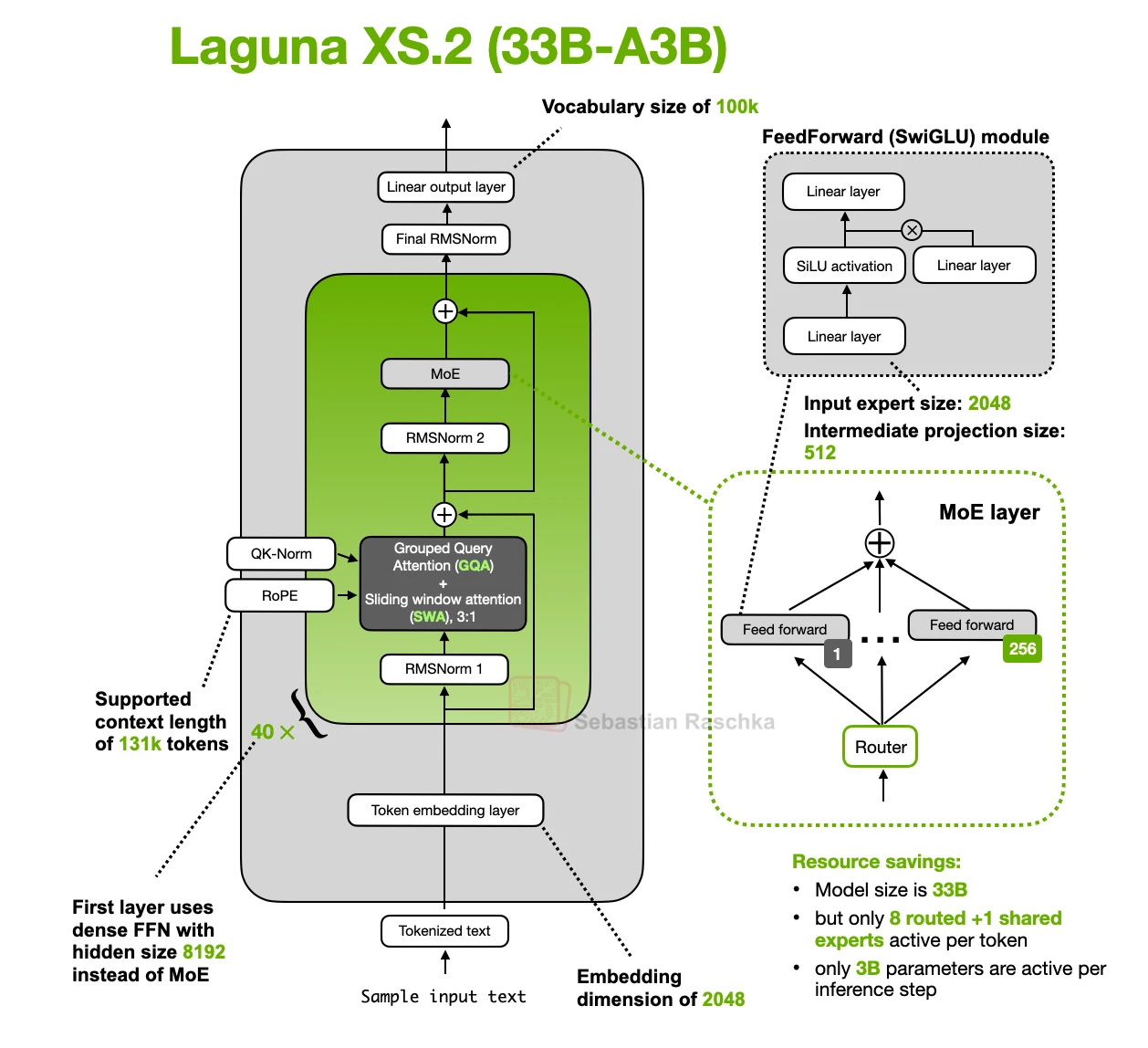
Laguna XS.2 mixes sliding-window attention and global attention. It has 40 layers in total, with 30 sliding-window layers and 10 global layers. The sliding-window layers see a local 512-token window. The global layers can attend over the full context.
Local layers are cheaper because they do not attend across the full prefix. Global layers are more expensive because they keep long-range access.
Laguna adds another budget decision on top of this. The model gives the two layer types different numbers of query heads.
Full Layers Use Fewer Query Heads
The full-attention layers use 48 query heads and 8 KV heads. That is 6 query heads per KV head.
The sliding-window layers use 64 query heads and the same 8 KV heads. That is 8 query heads per KV head.
This keeps the KV-cache shape compatible across the stack because the KV-head count stays fixed. At the same time, Laguna can allocate fewer query heads to global layers, where each attention operation is more expensive, and more query heads to sliding-window layers, where the attention window is smaller.
The useful idea is that different layer types can receive different attention budgets.
Relation To Earlier Ideas
Mixed local and global attention is common in recent long-context models. Gemma models also use this kind of pattern. Laguna XS.2 is notable because it combines that pattern with per-layer query-head counts in a production-style open model.
The broader idea of varying model capacity by layer is older. Apple’s OpenELM also used layer-wise scaling, although its mechanism differs from Laguna’s query-head budgeting pattern.
Laguna also applies per-head attention-output gating. That is a separate detail from the budgeting shown here, but it fits the same general theme of making attention capacity more selective.
Sources