Gemma 4 Architecture and Benchmark Notes
Gemma 4 is an interesting release because the 31B dense model does not look radically different from Gemma 3 27B at the architecture level.
Based on the Gemma 4 model card and Gemma 4 31B config, the model keeps the familiar Gemma-style local-global attention recipe:
- 5:1 sliding-window to global attention ratio
- Grouped-query attention with QK-Norm
- Pre- and post-RMSNorm blocks
- 256k-token context length
- 262k-token vocabulary
The benchmark jump over Gemma 3 is therefore probably more about the training data and recipe than about a new transformer block. As of April 2026, the plotted benchmark results put Gemma 4 31B much closer to Qwen3.5-27B than Gemma 3 27B on several common benchmarks. Arena-style rankings are useful signals, but I would treat them as preference-biased rather than as clean capability measurements.
There is also a sparse MoE variant, Gemma 4 26B-A4B, which keeps the same local-global attention backbone but swaps dense feed-forward layers for MoE layers. I left it out of the figure to keep the comparison readable, but it is included in the LLM Architecture Gallery.
The licensing is also worth noting. Gemma 4 is listed under the Apache License 2.0, which is much friendlier for many use cases than the custom Gemma 3 license.
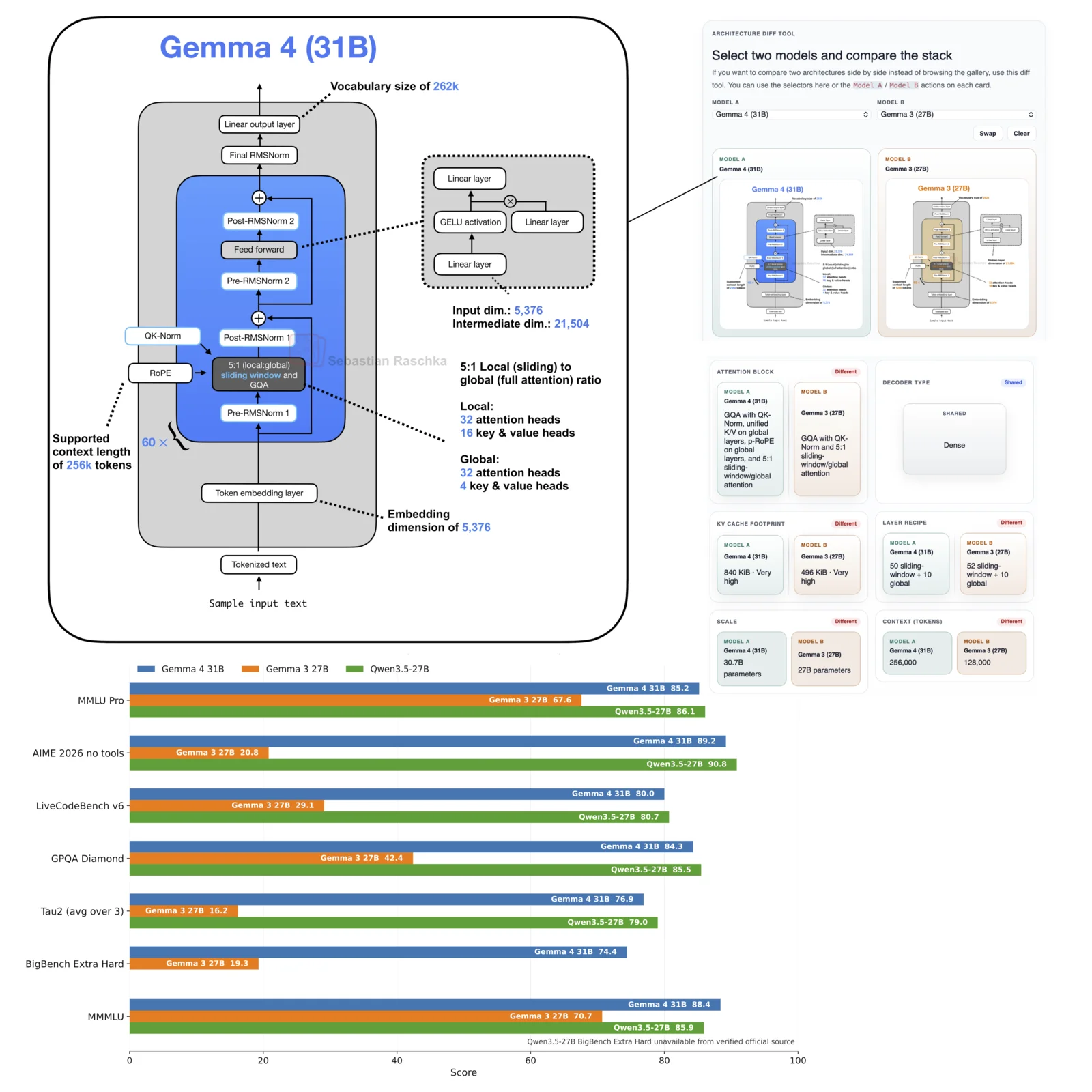
Source: lightly edited website version of my Substack note.
Read Next
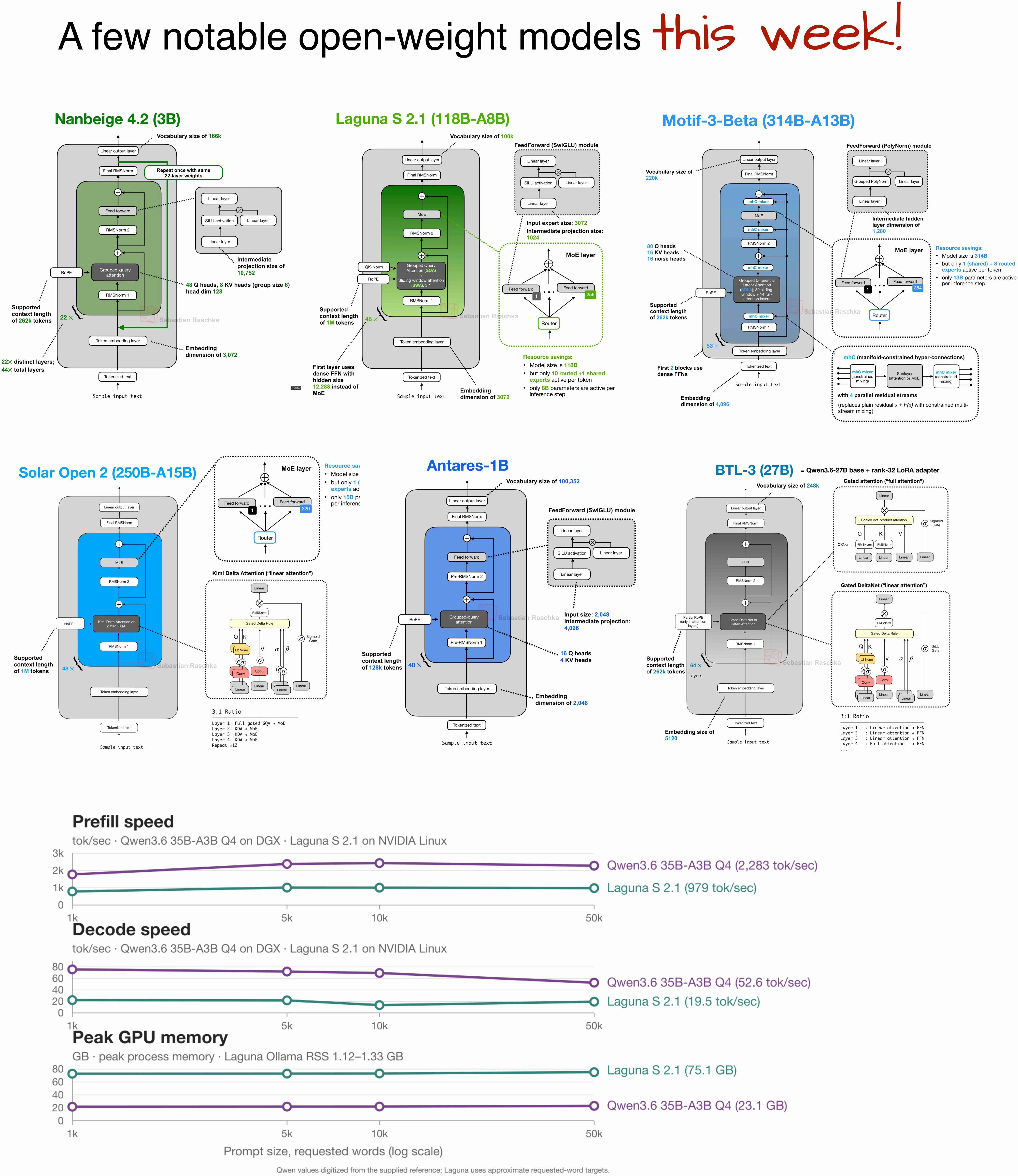 A Few Notable Open-Weight Models This Week
Short note on the architectures of six new open-weight models, including Nanbeige 4.2, Laguna S 2.1, Motif-3-Beta, Solar Open 2, Antares 1B, and BTL-3.
A Few Notable Open-Weight Models This Week
Short note on the architectures of six new open-weight models, including Nanbeige 4.2, Laguna S 2.1, Motif-3-Beta, Solar Open 2, Antares 1B, and BTL-3.
 Correction for Listing 6.5 in Build a Reasoning Model From Scratch
Short correction note for the random seed in Listing 6.5 on page 198 of Build a Reasoning Model From Scratch.
Correction for Listing 6.5 in Build a Reasoning Model From Scratch
Short correction note for the random seed in Listing 6.5 on page 198 of Build a Reasoning Model From Scratch.
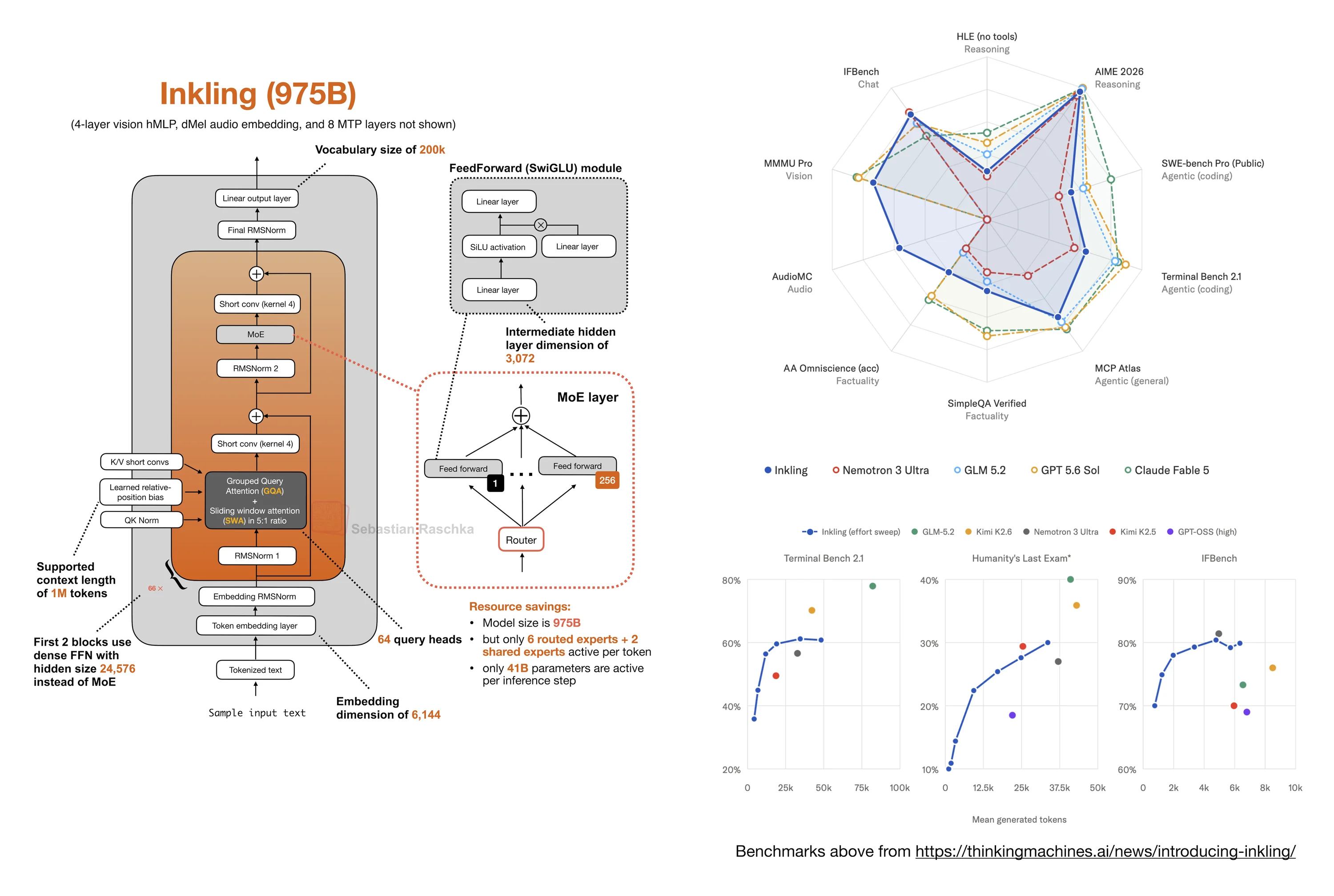 Inkling: A New Open-Weight 975B MoE with a Few Surprises
Short note on Thinking Machines Lab's 975B Inkling model, including benchmarks, sparse MoE design, short convolutions, RMSNorm, and position bias.
Inkling: A New Open-Weight 975B MoE with a Few Surprises
Short note on Thinking Machines Lab's 975B Inkling model, including benchmarks, sparse MoE design, short convolutions, RMSNorm, and position bias.