Multi-Token Prediction (MTP)
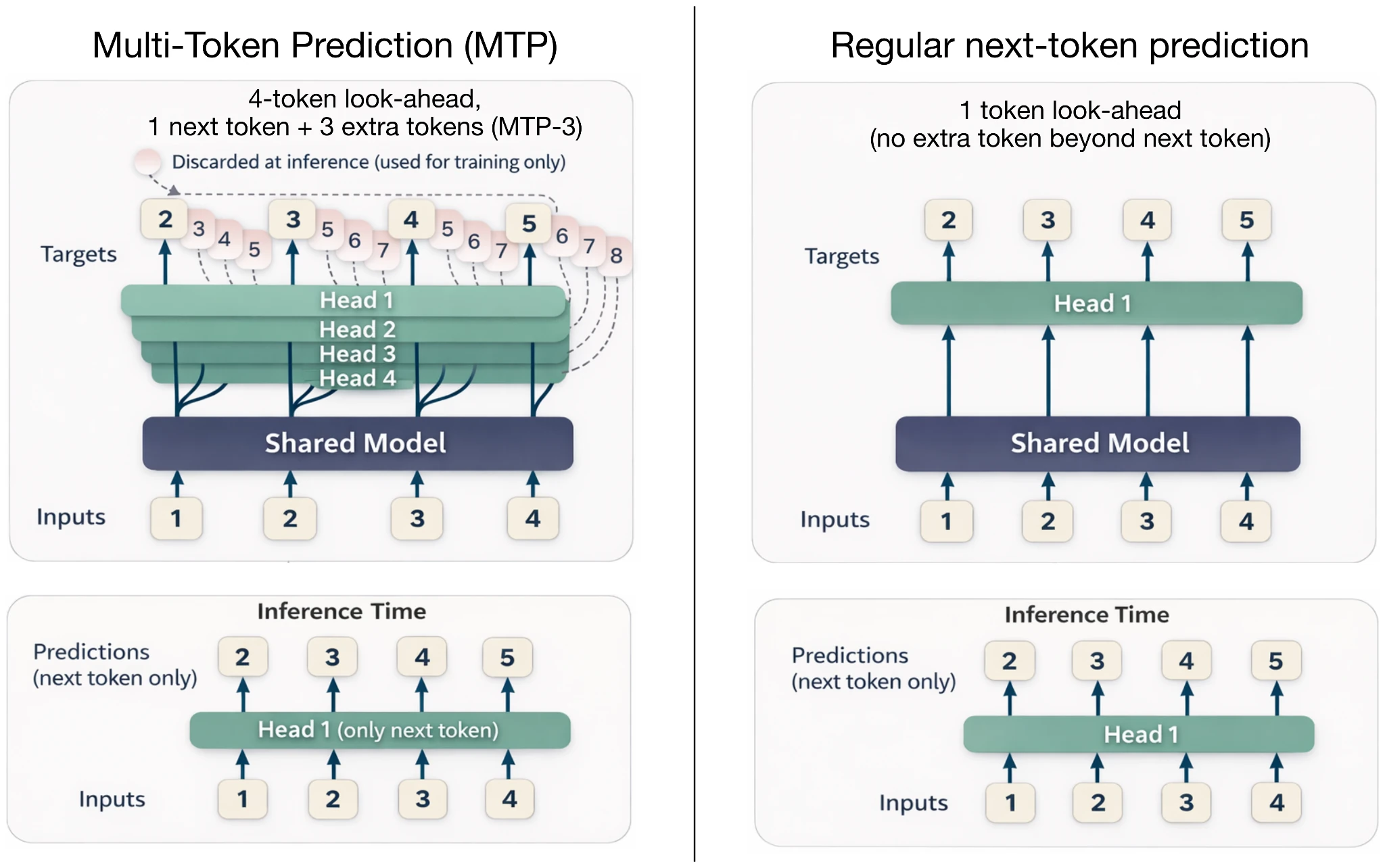
Multi-token prediction (MTP) extends the usual next-token training objective. Instead of asking the model to predict only the next token at each position, it also asks for several future offsets. The main decoder still reads the prefix in the usual autoregressive way, but small extra prediction heads or MTP modules add more supervision for future tokens.
What it optimizes
Training signal, speculative decoding, and sometimes inference throughput
Practical benefit
The model learns to anticipate more than one future token, and some releases reuse that machinery as a built-in draft path
Example architectures
DeepSeek V3, GLM-5 744B, Qwen3-Next 80B-A3B, Tencent Hy3-preview, Step 3.5 Flash 196B, Nemotron 3 Super 120B-A12B, MiniMax M2.7 230B, and Xiaomi MiMo-V2-Flash 309B.
From One Target To Several
Standard autoregressive language-model training predicts the next token. At position t, the model sees the prefix up to that point and learns to assign high probability to token t+1.
MTP keeps that setup but adds extra future-token targets. At the same position t, additional prediction heads can be trained for t+2, t+3, and so on. The losses for these offsets are combined with the usual next-token loss. In the original MTP paper, the authors recommended predicting four future tokens, but production models vary in how many offsets or MTP modules they use.
This is why MTP is easiest to understand as a training signal first. It gives each position more work to do and encourages the hidden state to encode information that is useful beyond the immediate next token.
Training Trick Or Inference Feature?
The first useful distinction is whether MTP is used only during training or also during inference.
DeepSeek V3 reported an MTP-1 setup, where the model predicts one extra token during training and can optionally use MTP during inference. In my Spring architecture article, Step 3.5 Flash was a more unusual case because it used MTP-3 during both training and inference.
More recent models use related ideas as native speculative-decoding support. Qwen3-Next describes an MTP mechanism that produces a high-acceptance MTP module for speculative decoding. Nemotron 3 Super is similar in spirit but uses a shared-weight MTP head as an internal draft model. During generation, that draft path proposes candidate continuation tokens, and the main model verifies them. This can reduce latency without requiring a separate external draft model.
Sources