Why can preference tuning improve style even when supervised finetuning already works?
Preference tuning can improve style even when supervised finetuning already works because supervised finetuning usually teaches the model to imitate a target answer, while preference tuning teaches it which kinds of answers people prefer among multiple acceptable possibilities.
That distinction matters because open-ended prompts rarely have only one good answer. A response can be correct but still differ in:
- tone
- brevity
- structure
- helpfulness
- level of detail

Supervised finetuning is still extremely useful. It gives the model the basic behavior of responding in the right format and domain. But it can only learn from the reference outputs it is shown.
Preference tuning adds a second layer: among several plausible outputs, push the model toward the ones humans prefer more often.
That is why preference tuning often improves things such as:
- response style
- refusal quality
- helpfulness
- verbosity control
- overall polish
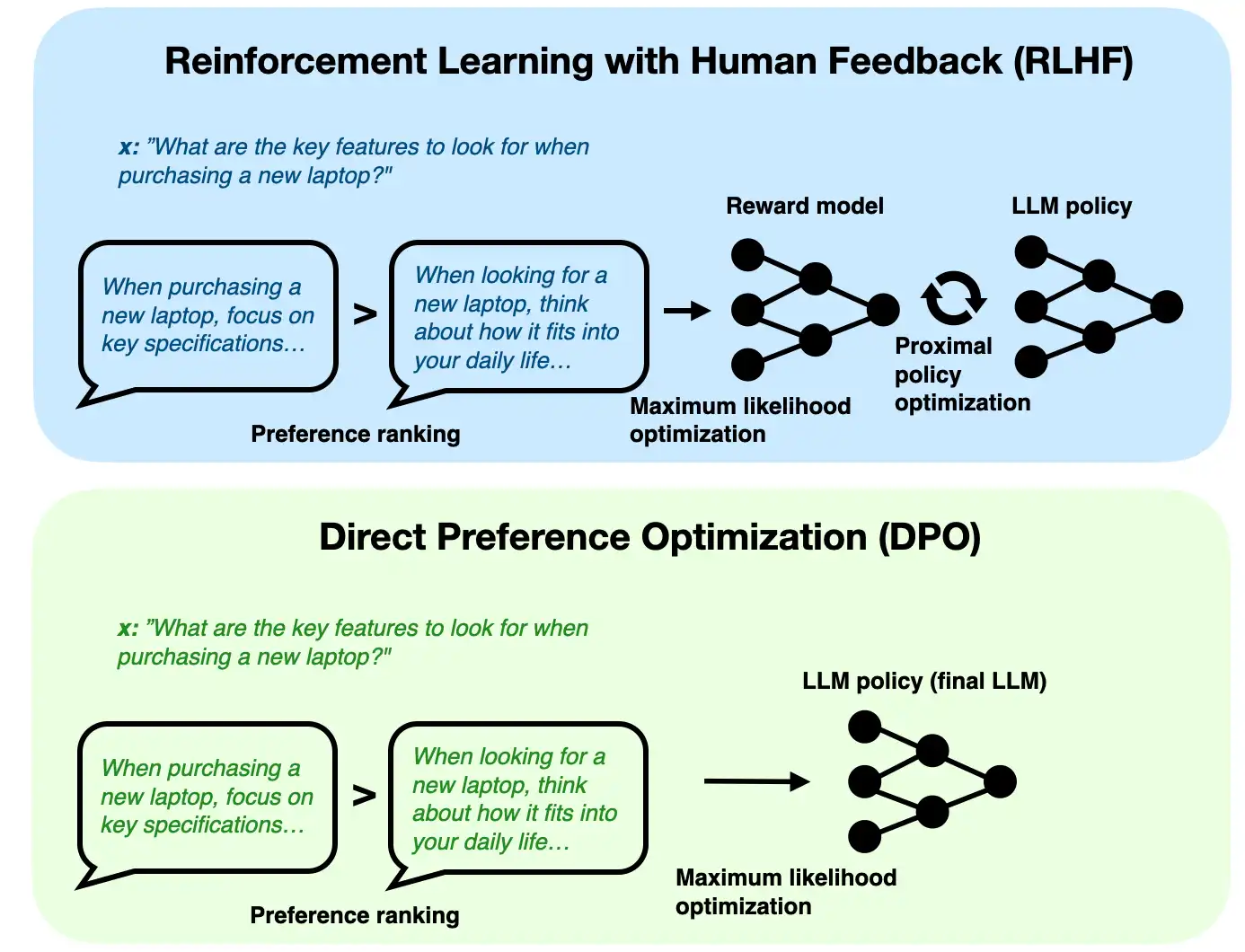
So supervised finetuning teaches “how to answer,” while preference tuning refines “which kind of answer is better.”
In short, preference tuning can improve style after supervised finetuning because it learns from chosen-versus-rejected response comparisons, which lets the model move beyond simple imitation toward behavior humans consistently prefer.