Research Papers in February 2024
— A LoRA Successor, Small Finetuned LLMs Vs Generalist LLMs, and Transparent LLM Research
Once again, this has been an exciting month in AI research. This month, I’m covering two new openly available LLMs, insights into small finetuned LLMs, and a new parameter-efficient LLM finetuning technique.
The two LLMs mentioned above stand out for several reasons. One LLM (OLMo) is completely open source, meaning that everything from the training code to the dataset to the log files is openly shared.
The other LLM (Gemma) also comes with openly available weights but achieves state-of-the-art performance on several benchmarks and outperforms popular LLMs of similar size, such as Llama 2 7B and Mistral 7B, by a large margin.
However, before we discuss the details of this new LLM’s architecture tweaks, let’s start by discussing the utility of small LLMs in more detail, beginning with the Tiny Titans paper below.
1. Tiny Titans: Can Smaller Language Models Punch Above Their Weight in the Real World for Meeting Summarization?
In this Tiny Titans paper, researchers set out to answer a literal million-dollar question: can “small” finetuned LLMs with less than 2B parameters outperform larger, openly available LLMs like Llama 2 Chat, and proprietary LLMs like GPT-3.5?
The answer is not very clear-cut. Before discussing the details, the results are summarized in the table below.
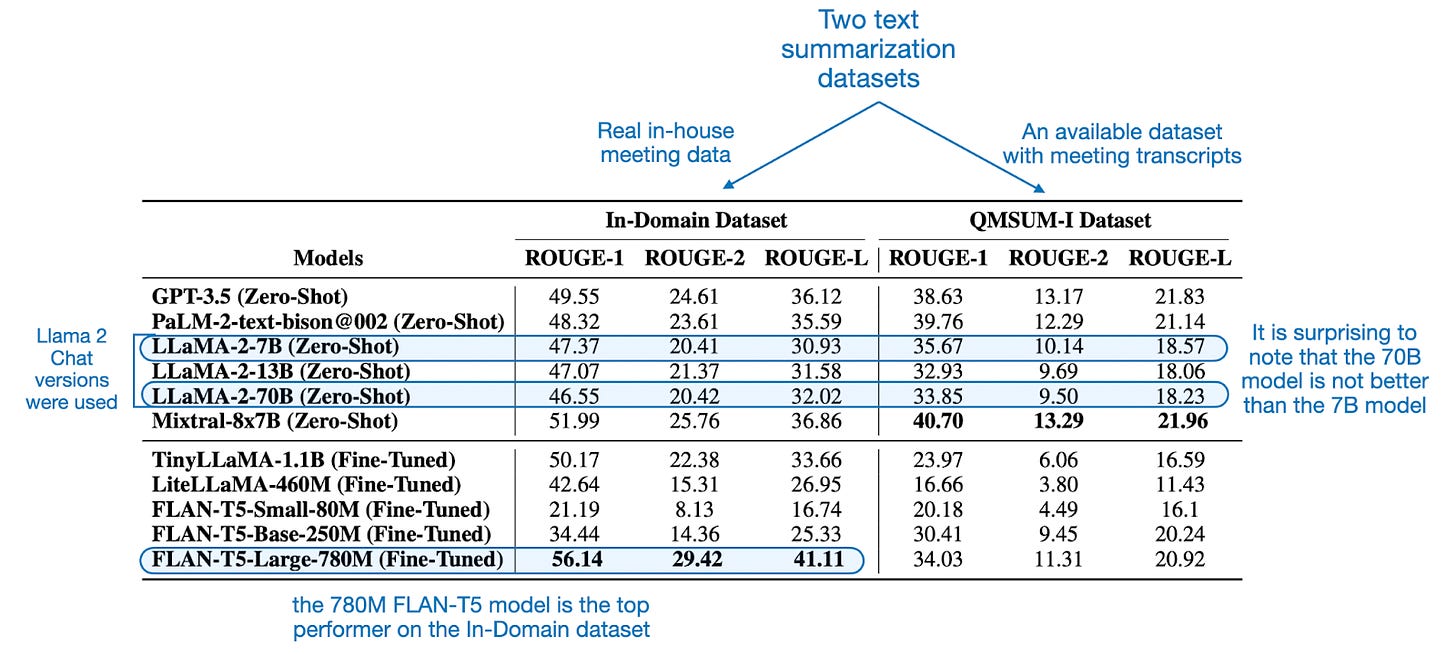
In the table above, “zero-shot” means that these models have not been further finetuned on meeting data and summaries, but were used off-the-shelf either via the openly available weights (e.g., Llama 2 7B Chat) or their proprietary API (e.g., GPT-3.5).
However, a significant caveat to note is that while these “zero-shot” models were not finetuned further by the authors of the paper, their original creation already involved very extensive instruction finetuning, which also includes generating text summaries.
Now, we can see that FLAN-T5-Large is a clear winner in the In-Domain Datasetcategory (real-world meeting data that is not available on the internet), so we can partly say yes, small finetuned LLMs can outperform larger available LLMs. However, why does it perform so much worse than, for example, GPT-3.5 and Mixtral-8x7B on the QMSUM-I dataset? The answer might be twofold.
First, GPT-3.5 and Mixtral may have used some of the QMSUM data, which is publicly available, during their own training (since details about the data used for model training are not publicly disclosed, we cannot say for sure).
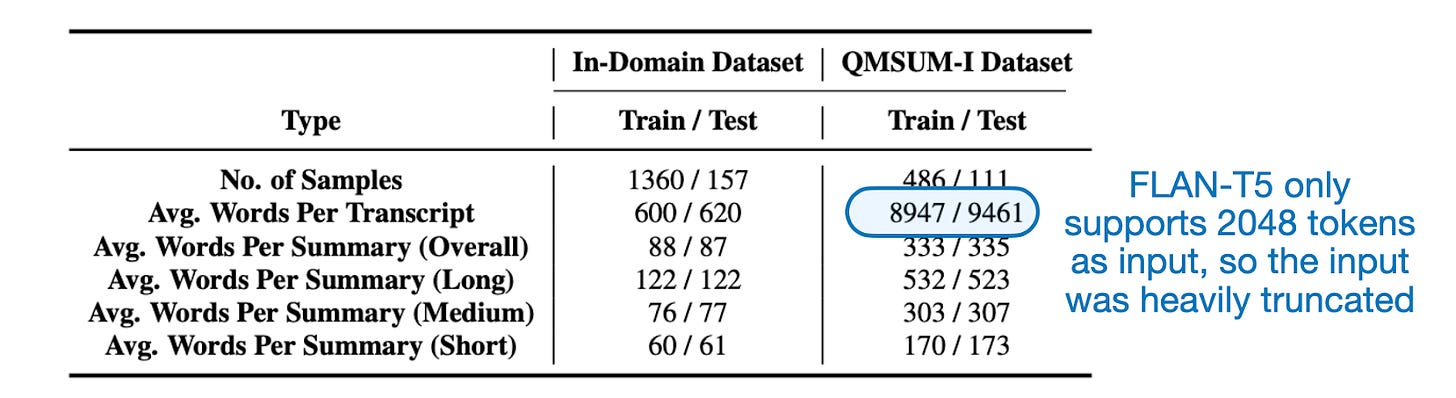
The second plausible explanation is that FLAN-T5-Large has a context size limited to 2048 tokens, and the QMSUM dataset has inputs 4-5 times larger, as shown in the table below.
1.1 Are the Automated Metrics Reliable?
Besides the truncation issue discussed above, are the ROUGE scores, which are automated metrics (a hands on example here), reliable at all?
In general, ROUGE scores for summaries are considered reliable for evaluating the overlap between machine-generated summaries and reference summaries, particularly in terms of n-gram overlap, word sequences, and word pair matches. However, they may not fully capture the quality of a summary in terms of coherence, readability, or factual accuracy, and are thus not a perfect tool. Therefore, the researchers also looked into human evaluations, which are summarized in the table below.

Based on the results in the table above, it appears that FLAN performs really well compared to Llama 2 7B on the In-Domain dataset and is roughly on par with GPT-3.5. The weakness on the QMSUM-I dataset is similar to what we observed when looking at the ROUGE scores earlier.
Another point to note here is that GPT-4 was used for the gold-reference summaries. Assuming GPT-3.5 was pretrained and instruction-finetuned in a similar fashion as GPT-4, I expect the results to be slightly biased in favor of GPT-3.5.
1.2 Why Did the Small Models Perform Relatively Badly?
In general, besides FLAN-T5 on the In-Domain dataset, we observed that small finetuned LLMs performed poorly compared to the larger LLMs.
One reason is their limited context size, which leads to truncation of the input data. This is problematic when generating summaries. One could address this by extending the context lengths during training and inference, which doesn’t necessarily mean an increase in model size.
Another reason might be the models’ smaller capacity to store and process information in the intermediate states. To investigate this, we would have to train various LLMs with different context lengths at the very least.
The chosen task for the small LLMs was finetuning on summarization tasks. However, summarization finetuning has also been a significant part of training the large proprietary LLMs. In other words, we are comparing large finetuned LLMs to small finetuned LLMs. It would be interesting to see this comparison for novel domain-specific tasks that were not already part of the instruction finetuning pipeline of LLMs.
1.3 Takeaways
Mixtral (covered in the last edition) is really good! And FLAN-T5, which is magnitudes smaller, remains a great model for certain finetuning tasks.
2. DoRA: Weight-Decomposed Low-Rank Adaptation
In DoRA: Weight-Decomposed Low-Rank Adaptation, researchers introduce an innovative alternative to LoRA, the most widely adopted parameter-efficient finetuning method for LLMs and Vision Transformers. I originally planned to cover it in this article, but I found this method so exciting that I couldn’t resist and implemented it a few weeks ago.
For those interested in further details and the paper discussion, I have written a comprehensive article and a from-scratch implementation guide covering DoRA here: Improving LoRA: Implementing Weight-Decomposed Low-Rank Adaptation (DoRA) from Scratch)).
3. OLMo: Accelerating the Science of Language Models
The “OLMo” in OLMo: Accelerating the Science of Language Models refers to Open Language Model, a recently released open-source LLM (available in 1B and 7B parameter versions). What’s notable about OLMo is that the researchers not only shared the model weights but also all training details, including the training code, training data, model evaluation code, log files, and finetuning code.
I highly recommend reading the OLMo paper itself. I wish it contained more insights and analyses, but seeing the list of small architecture choices and hyperparameter configurations is already useful for my own experiments. Here are two notable ones:
- They disabled the bias vectors in all linear layers (similar to Llama) to improve training stability.
- Instead of using standard LayerNorm (with trainable scale and shift parameters) or RMSNorm, they used a LayerNorm variant without any trainable parameters.
Furthermore, the table below lists the key architecture differences compared to other popular LLMs.

Moreover, the OLMo paper provides useful details about the optimizer hyperparameters and learning rate for AdamW, which are summarized in the following table.
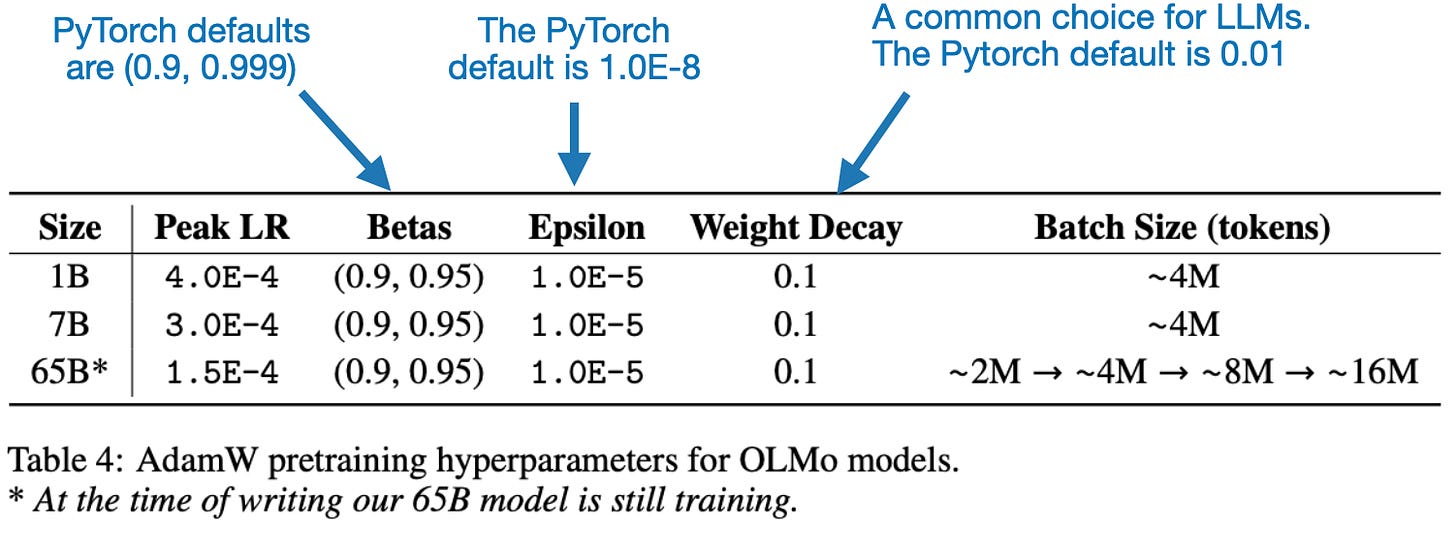
Regarding the learning rate, they used a 5000-step (~21B tokens) warm-up and then applied a linear (rather than cosine) decay down to one tenth of the learning rate shown in the table above. In addition, they clipped the gradients to an L2-norm maximum value of 1.0.
Lastly, it’s interesting to note that they used a linear rather than a cosine learning rate schedule for decaying the learning rate, as shown in the comparison table below
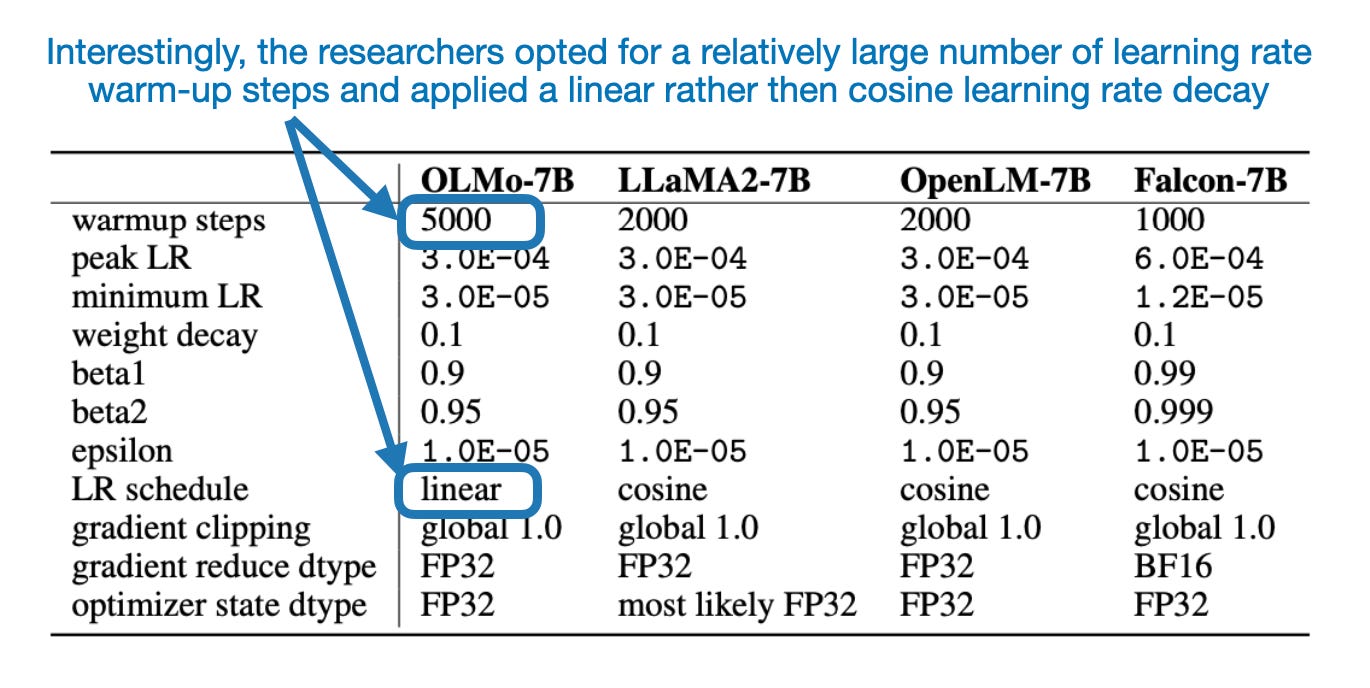
While these choices are all interesting, how does it actually compare to other LLMs? It turns out that OLMo is comparable to Llama 2 and Falcon, as shown in the table below.
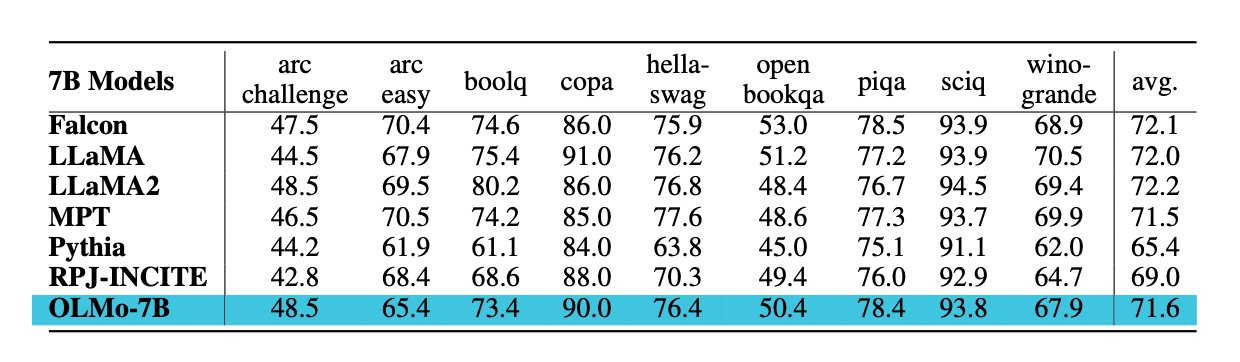
While there are no additional ablation studies on certain hyperparameter and architecture choices, all the log files are available on W&B, so we could potentially do our own analyses in the upcoming weeks or months. Overall, I think OLMo is a really nice contribution to the open-source and research communities, and I really appreciate the authors sharing all the code and training artifacts.
Build an LLM from Scratch
If you are interested in improving your understanding of LLMs by building an LLM from scratch (just using PyTorch without external LLM libraries), Chapter 4 in my Build a Large Language From Scratch book is now available in Manning’s early access version.
4. Gemma
Of course, we have to discuss Gemma, a suite of LLMs recently introduced by Google. The Gemma LLMs, built on the Gemini architecture, are available in four variants: the pretrained Gemma 2B and 7B base models, along with the Gemma 2B and 7B instruction-finetuned models.
In addition to sharing the model weights, Google has also published a technical report titled Gemma: Open Models Based on Gemini Research and Technology, which we will discuss in greater detail below.
4.1 Gemma Performance
The most notable aspect of Gemma is its impressive performance compared to other popular and widely used open-source models, such as Llama 2 7B and Mistral, as shown in the figure below
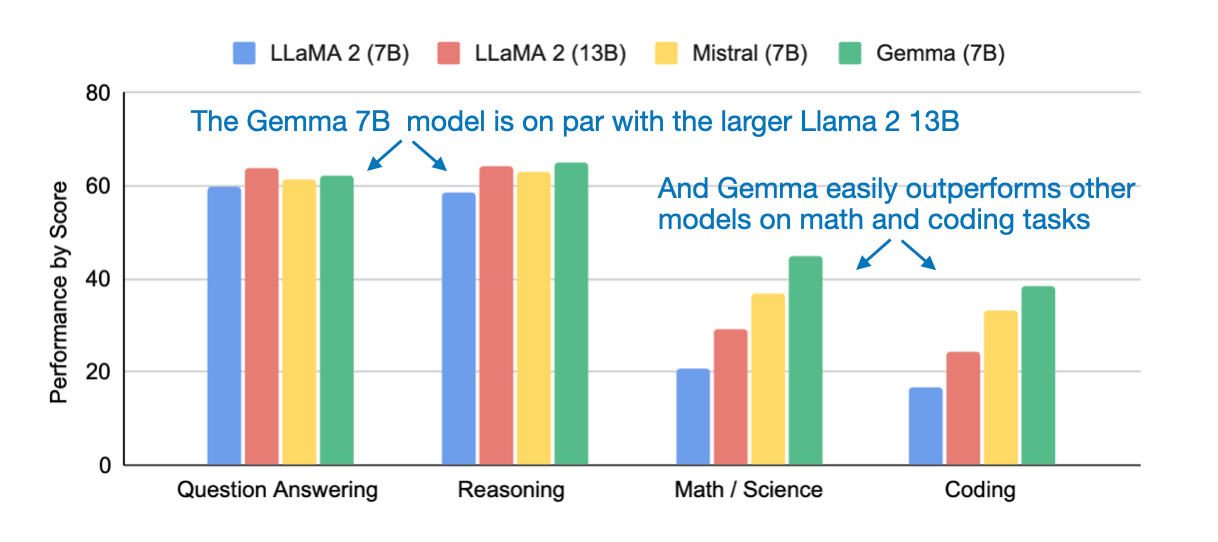
It’s not entirely clear whether the scores mentioned above refer to the pretrained or instruction-finetuned variants; however, I assume they likely represent the performance of the instruction-finetuned models.
What contributes to Gemma’s outstanding performance? The reasons are not explicitly stated in the paper, but I assume it’s due to:
- The large vocabulary size of 256,000 words (in contrast, Llama has a vocabulary of 32,000 words);
- The extensive 6 trillion token training dataset (Llama was trained on only one-third of that amount).
Moreover, upon integrating Gemma into our open-source Lit-GPT repository, my colleagues and I noticed that its overall architecture bears a strong resemblance to that of Llama 2. Let’s examine this aspect more closely in the next section.
4.2 Gemma Architecture Insights
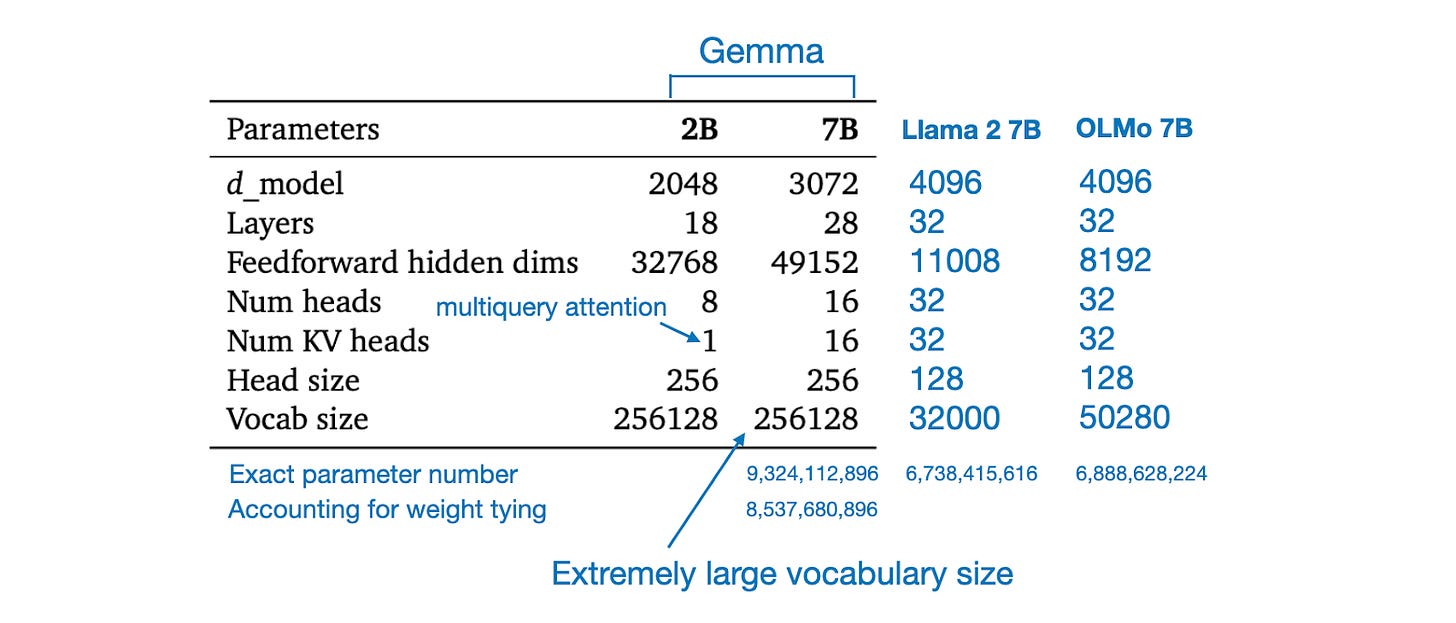
What are some of the interesting design choices behind Gemma? As mentioned above, its vocabulary size (and consequently the embedding matrix size) is very large. The table below shows an architecture overview comparing Gemma to LLama 2 7B and OLMo 7B, which we discussed earlier.
Model Sizes
Something else worth noting is that Gemma 2B utilized multi-query attention, whereas Gemma 7B did not. Additionally, Gemma 7B features a relatively large feedforward layer compared to Llama 2, despite having fewer layers in total (28 versus 32). However, despite having fewer layers, the number of parameters in Gemma is quite large.
Although it is called Gemma 7B, it actually has 9.3 billion parameters in total, and 8.5 billion parameters if you account for weight tying. Weight tying means that it shares the same weights in the input embedding and output projection layer, similar to GPT-2 and OLMo 1B (OLMO 7B was trained without weight tying).
Normalization Layers
Another detail that stands out is the following quote from the paper:
> Normalizer Location. We normalize both the input and the output of each transformer sub-layer, a deviation from the standard practice of solely normalizing one or the other. We use RMSNorm (Zhang and Sennrich, 2019) as our normalization layer.
At first glance, it sounds like Gemma has an additional RMSNorm layer after each transformer block. However, looking at the official code implementation, it turns out that Gemma just uses the regular pre-normalization scheme that is used by other LLMs like GPT-2, Llama 2, and so on, as illustrated below.
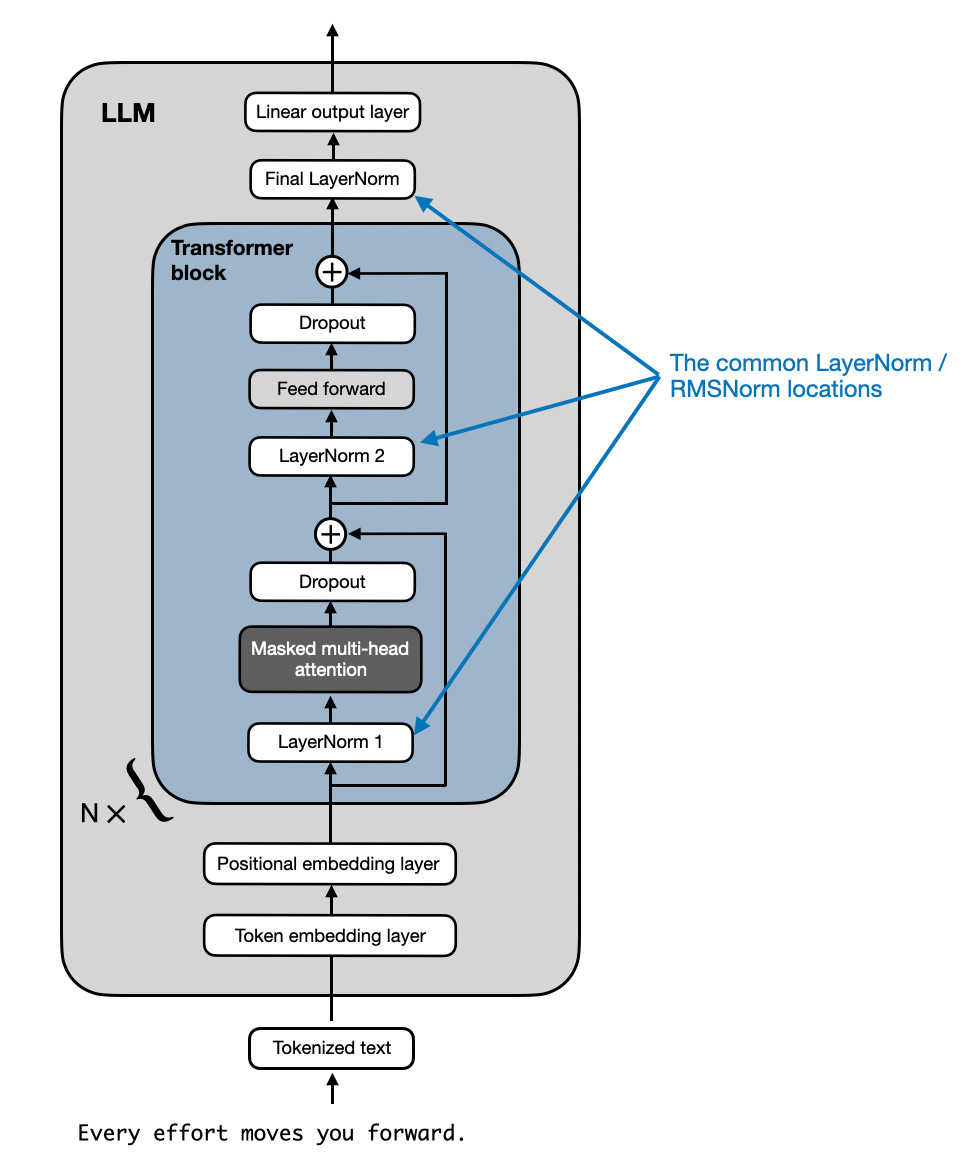
GeGLU Activations
One notable deviation from other architectures is that Gemma uses GeGLU activations, which was proposed in the 2020 paper GLU Variants Improve Transformer.
GeLU, or Gaussian Error Linear Unit, is an activation function that has become increasingly popular as an alternative to the traditional ReLU. The popularity of GeLU stems from its ability to introduce nonlinearity while also allowing for the propagation of gradients for negative input values, addressing one of the limitations of ReLU, which blocks negative values completely
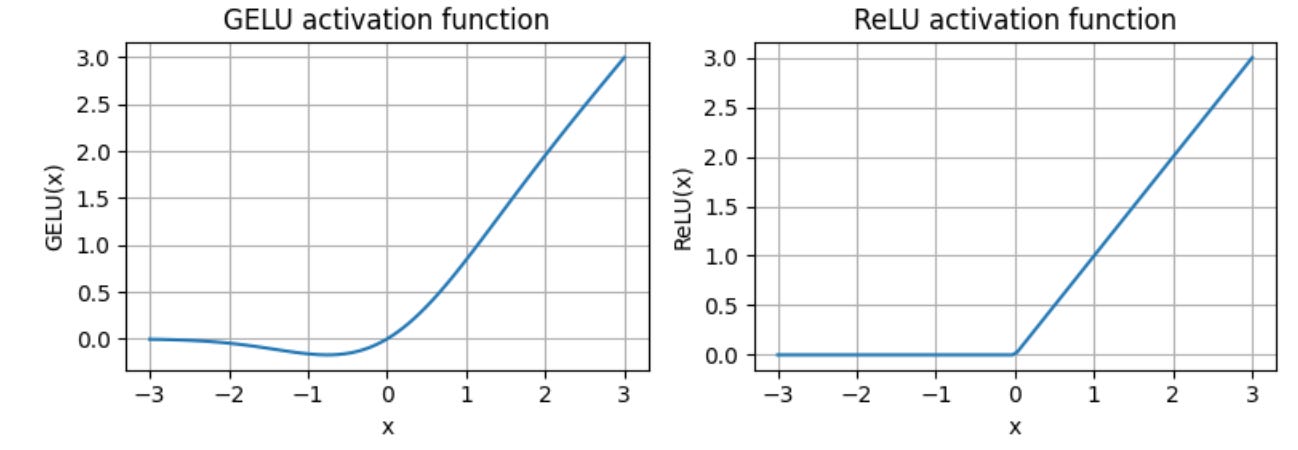
Now, GeGLU is a gated linear unit variant of GELU, where the activation is split into two parts, a sigmoidal part and a linear projection that is element-wise multiplied with the output of the first part, as illustrated below.

As illustrated above, GeGLU is analogous to SwiGLU activations used by other LLMs (for example, Llama 2 and Mistral), except that it uses GELU as the base activation rather than Swish.
This is perhaps easier to see when looking at the pseudo-code of these activations:
# Feedforward module with GELU (GPT-2)
x = linear(x)
x = gelu(x)
x = linear_projection(x)
# Feedforward module with SwiGLU (Llama 2)
x_1 = self.linear_1(x)
x_2 = self.linear_2(x)
x = silu(x_1) * x_2
x = linear_projection(x)
# Feedforward module with GeGLU (Gemma)
x_1 = self.linear_1(x)
x_2 = self.linear_2(x)
x = gelu(x_1) * x_2
x = linear_projection(x)
Note that feedforward modules with SwiGLU and GeGLU effectively have one more linear layer (linear_1 and linear_2) compared to the regular feedforward module with GeLU (only linear). However, in GeGLU and SwiGLU feedforward modules, the linear_1 and linear_2 are typically obtained by splitting a single linear layer into two parts so that it doesn’t necessarily increase the parameter size.
Is GeGLU better than SwiGLU? There are no ablation studies to say for sure. I suspect the choice could have also been just to make Gemma slightly more different from Llama 2.
4.4 Other Design Choices
Moreover, when adding Gemma support for Lit-GPT, Andrei Aksionov found some other interesting design choices.
For instance, Gemma adds an offset of +1 to the RMSNorm layers and normalizes the embeddings by the square root of the hidden layer dimension. The latter is also done in the original Attention Is All You Need Transformer but not in other models like GPT-2 or OLMo, which also use weight tying.

These details are not mentioned or discussed in the paper, and the significance of this is not clear.
A potential explanation that comes to mind is that while linear layers and embedding layers do the same thing (see my write-up on Embedding Layers and Linear Layers), the initial weights are on a different scale. And since researchers at Google preferred TensorFlow for their experiments, multiplying by the square root of the embedding dimension was perhaps a way to bring the weights onto a more reasonable scale as I am showing in the example code below.
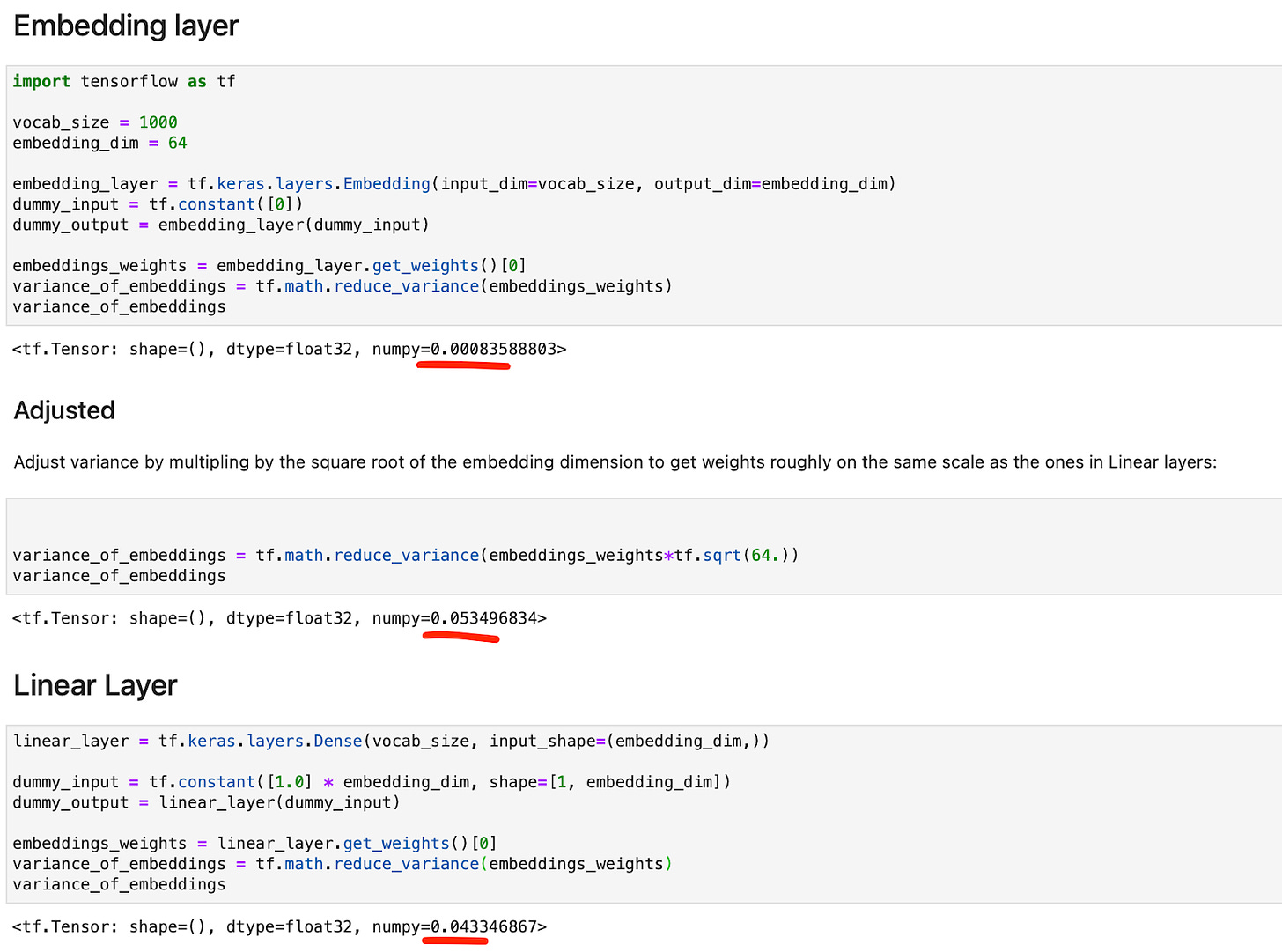
4.5 Conclusion
Gemma is a nice contribution to the openly-available LLM collection. It appears that the 7B model is a very strong model that could potentially replace Llama 2 and Mistral in real-world use cases.
In addition, since we already have a large collection of ~7B models openly available, the Gemma 2B is almost more interesting as it comfortably runs on a single GPU. It’ll be interesting to see how it compares to phi-2, which is 2.7B in size as well.
If you want to use Gemma in practice via the aforementioned Lit-GPT implementation, I created a Studio environment here.
Other Interesting Research Papers In February
Below is a selection of other interesting papers I stumbled upon this month. Given the length of this list, I highlighted those 10 I found particularly interesting with an asterisk (*). However, please note that this list and its annotations are purely based on my interests and relevance to my own projects.
Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models by De, Smith, Fernando et al. (29 Feb), https://arxiv.org/abs/2402.19427
- The paper introduces Hawk and Griffin, a recurrent neural network LLM and a LLM hybrid architecture that combines recurrent neural network elements with local attention to present new efficient alternatives to transformer-based LLMs.
When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method by Zhang, Liu, Cherry, and Firat (27 Feb), https://arxiv.org/abs/2402.17193
- This study systematically explores how scaling factors like model size, pretraining data size, finetuning parameter size, and finetuning data size influence finetuning performance in large LLMs, comparing full-model tuning with parameter-efficient tuning (including prompt tuning and LoRA) in scenarios where LLM size exceeds finetuning data size.
Sora Generates Videos with Stunning Geometrical Consistency by Li, Zhou, Zhang et al. (27 Feb), https://arxiv.org/abs/2402.17403
- This paper introduces a benchmark for evaluating the Sora model’s video generation fidelity to real-world physics by transforming generated videos into 3D models and using the accuracy of 3D reconstruction as a metric to assess adherence to physical principles and find that Sora compares very favorably to other text-to-video models like Pika.
(*) The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits by Ma, Wang, Ma et al. (27 Feb), https://arxiv.org/abs/2402.17764
- This research introduces a 1-bit LLM variant (only supporting values -1, 0, and 1) that matches LLMs with the conventional 16-bit precision in perplexity and downstream-task performance during inference.
Genie: Generative Interactive Environments by Bruce, Dennis, Edwards et al. (23 Feb), https://arxiv.org/abs/2402.15391
- Genie is a pioneering 11B-parameter generative interactive environment (based on spatiotemporal transformers), trained unsupervised from internet videos, that enables the creation of endlessly variable, action-controllable virtual worlds from text, images, and sketches.
(*) Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs by Ahmadian, Cremer, Galle, et al. (22 Feb), https://arxiv.org/abs/2402.14740
- This research suggests that simpler REINFORCE-style optimization methods are more efficient and effective than Proximal Policy Optimization (PPO) for AI alignment in large language models through Reinforcement Learning from Human Feedback (RLHF),
TinyLLaVA: A Framework of Small-scale Large Multimodal Models by Zhou, Hu, Weng, et al. (22 Feb), https://arxiv.org/abs/2402.14289
- The TinyLLaVA framework demonstrates that small Large Multimodal Models (LMMs), using high-quality data and optimized training, can match or outperform larger models, with its best model, TinyLLaVA-3.1B, surpassing existing 7B models.
Large Language Models for Data Annotation: A Survey by Tan, Beigi, Wang et al. (21 Feb), https://arxiv.org/abs/2402.13446
- This paper explores the potential of Large Language Models (LLMs) like GPT-4 to automate the labor-intensive process of data annotation, focusing on their application in data annotation, evaluation of LLM-generated annotations, and learning from these annotations.
(*) LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens by Ding, Zhang, Zhang, et al. (21 Feb), https://arxiv.org/abs/2402.13753
- LongRoPE is a new approach that extends the context window of pre-trained LLMs to 2,048,000 tokens with minimal finetuning, maintaining performance across context sizes through improvements in positional interpolation and a progressive extension strategy.
YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information by Wang, Yeh, and Liao (21 Feb), https://arxiv.org/abs/2402.13616
- This research proposes solutions to the information bottleneck and unsuitability of deep supervision mechanisms and proposes YOLOv9 with improved efficiency and performance over YOLOv8 on the MS COCO dataset.
Neural Network Diffusion by Wang, Xu, Zhou, et al. (20 Feb), https://arxiv.org/abs/2402.13144
- This study showcases how diffusion models, traditionally used for image and video generation, can be applied to generate high-performing neural network parameters.
(*) LoRA+: Efficient Low Rank Adaptation of Large Models by Hayou, Ghosh, and Yu (Feb 19), https://arxiv.org/abs/2402.12354
- The paper introduces LoRA+, an improvement over the original Low Rank Adaptation (LoRA) method, by using different learning rates for adapter matrices A and B to enhance feature learning, resulting in 1-2% performance gains and up to 2x faster finetuning without extra computational cost.
Towards Cross-Tokenizer Distillation: the Universal Logit Distillation Loss for LLMs by Boizard, Haddad, Hudelot, and Colombo (19 Feb), https://arxiv.org/abs/2402.12030
- The paper introduces Universal Logit Distillation loss, enabling effective knowledge distillation across large language models with different architectures and tokenizers, overcoming the shared tokenizer limitation.
AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling by Zhan, Dai, Ye, and Zhou (19 Feb), https://arxiv.org/abs/2402.12226
- AnyGPT is a multimodal language model that seamlessly integrates speech, text, images, and music through discrete representations, enabling versatile any-to-any multimodal interactions without altering the core architecture of large language models.
(*) Reformatted Alignment by Fan, Li, Zou, and Li (19 Feb), https://arxiv.org/abs/2402.12219
- The paper introduces ReAlign, a method for enhancing the quality of finetuning data for large language models (LLMs) to better align with human values through a simple reformatting approach.
LongAgent: Scaling Language Models to 128k Context through Multi-Agent Collaboration by Zhao, Zu, Xu, et al (18 Feb), https://arxiv.org/abs/2402.11550
- LongAgent improves LLMs’ long-text processing through multi-agent collaboration and an inter-member communication mechanism, outperforming models like GPT-4 in tasks like text retrieval and multi-hop question answering.
Vision-Flan: Scaling Human-Labeled Tasks in Visual Instruction Tuning by Xu, Feng, Shao, et al. (2024), https://arxiv.org/abs/2402.11690
- The study introduces Vision-Flan, a diverse visual instruction tuning dataset, and a two-stage instruction tuning framework for vision-language models, which addresses issues like poor generalizability and bias by combining expert and GPT-4 synthesized data.
OneBit: Towards Extremely Low-bit Large Language Models by Xu, Han, Yang, et al. (17 Feb), https://arxiv.org/abs/2402.11295
- The paper presents OneBit, a 1-bit quantization-aware training framework for LLMs, achieving significant storage and computational efficiency with minimal performance loss, through new parameter representation and initialization methods.
FinTral: A Family of GPT-4 Level Multimodal Financial Large Language Modelsby Bhatia, Nagoudi, Cavusoglu, and Abdul-Mageed (16 Feb), https://arxiv.org/abs/2402.10986
- FinTral is multimodal LLM suite optimized for financial analysis, built on Mistral-7b and enhanced with domain-specific training and benchmarks, outperforming ChatGPT-3.5 and GPT-4 in key tasks – a nice case study for AI for finance.
Generative Representational Instruction Tuning by Muennighoff, Su, Wang, et al. (15 Feb), https://arxiv.org/abs/2402.09906
- GRIT is a new training approach that enables an LLM, GritLM, to excel in both generative and embedding tasks by following instructions.
Recovering the Pre-Fine-Tuning Weights of Generative Models by Horwitz, Kahana, and Hoshen (15 Feb), https://arxiv.org/abs/2402.10208
- The paper introduces Spectral DeTuning, which is able to recover pre-finetuning weights from finetuned models in large-scale models like Stable Diffusion and Mistral.
BASE TTS: Lessons From Building a Billion-Parameter Text-to-Speech Model on 100K Hours of Data by Lajszczak, Cambara, Li, at al. (15 Feb), https://arxiv.org/abs/2402.08093
- BASE TTS is a new text-to-speech model by Amazon researchers that achieves unprecedented speech naturalness by training on 100K hours of data with a billion-parameter transformer architecture.
Transformers Can Achieve Length Generalization But Not Robustly by Zhou, Alon, Chen, et al. (14 Feb) https://arxiv.org/abs/2402.09371
- This paper explores the challenge of length generalization in language models, demonstrating that standard Transformers can extrapolate to sequence lengths 2.5 times their training input using specific data formats and position encodings, although this ability is highly sensitive to factors such as weight initialization and data order.
(*) DoRA: Weight-Decomposed Low-Rank Adaptation by Liu, Wang, Yin et al. (14 Feb), https://arxiv.org/abs/2402.09353
- DoRA is an improvement over standard low-rank adaption (LoRA) that bridges the accuracy gap between parameter-efficient finetuning methods like LoRA and full finetuning by decomposing pre-trained weights into magnitude and direction for more effective updates.
Mixtures of Experts Unlock Parameter Scaling for Deep RL by Obando-Ceron, Sokar, Willi, et al. (13 Feb), https://arxiv.org/abs/2402.08609
- This paper shows that integrating Mixture-of-Expert (MoE) modules, especially Soft MoEs, into value-based networks for reinforcement learning leads to models that scale more effectively with size, suggesting a pathway towards establishing scaling laws in reinforcement learning domains.
World Model on Million-Length Video And Language With RingAttention by Liu, Yan, Zaharia, and Abbeel (13 Feb), https://arxiv.org/abs/2402.08268
- This work proposes the training of neural networks on massive datasets of long video and language sequences using recent techniques like RingAttention.
Suppressing Pink Elephants with Direct Principle Feedback (12 Feb), https://arxiv.org/abs/2402.07896
- This research introduces Direct Principle Feedback (DPF) as a new approach to adjust LLMs’ responses in real-time, showcasing its capabilities on the Pink Elephant Problem by successfully directing the model to avoid specific topics.
Step-On-Feet Tuning: Scaling Self-Alignment of LLMs via Bootstrapping Wang, Ma, Meng, et al. (12 Feb), https://arxiv.org/abs/2402.07610
- The study explores multi-time bootstrapping self-alignment in LLMs via Step-On-Feet Tuning (SOFT), which improves model performance by utilizing iterative alignment and optimized training sequences compared to single-step methods.
Aya Model: An Instruction Finetuned Open-Access Multilingual Language Model by Ustun, Aryabumi, Yong, et al. (12 Feb), https://arxiv.org/abs/2402.07610
- The research introduces Aya, a multilingual generative language model proficient in 101 languages.
Scaling Laws for Fine-Grained Mixture of Experts by Jakub Krajewski, Jan Ludziejewski, Kamil Adamczewski, et al. (12 Feb), https://arxiv.org/abs/2402.07871
- This work explores the scaling properties of Mixture of Experts (MoE) models, introducing “granularity” as a new hyperparameter for finetuning the expert size, and showing the superiority of MoE models over dense transformers.
Policy Improvement using Language Feedback Models by Zhong, Misra, Yuan, and Cote (12 Feb), https://arxiv.org/abs/2402.07876
- Language Feedback Models (LFMs) improve imitation learning by using feedback from LLMs on verbalized visual trajectories, outperforming traditional methods in task completion and adapting to new environments, with the added benefit of providing human-interpretable feedback for verifying desirable behaviors.
ODIN: Disentangled Reward Mitigates Hacking in RLHF by Chen, Zhu, Soselia et al. (11 Feb), https://arxiv.org/abs/2402.07319
- The research addresses reward hacking in LLMs by developing a nuanced evaluation protocol and an improved reward model that jointly trains two heads to prioritize content over length, significantly reducing length bias and enhancing policy outcomes.
The Boundary of Neural Network Trainability is Fractal by Dickstein (9 Feb), https://arxiv.org/abs/2402.06184
- The study uncovers fractal-like boundaries in neural network training, emphasizing the extreme sensitivity of training dynamics to minor hyperparameter adjustments, across a wide range of configurations and scales.
Buffer Overflow in Mixture of Experts by Hayes, Shumailov, and Yona (8 Feb), https://arxiv.org/abs/2402.05526
- This research shows that Mixture of Experts (MoE) models are susceptible to attacks via expert routing strategies with cross-batch dependencies, where malicious queries can influence the output of benign queries within the same batch.
Direct Language Model Alignment from Online AI Feedback by Guo, Zhang, Liu, et al. (7 Feb), https://arxiv.org/abs/2402.04792
- This paper proposes an online feedback method for model training that surpasses Direct Alignment from Preferences (DAP) methods like DPO, and RLHF, by using real-time evaluations from an LLM.
Grandmaster-Level Chess Without Search by Ruoss, Deletang, and Medapati (7 Feb), https://arxiv.org/abs/2402.04494
- This paper by Google Deepmind presents a “small” 270M parameter transformer model trained on 10 million chess games and surpassing AlphaZero’s networks and GPT-3.5-turbo-instruct in chess performance.
Self-Discover: Large Language Models Self-Compose Reasoning Structures by Zhou, Pujara, Ren, et al. (6 Feb), https://arxiv.org/abs/2402.03620
- SELF-DISCOVER enables LLMs to autonomously create reasoning strategies, improving their problem-solving abilities with notable efficiency and cross-model applicability, which may be closer aligned to human reasoning.
Vision Superalignment: Weak-to-Strong Generalization for Vision Foundation Models by Guo, Chen, Wang et al. (6 Feb), https://arxiv.org/abs/2402.03749
- This paper explores weak-to-strong generalization in vision foundation models through an adaptive confidence loss for knowledge distillation, showing that weaker models can effectively enhance stronger ones, marking a significant advancement in AI capabilities for visual tasks.
MOMENT: A Family of Open Time-series Foundation Models by Goswami, Szafer, Choudhry, et al. (6 Feb), https://arxiv.org/abs/2402.03885
- MOMENT introduces a new approach to general-purpose time-series analysis with open-source foundation models, addressing challenges such as the lack of a cohesive time-series dataset and the complexity of multi-dataset training by creating the Time-series Pile and designing benchmarks for evaluating models in low-supervision settings.
Scaling Laws for Downstream Task Performance of Large Language Models by Isik, Ponomareva, Hazimeh, et al. (6 Feb), https://arxiv.org/abs/2402.04177
- This research explores how the size and relevance of pretraining data affect machine translation performance in LLMs, finding that alignment improves outcomes, while misalignment can cause inconsistent results.
A Phase Transition Between Positional and Semantic Learning in a Solvable Model of Dot-Product Attention by Cui, Behrens, Krzakala, and Zdeborova (6 Feb), https://arxiv.org/abs/2402.03902
- This research explores how dot-product attention layers learn to focus on position or meaning within data, revealing that with enough data, these layers can outperform linear models by transitioning from positional to semantic attention mechanisms.
MobileVLM V2: Faster and Stronger Baseline for Vision Language Model by Chu, Qiao, Zhang et al. (6 Feb), https://arxiv.org/abs/2402.03766
- MobileVLM V2 introduces small and efficient vision language models that outperform larger models with the 1.7B version matching or surpassing 3B scale models and the 3B version exceeding those at the 7B+ scale.
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models by Shao, Wang, Zhu et al. (5 Feb), https://arxiv.org/abs/2402.03300)
- DeepSeekMath 7B, an LLM pretrained on 120B math-related tokens, achieves a 51.7% score on the MATH benchmark by leveraging web data and introducing Group Relative Policy Optimization (an alternative for PPO) for mathematical reasoning, nearing the performance of leading models like Gemini-Ultra and GPT-4.
More Agents Is All You Need by Li, Zhang, Yu, Fu, and Ye (3 Feb), https://arxiv.org/abs/2402.05120
- This study shows that LLM performance can be scaled up by using a simple majority voting ensemble method across multiple LLMs, with improvements that complement existing methods and are more pronounced in harder tasks.
FindingEmo: An Image Dataset for Emotion Recognition in the Wild by Mertens, Yargholi, Op de Beeck at el. (2 Feb), https://arxiv.org/abs/2402.01355
- FindingEmo is a new dataset with 25k images annotated for emotion recognition, focusing on complex, multi-person scenes in naturalistic settings, with data and source code openly shared.
(*) LiPO: Listwise Preference Optimization through Learning-to-Rank by Liu, Qin, Wu, et al. (2 Feb), https://arxiv.org/abs/2402.01878
- This work introduces Listwise Preference Optimization (LiPO) for aligning LLMs with human feedback by treating alignment as a listwise ranking problem, showing LiPO outperforms current policy optimization methods like DPO.
(*) Repeat After Me: Transformers are Better than State Space Models at Copying by Jelassi, Brandfonbrener, Kakade, and Malach (1 Feb), https://arxiv.org/abs/2402.01032
- This paper demonstrates that while State Space Models offer inference-time efficiency, they fall short of transformers on tasks requiring input context copying, due to GSSMs’ inherent limitations from their fixed-size latent state,
(*) Tiny Titans: Can Smaller Large Language Models Punch Above Their Weight in the Real World for Meeting Summarization? by Fu, Laskar, Khasanonva et al. (Feb 1), https://arxiv.org/abs/2402.00841
- This study finds that compact Large Language Models like FLAN-T5 can match or surpass larger models in efficiency and performance for specific tasks like meeting summarization, which has its utility in being a cost-effective alternative for deployment.
(*) OLMo: Accelerating the Science of Language Models by Groeneveld, Beltagy, Walsh, et al. (1 Feb), https://arxiv.org/abs/2402.00838
- This technical report introduces OLMo, a fully open LLM, along with its complete framework including training data, and training and evaluation code.
Efficient Exploration for LLMs by by Dwaracherla, Asghari, Hao, and Van Roy (1 Feb), https://arxiv.org/abs/2402.00396
- This research paper demonstrates that efficiently exploring different ways to generate queries for human feedback can substantially improve the performance of LLMs with fewer queries by continuously refining a reward model based on the feedback received.
Machine Learning Q and AI
I am very excited that Machine Learning Q and AI is finally coming out, and I just received my author copies this week.
If you’ve been on the hunt for the next resource to improve your understanding of machine learning and AI concepts, Machine Learning Q and AI introduces intermediate to advanced concepts in an accessible way.

This blog is a personal passion project that does not offer direct compensation. If you want to support me with these efforts, I’d appreciate it if you’d consider purchasing a copy of my book.