Machine Learning with PyTorch and Scikit-Learn
-- The *new* Python Machine Learning Book
Machine Learning with PyTorch and Scikit-Learn has been a long time in the making, and I am excited to finally get to talk about the release of my new book. Initially, this project started as the 4th edition of Python Machine Learning. However, we made so many changes to the book that we thought it deserved a new title to reflect that. So, what’s new, you may wonder? In this post, I am excited to tell you all about it.

How this book is structured
Before I start diving into the exciting parts, let me give you a brief tour and tell you how the book is structured. Overall, this book is a comprehensive introduction to machine learning. This includes “traditional” machine learning – that is, machine learning without neural networks – and deep learning.
The first ten chapters introduce you to machine learning with scikit-learn, which is likely the most widely used machine learning library today. This book’s first part teaches you all the fundamental concepts surrounding machine learning, including preprocessing your data, model evaluation, and hyperparameter tuning.
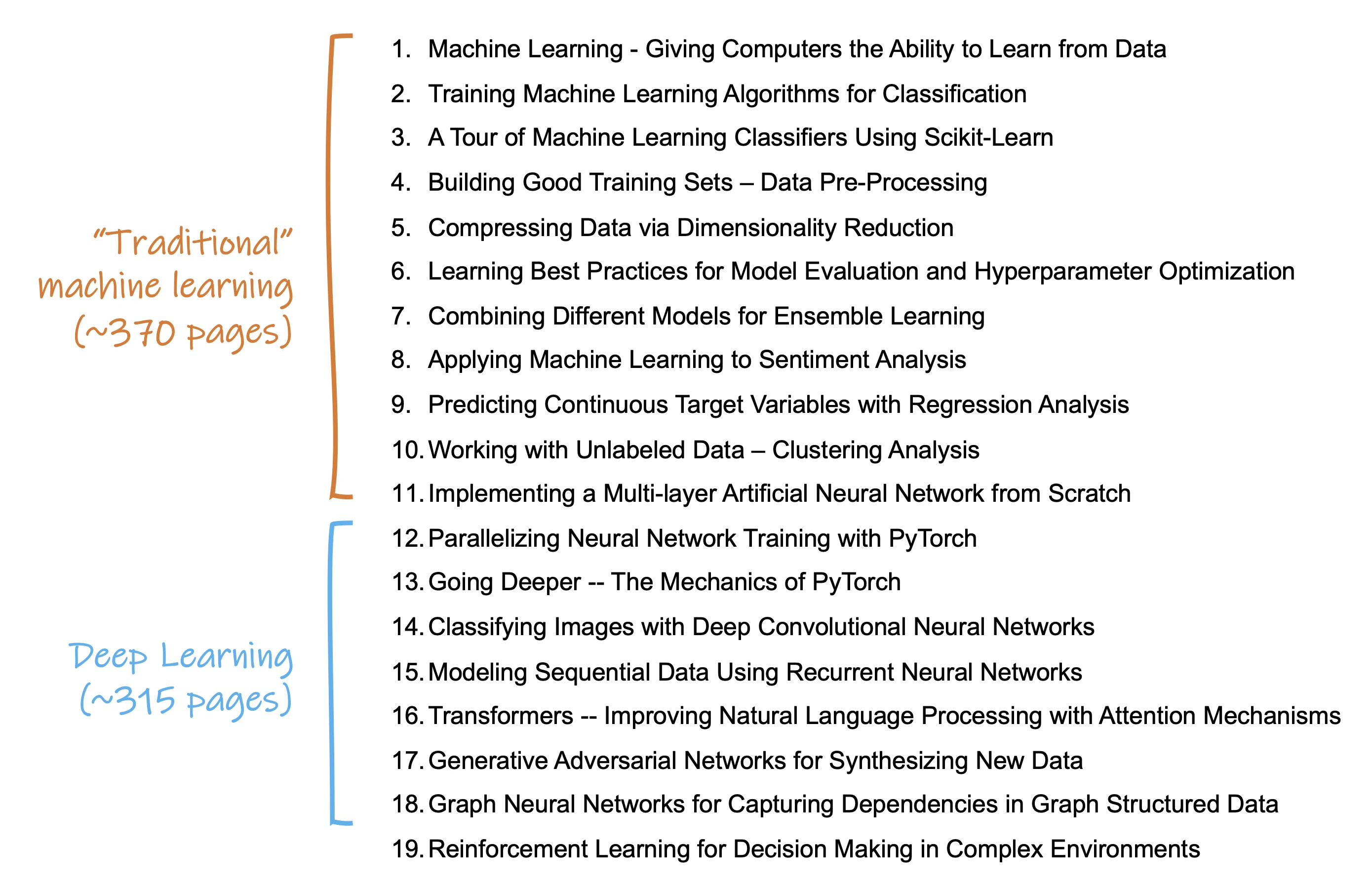
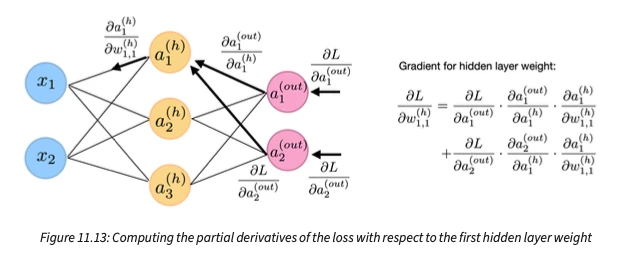
Chapter 11 is the turning point of this book. Here, I show you how we can implement a multilayer neural network from scratch in NumPy, and I’ll walk you through backpropagation – a popular and widely used algorithm for neural network training – step by step.
The second half of this book focuses on deep learning. Here, we cover topics such as classifying and generating images and text. There is also a chapter dealing with graph-structured data, which is an exciting direction as it broadens what you can do with deep learning. Lastly, this book closes with reinforcement learning, which is essentially its own subfield (but there is also a section using deep learning for this.)
Now, I should mention that this reflects the overall structure of Python Machine Learning, 3rd edition. However, I will tell you about several rewrites, expanded sections, and two brand new chapters in the following sections. With more than 770 pages in total, we also reached the limit in terms of how much content we can have and still having the possibility of a print version 😅.
Using PyTorch
As you may notice by reading the title, one of the big changes is that we transitioned the code example of the deep learning chapters from TensorFlow to PyTorch. This was a large undertaking, and I really appreciate Yuxi (Hayden) Liu helping me with that by taking the lead in this transition.
PyTorch was released on 2016, and it’s been four years since I fully adopted it for both research and teaching. What I love about PyTorch is that it is well-designed and very convenient to use, and at the same time, it is flexible enough so that I can readily customize it in my research projects.
But it’s actually not just me who likes using PyTorch. According to recent trends, PyTorch is used in about 60% of all code implementations among recent deep neural publications.
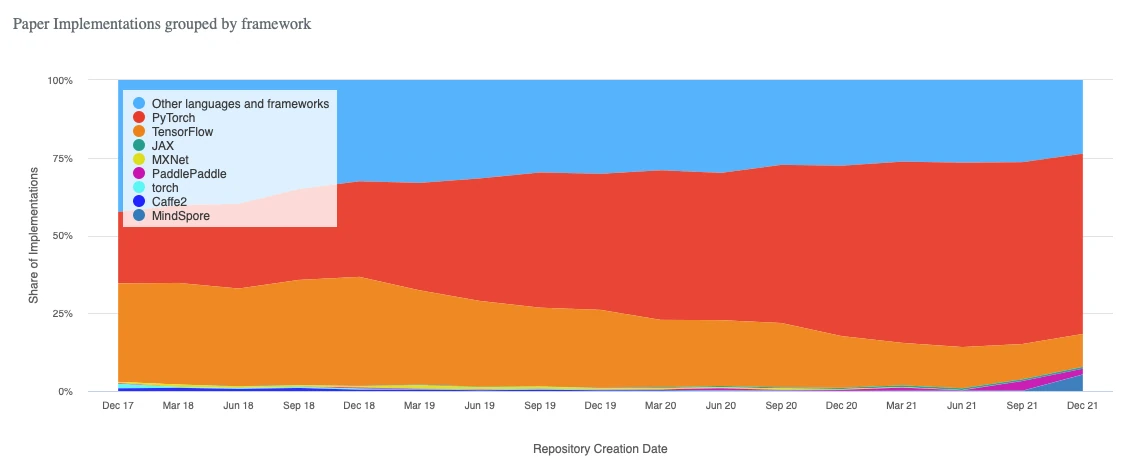
(Source: Papers with Code)
As a little bonus, I also added a section on using PyTorch Lightning, a library that helps organize your code and projects. Also, it makes many complicated aspects such as multi-GPU training so much easier. As I now work with the PyTorch Lightning team more closely, stay tuned for more PyTorch Lightning content as a follow-up in the future.
Whether you are entirely new to deep learning or have started your deep learning journey with another deep learning framework, I am sure you’ll enjoy working with PyTorch.
Transformers for natural language processing
As you may have heard, transformers are now the leading deep learning architecture for state-of-the-art natural language processing. And in this chapter, you will learn how transformers evolved from recurrent neural networks. We explain the self-attention mechanism step-by-step, leading up to the original transformer architecture. However, this chapter does not stop here.
We also cover the various GPT architectures (decoder-type transformers focused on generating texts) and BERT (encoder-type transformers focused on classifying text) and show you how to use these architectures in practice. No worries, you don’t need a supercomputer for that, as we show you how to adopt freely available, pre-trained models and fine-tune them on new tasks.
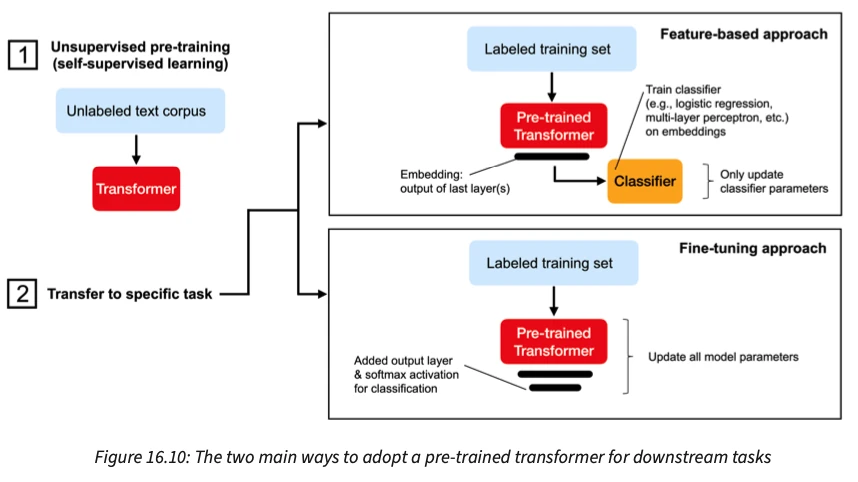
After teaching a very long lecture on transformers last year, I was very excited to write this new chapter. With great help from Jitian Zhao, we reorganized these contents and made them more accessible. I am particularly proud of the improved flow and the new figures, which help illustrate these concepts better.
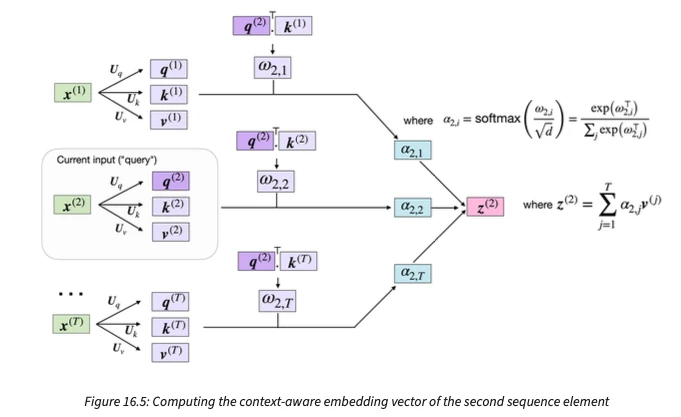
Graph neural networks
Based on the previous section, it might sounds like that transformers are getting all the limelight. However, I am similarly very excited about this second new chapter on graph neural networks. This topic is closely related to my research interests and an excitting new direction for deep learning.
What’s really cool about graph neural networks is that they allow us to work with graph-structured data (instead of tables, images, or text). For instance, several real-world problems present themselves as graphs, including social network graphs and graphs of molecules (chemicals).
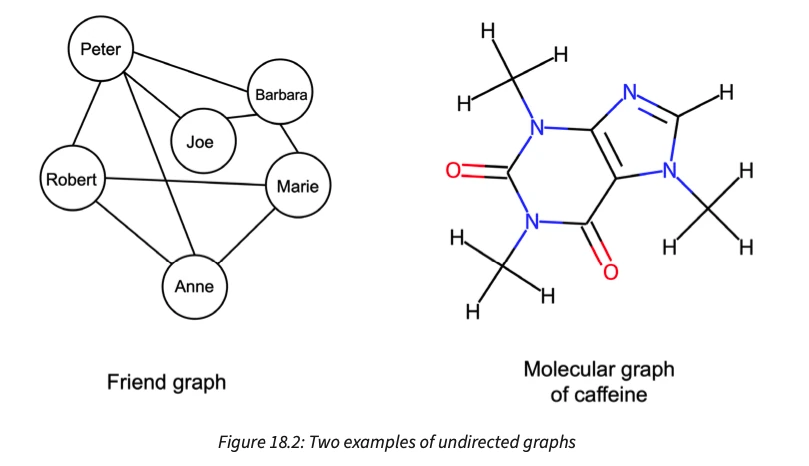
In this chapter, we explain how graph neural networks work one step at a time. This chapter starts by explaining how we can structure graphs as inputs to deep neural networks. Then we go over the motivation behind using graph convolutions, implement a graph neural network from scratch, and, finally, use PyTorch Geometric for a molecular property prediction task.
For this chapter, I had the pleasure of collaborating with Ben Kaufman, a Ph.D. student who I am currently co-advising. I am currently working on several exciting research projects with Ben, and I am grateful for his enthusiasm to lead the writing efforts on this chapter.
This chapter arose from our mutual interest in working with graph neural networks in the context of virtual screening – a computational procedure often used for bioactive molecule and (pharmaceutical) drug discovery. (If you are interested in more details about this topic, you might also like our comprehensive review article Machine Learning and AI-based Approaches for Bioactive Ligand Discovery and GPCR-ligand Recognition.)
A fresh new look
This is my fifth book with Packt (I often forget that I wrote a book on Heatmaps in R a long, long time ago), and I couldn’t be more excited about a fresh new layout! This new layout features slimmer margins (the only way to fit all the contents within the page limit) and comes with figure captions, which you can see in the screenshots of figures from the book above.
Most importantly, though, this new layout works better for the mathy portions of the book: the font size of mathematical symbols is now finally consistent.

Moreover, a bonus is that the book now supports syntax colors. I find that this can make certain codes much easier to read.

One slight caveat is that inline code comes with a dark background, which may make it a bit tricky for printing, but it may be more familiar to and preferred by the many coders who choose a dark background in their code editor or command line terminal.
Lastly, I should say that the print version is only available in grayscale to keep the book reasonably priced. I haven’t received a print copy yet and thus can’t include a picture of how it looks. However, I was reading my book on my black&white e-ink reader, and it seems to look just fine 😊.

Actually, due to being able to scribble on it without regrets, e-readers have recently become my favorite choice for reading books. Of course, if you prefer color, you can always consider a non-e-ink tablet or check out the book’s GitHub repository, where I uploaded all figures in color and embedded these in the Jupyter notebooks for easy reference.
What else has changed
Besides the two new chapters and transitioning all TensorFlow-based chapters over to PyTorch, there are also several changes in the first part of the book.
For instance, I rewrote chapter 11 – implementing a neural network from scratch – almost from scratch to offer a better explanation of backpropagation. And also other sections such as the logistic regression have been revamped. While I don’t want to numerate all the little changes, I was also revising several figures as shown below.
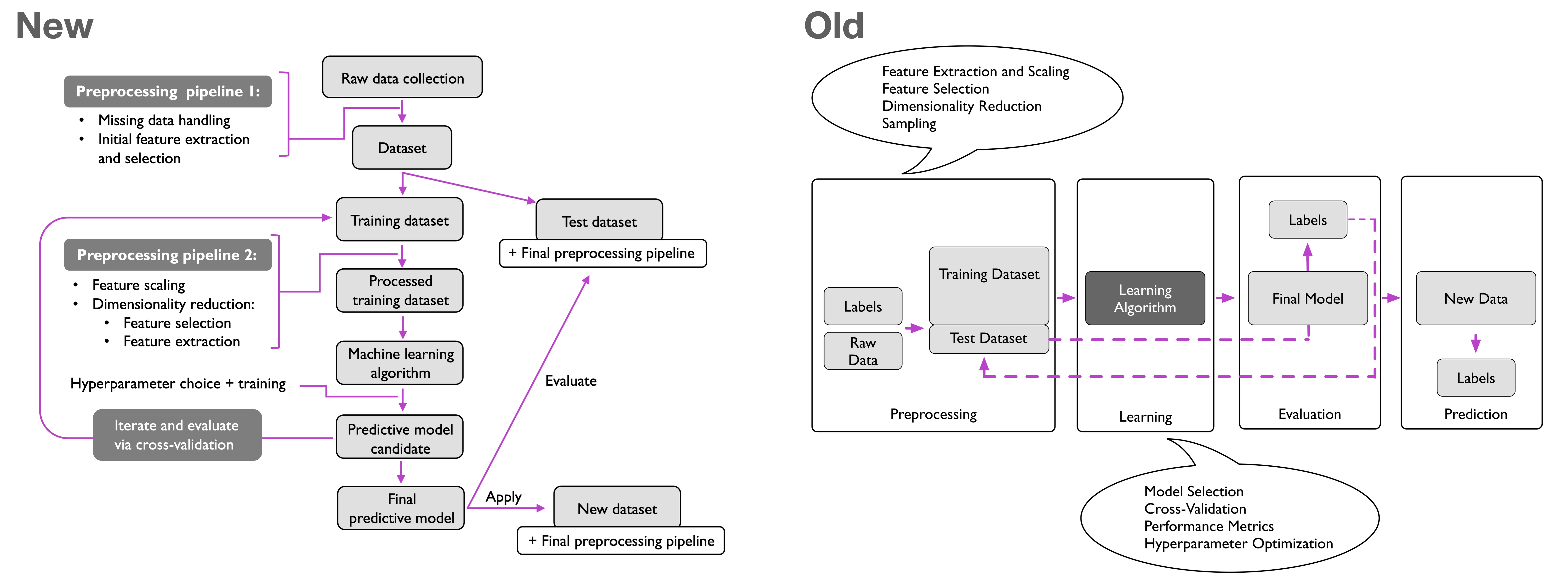
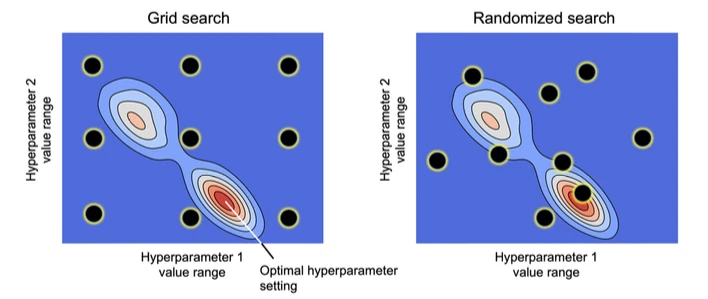
Overall, there are many small additions sprinkled throughout the book. Little things like PCA factor loadings or randomized search – relatively small things that are barely worth to mention, but they can have a large impact in practical applications.
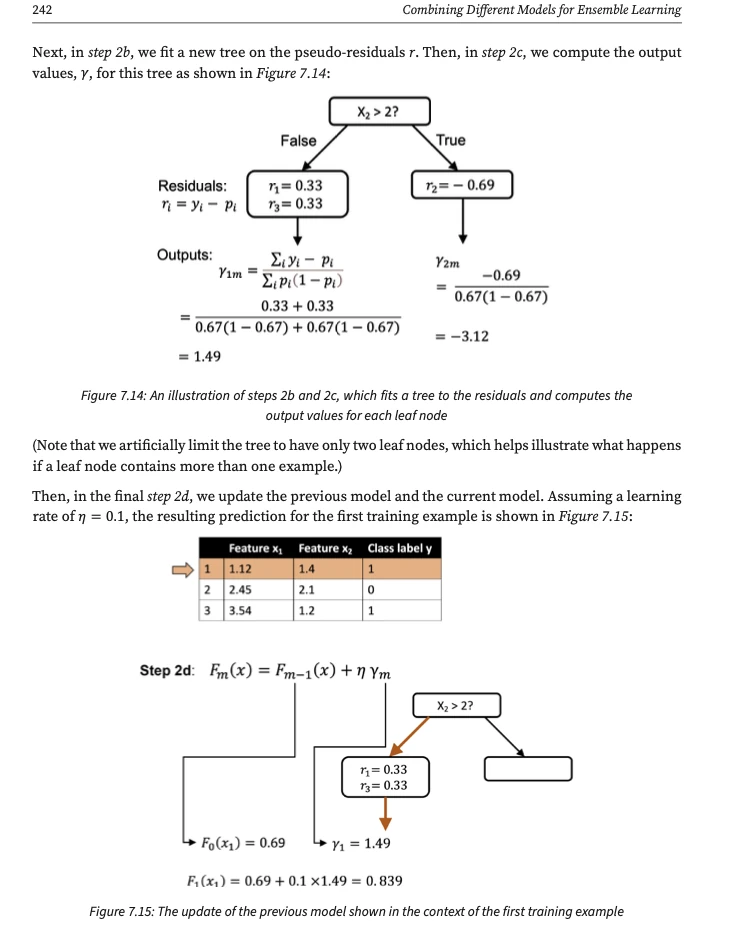
The most notable new section is a section explaining gradient boosting for classification. In my class, I usually explained gradient boosting with a regression example. That’s because it’s simpler and more convenient compared to classification. However, students asked me how it works for classification, and I liked the challenge of putting it down into writing. (And yes, I am glad you asked, there is a very concise coverage of XGBoost as well.)
(En)joy
Overall, I am very excited about this book. Since the first edition, I haven’t had so much fun working on a book project. I am glad that we finally made the switch to PyTorch – a tool that I use daily for research and my hobby projects. And working on the chapters about transformers and graph neural networks was very enjoyable.
Creating all that new content from scratch was a lot of work. You take notes, create a structure, make figures, and then eventually fill in the paragraphs one by one. It’s a lot of work, but that’s what I love 🤗.
I’d be happy to hear if you have any questions or feedback. Please feel free to reach out! The best place for that would be the Discussion forum (on GitHub).
I hope you’ll enjoy this book!
Links
Read Next
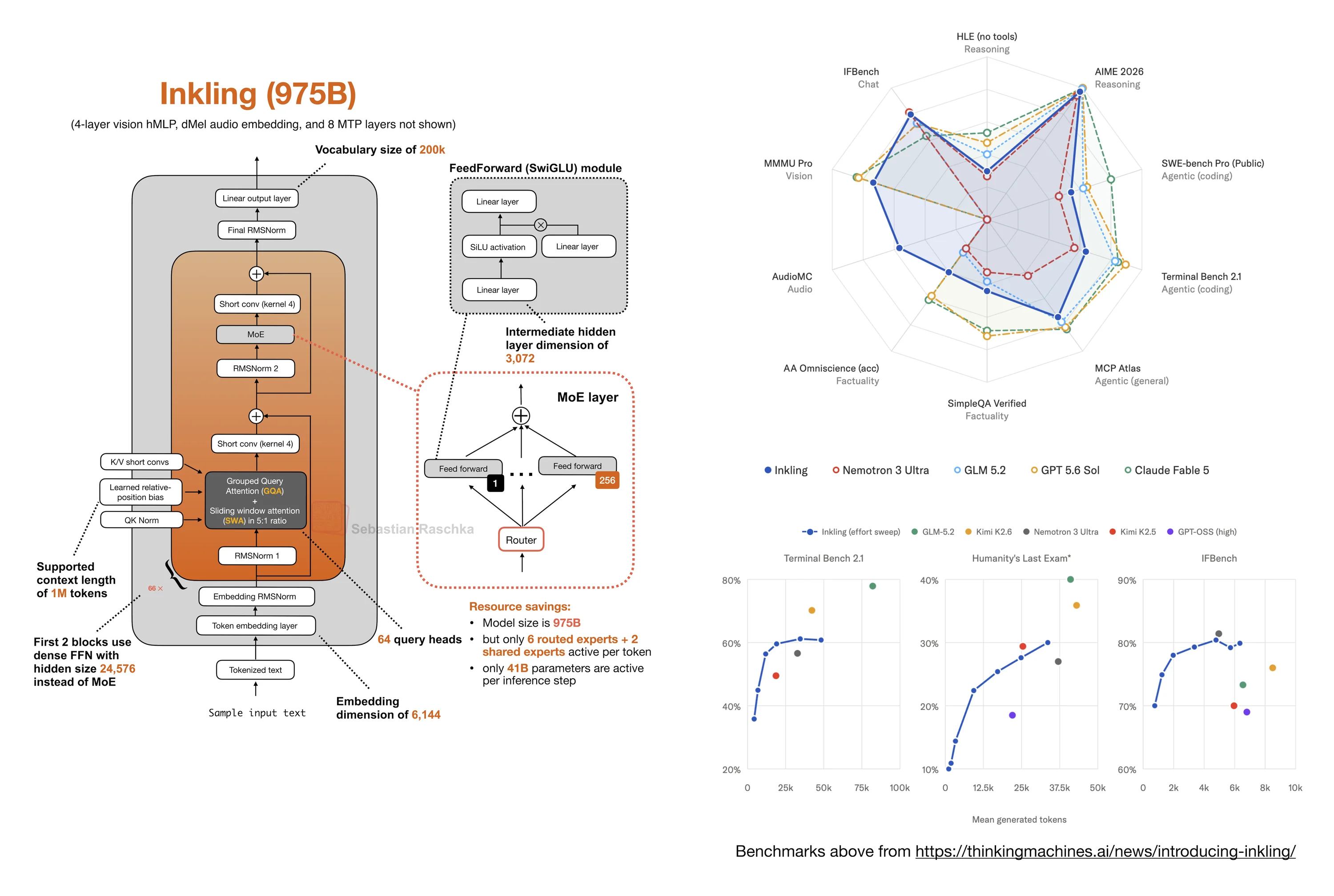 Inkling: A New Open-Weight 975B MoE with a Few Surprises
Short note on Thinking Machines Lab's 975B Inkling open-weight model, its benchmark profile, sparse MoE design, short convolutions, embedding RMSNorm, and
Inkling: A New Open-Weight 975B MoE with a Few Surprises
Short note on Thinking Machines Lab's 975B Inkling open-weight model, its benchmark profile, sparse MoE design, short convolutions, embedding RMSNorm, and
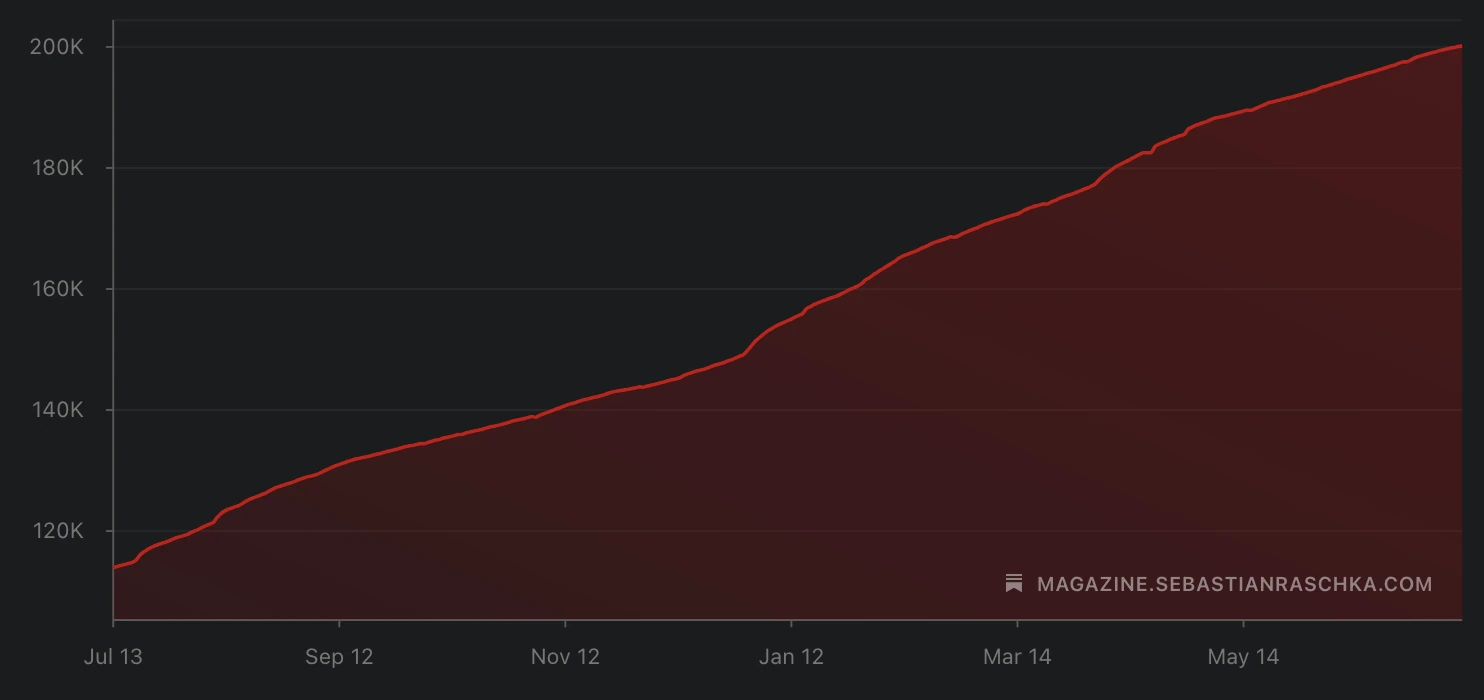 200,000 Subscribers
Short note celebrating Ahead of AI reaching 200,000 subscribers.
200,000 Subscribers
Short note celebrating Ahead of AI reaching 200,000 subscribers.
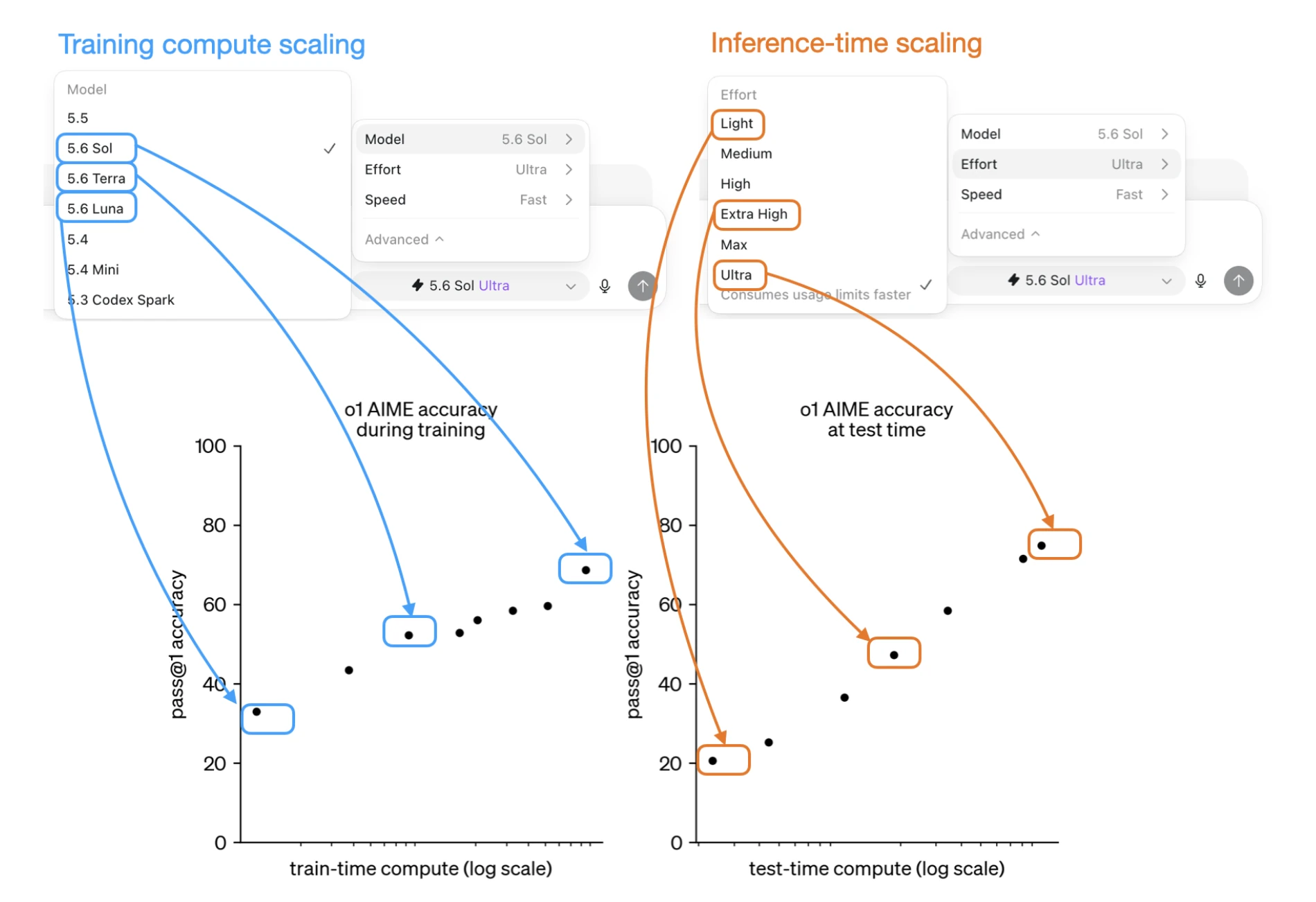 GPT 5.6 Has 72 Possible Configurations. What's A Good Default?
Short note on how GPT 5.6 model and effort choices map onto training-time and inference-time scaling, producing 72 configurations.
GPT 5.6 Has 72 Possible Configurations. What's A Good Default?
Short note on how GPT 5.6 model and effort choices map onto training-time and inference-time scaling, producing 72 configurations.

If you read the book and have a few minutes to spare, I'd really appreciate a brief review. It helps us authors a lot!
Your support means a great deal! Thank you!