VibeThinker-3B and the Strength of Post-Training
According to the reported benchmarks, VibeThinker-3B gets surprisingly close to much larger coding and reasoning systems.
What I found most interesting is that the model builds on the older Qwen2.5-Coder-3B stack. Based on the model card, VibeThinker-3B has 3.09B parameters and uses a Qwen2-style backbone.
So, this is a pretty clear example of how much can come from good data curation and post-training.
The technical report is worth reading because it gives a detailed look at the post-training pipeline. The important pieces are:
- high-signal synthetic math and code data with verifiable solutions
- multiple reasoning paths per answer, followed by aggressive filtering
- two-stage supervised finetuning, first broad coverage and then harder long-reasoning examples
- checkpoint selection by target accuracy rather than validation loss alone
- MGPO, a GRPO-style RLVR method that emphasizes samples that are neither too easy nor too hard
- single-stage 64k-context RL, instead of progressive context expansion
- domain RL ordered as math, then code, then STEM
- a later stage that rewards shorter correct trajectories
- offline self-distillation from filtered Math, Code, and STEM RL trajectories
- final instruction RL using rule-based validators and rubric-based reward models
They do not share the exact GPU hours for this project. Based on numbers from the earlier VibeThinker-1.5B report, my rough guess would be that this cost on the order of $25k to $60k. That is still a lot of money, but it is not millions.
One caveat is that as of June 17, 2026, the model is very new, and the benchmarks could still be too good to be true. It needs practical use over the next few days to see whether the VibeThinker results check out in practice. But as a first impression, this is a strong small-model result and a useful post-training write-up.
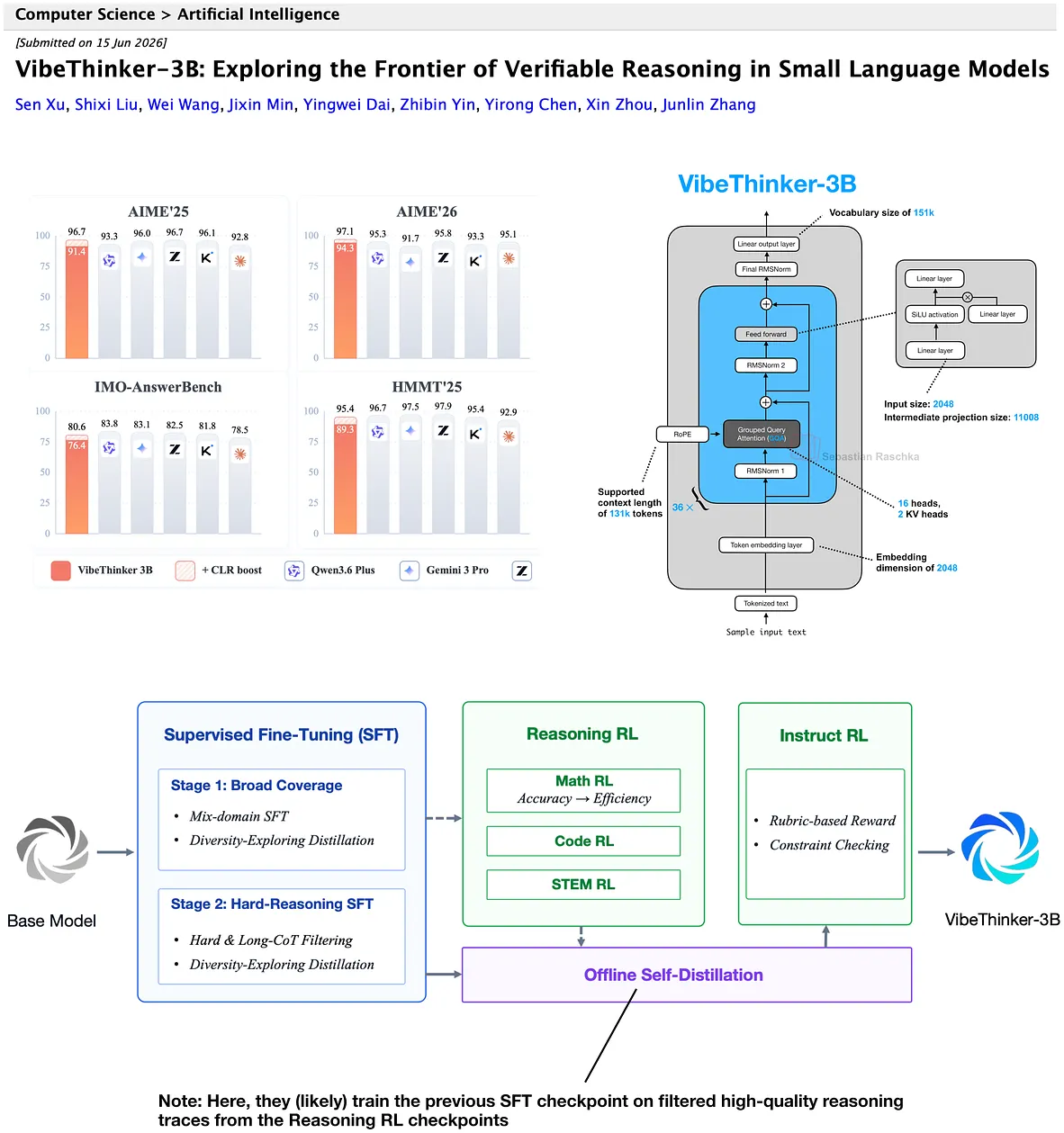
Source: lightly edited website version of my Substack note.
Read Next
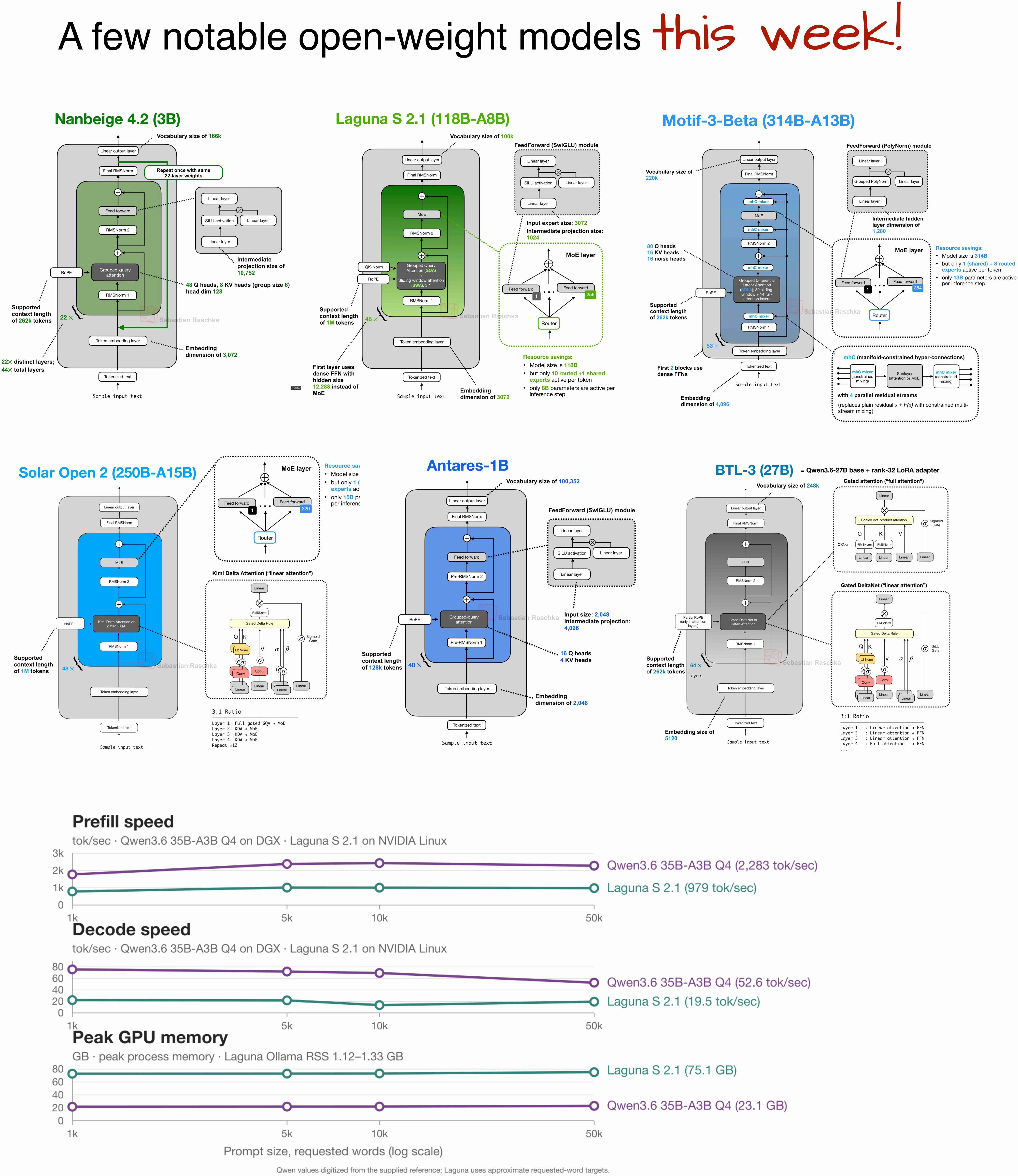 A Few Notable Open-Weight Models This Week
Short note on the architectures of six new open-weight models, including Nanbeige 4.2, Laguna S 2.1, Motif-3-Beta, Solar Open 2, Antares 1B, and BTL-3.
A Few Notable Open-Weight Models This Week
Short note on the architectures of six new open-weight models, including Nanbeige 4.2, Laguna S 2.1, Motif-3-Beta, Solar Open 2, Antares 1B, and BTL-3.
 Correction for Listing 6.5 in Build a Reasoning Model From Scratch
Short correction note for the random seed in Listing 6.5 on page 198 of Build a Reasoning Model From Scratch.
Correction for Listing 6.5 in Build a Reasoning Model From Scratch
Short correction note for the random seed in Listing 6.5 on page 198 of Build a Reasoning Model From Scratch.
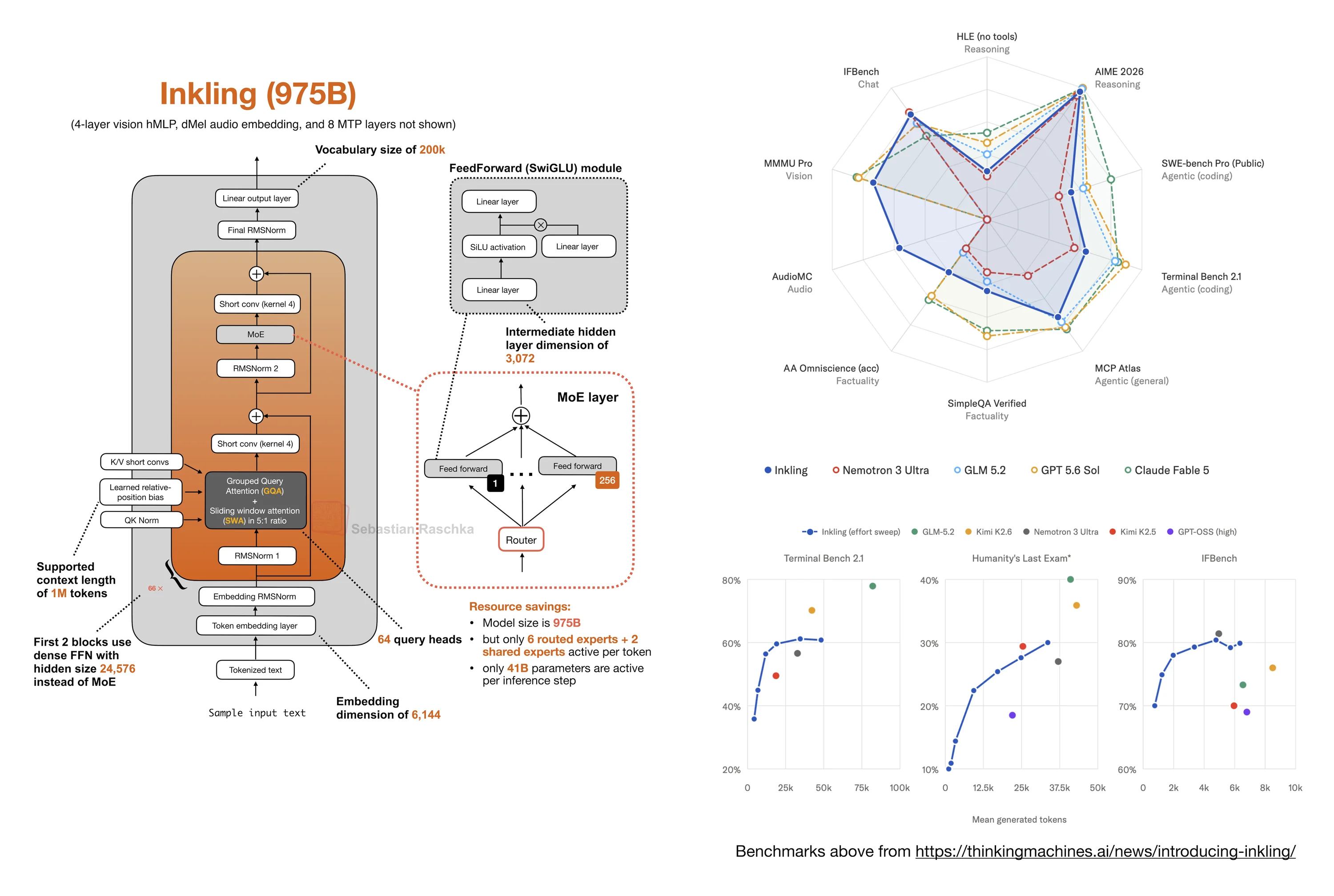 Inkling: A New Open-Weight 975B MoE with a Few Surprises
Short note on Thinking Machines Lab's 975B Inkling model, including benchmarks, sparse MoE design, short convolutions, RMSNorm, and position bias.
Inkling: A New Open-Weight 975B MoE with a Few Surprises
Short note on Thinking Machines Lab's 975B Inkling model, including benchmarks, sparse MoE design, short convolutions, RMSNorm, and position bias.