Implementing LLM Architectures From Scratch
I shared a short talk on what I learned from implementing LLM architectures from scratch in Python and PyTorch.
The practical part is the workflow. When a new open-weight model comes out, I usually start from a compact reference implementation, trace the architecture changes, and compare those details against model cards, config files, and released code. This is often the fastest way to separate naming differences from actual design changes.
The talk is here: What I Learned From Implementing LLM Architectures From Scratch.
For related reading, see the recent LLM architecture developments article and the LLM Architecture Gallery.
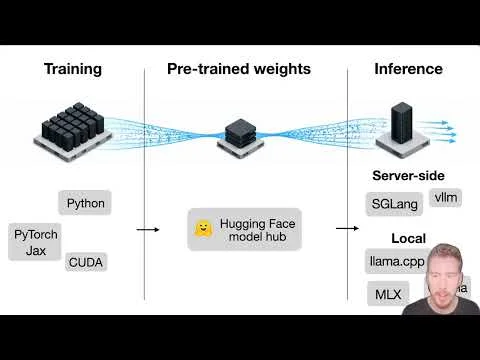
Source: lightly edited website version of my Substack note.
Read Next
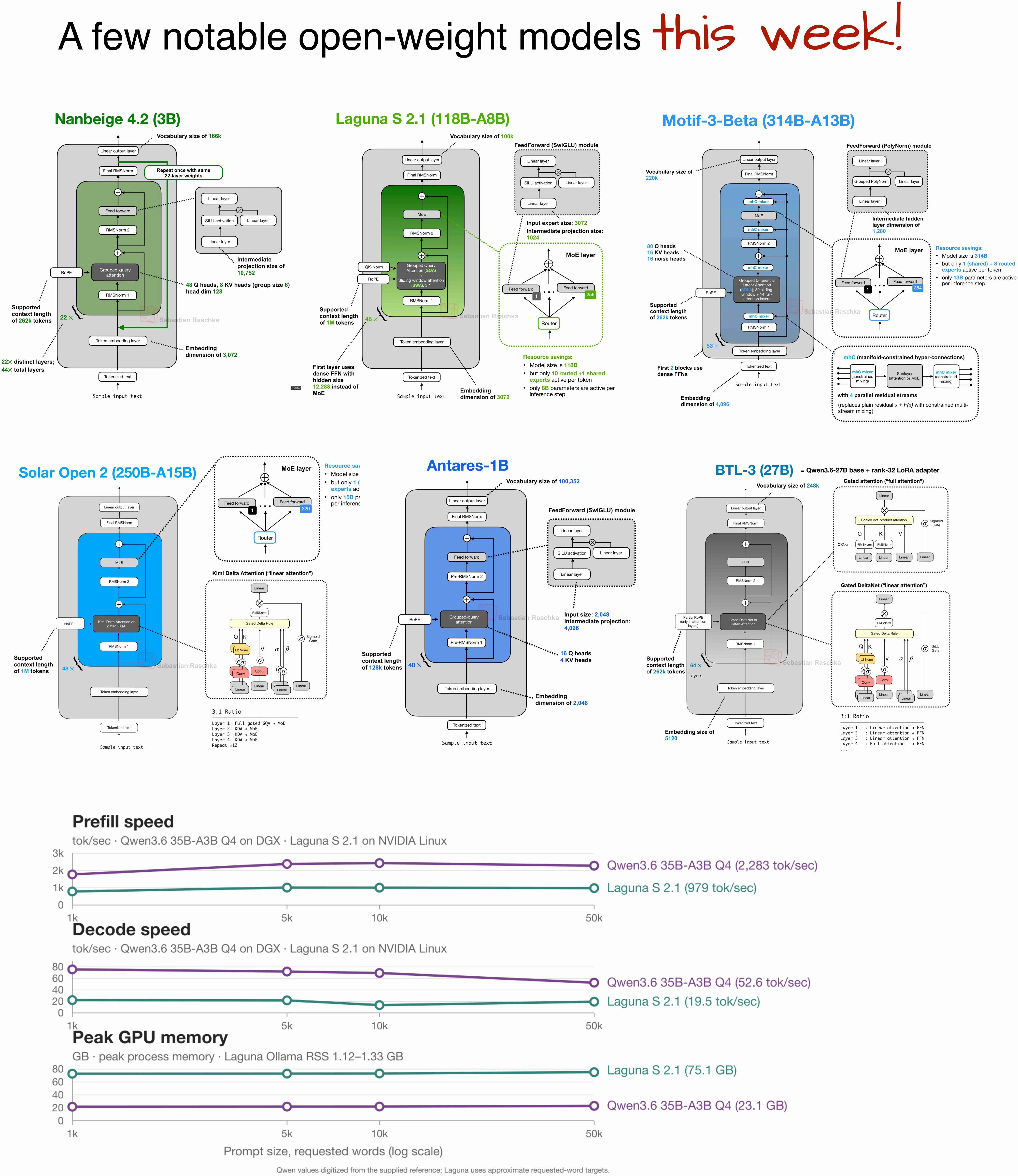 A Few Notable Open-Weight Models This Week
Short note on the architectures of six new open-weight models, including Nanbeige 4.2, Laguna S 2.1, Motif-3-Beta, Solar Open 2, Antares 1B, and BTL-3.
A Few Notable Open-Weight Models This Week
Short note on the architectures of six new open-weight models, including Nanbeige 4.2, Laguna S 2.1, Motif-3-Beta, Solar Open 2, Antares 1B, and BTL-3.
 Correction for Listing 6.5 in Build a Reasoning Model From Scratch
Short correction note for the random seed in Listing 6.5 on page 198 of Build a Reasoning Model From Scratch.
Correction for Listing 6.5 in Build a Reasoning Model From Scratch
Short correction note for the random seed in Listing 6.5 on page 198 of Build a Reasoning Model From Scratch.
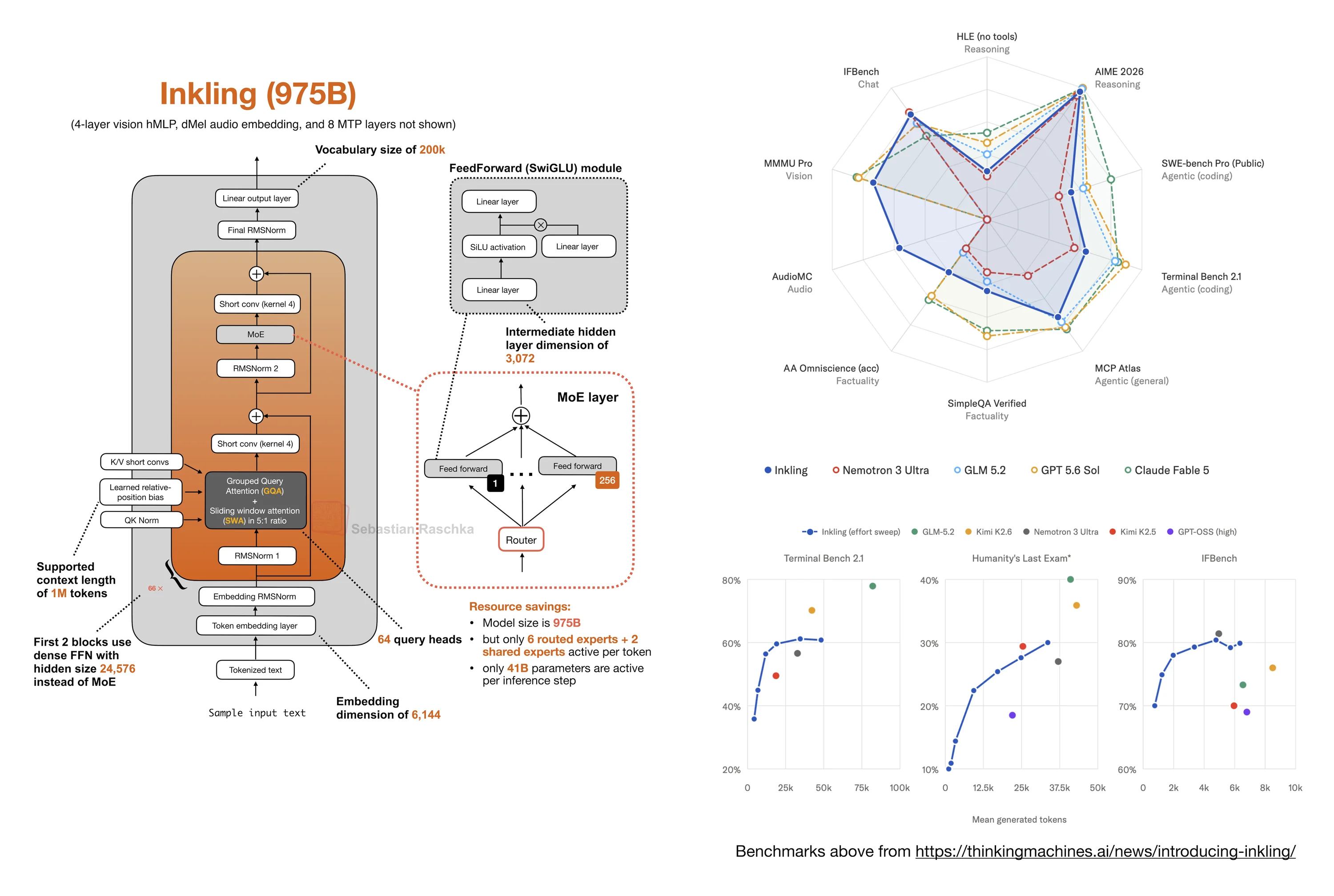 Inkling: A New Open-Weight 975B MoE with a Few Surprises
Short note on Thinking Machines Lab's 975B Inkling model, including benchmarks, sparse MoE design, short convolutions, RMSNorm, and position bias.
Inkling: A New Open-Weight 975B MoE with a Few Surprises
Short note on Thinking Machines Lab's 975B Inkling model, including benchmarks, sparse MoE design, short convolutions, RMSNorm, and position bias.