What are good ways to build an instruction dataset from scratch?
Good instruction datasets usually come from a combination of careful curation and iterative expansion, not from dumping together random prompts and answers.
A good workflow is:
- start with a clear schema such as
instruction,input, andoutput - collect a diverse set of seed tasks
- enforce consistent formatting
- remove duplicates and near-duplicates
- expand or refine the dataset with synthetic generation if needed
- keep a separate evaluation split
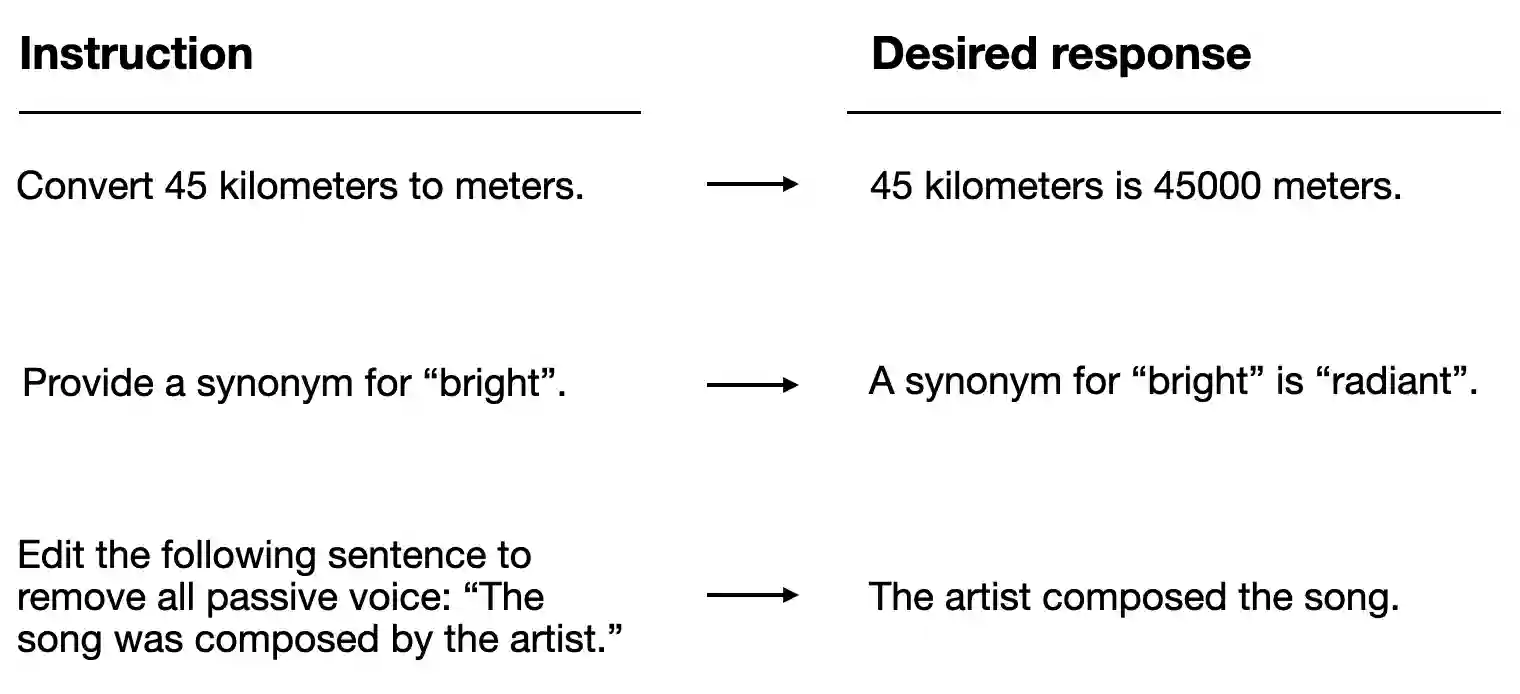
The repo’s chapter 7 utilities support several parts of that process:
- finding near-duplicates
- creating synthetic variants of entries
- generating instruction data with Llama 3 and Ollama
- refining data via reflection tuning
That reflects an important point: dataset quality is not just about size. If the dataset is repetitive, inconsistent, or noisy, the model will learn those patterns too.
Useful dataset-building principles are:
- cover many task types, not just one format
- make outputs high quality and internally consistent
- avoid duplicate prompts that overweight one behavior
- keep templates and fields predictable
- inspect samples manually instead of trusting only automation
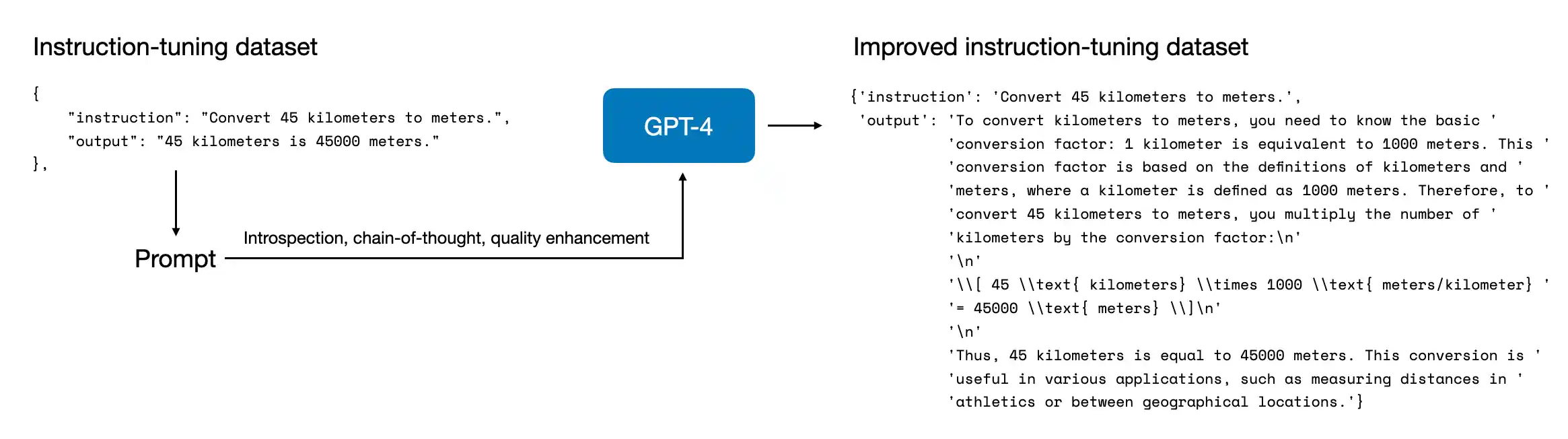
So a good instruction dataset is usually built by starting small and clean, then expanding carefully with filtering and review rather than optimizing only for raw example count.
In short, good ways to build an instruction dataset from scratch include using a consistent schema, ensuring task diversity, removing duplicates, generating synthetic examples carefully, and refining the dataset iteratively instead of maximizing size alone.