Where should LoRA adapters be inserted in an LLM for the biggest impact?
LoRA adapters usually have the biggest impact when they are inserted into the model’s most important linear projections, especially the ones that strongly shape attention behavior and feed-forward transformations.
In practice, that usually means some combination of:
- attention projections such as query, key, value, and output projections
- large feed-forward projections in the MLP block
The reason is simple: these are the places where the model does most of its representation shaping.
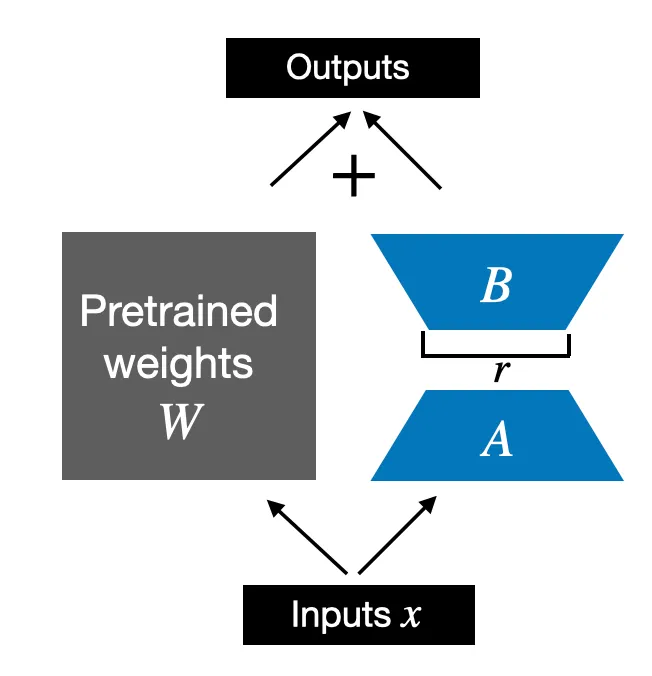
If you want the biggest effect for the smallest budget, many practitioners start with attention projections, often especially the query and value side. If the task requires deeper behavioral change, they then expand to more layers or to the feed-forward blocks.
The repo’s helper function goes even further and can recursively replace linear layers throughout the model with LoRA-wrapped versions.
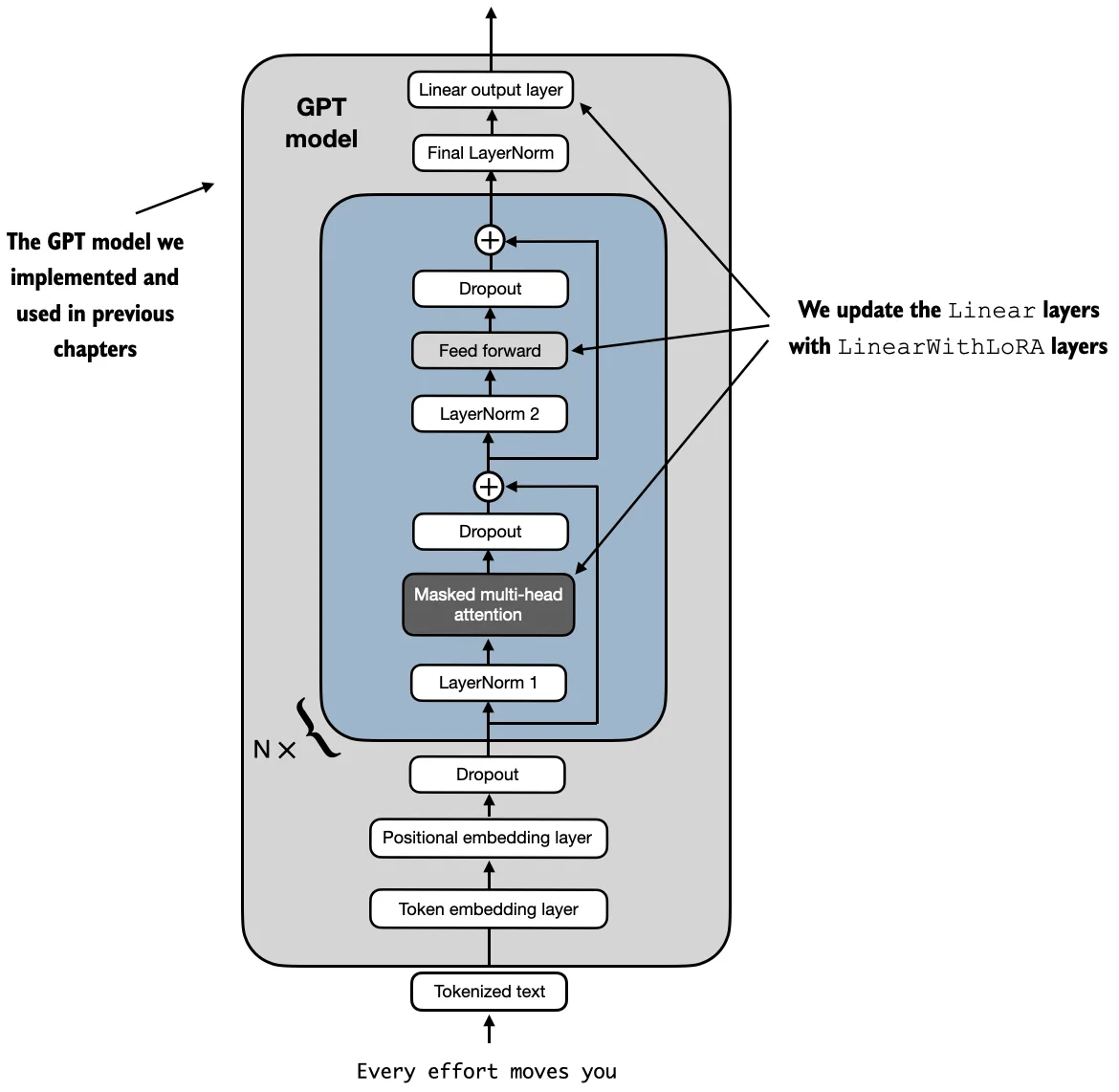
So there is no single universal answer. The best insertion pattern depends on:
- the task
- the model architecture
- how much VRAM and training budget you have
- whether you want a light touch or a broader adaptation
The practical rule is:
- start with high-leverage attention projections if you need efficiency
- expand into more attention and MLP layers if you need stronger adaptation
In short, LoRA adapters should usually be inserted into the model’s most influential linear layers, especially attention and feed-forward projections, because those are the places where a small trainable update can change behavior most effectively.