What makes LLM evaluation harder than classification evaluation?
LLM evaluation is harder than classification evaluation because classification usually has a fixed label set and a clear target, while LLM generation often has many acceptable answers.
In text classification, scoring is straightforward. The model picks a label, and you compare it with ground truth using metrics such as accuracy or F1.
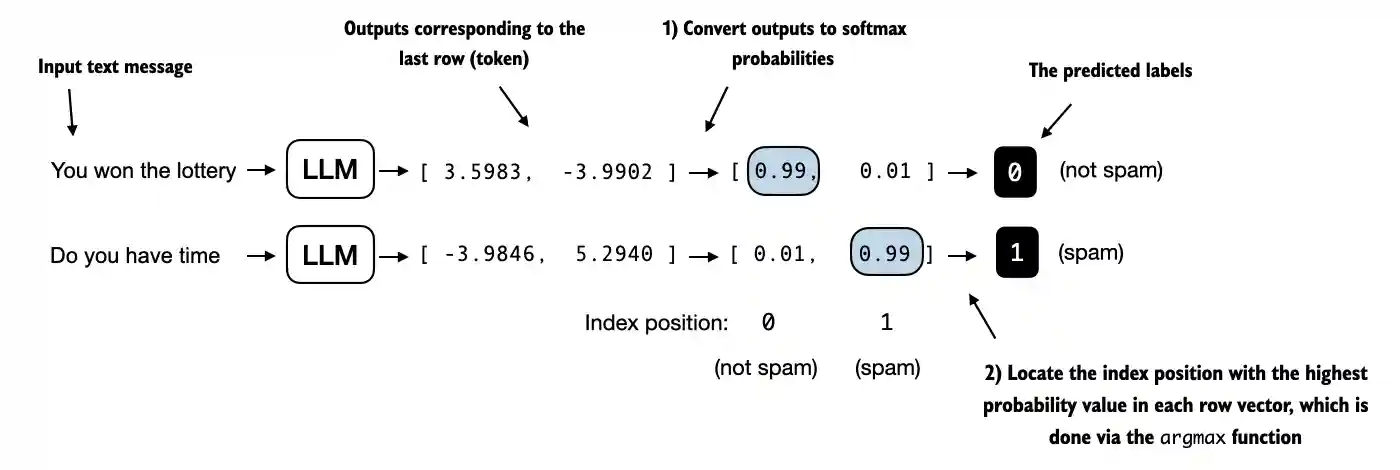
LLM outputs are different. A response can be:
- correct but phrased differently
- mostly correct but incomplete
- stylistically awkward but still useful
- fluent but factually wrong
That means there is usually no single simple metric that captures everything users care about.
This is why LLM evaluation often needs a mixture of:
- exact-match metrics for narrow tasks
- human judgment
- pairwise preference comparisons
- LLM-as-a-judge evaluation
The repo’s chapter 7 evaluation material explicitly includes a workflow where another model is used to judge generated responses.

So classification evaluation is simpler mainly because the task definition is simpler. Open-ended generation has richer behavior and therefore more ambiguous scoring.
In short, LLM evaluation is harder than classification evaluation because generated responses rarely have one uniquely correct label, so useful evaluation has to account for correctness, style, helpfulness, and instruction adherence at the same time.